







 博主分享了一个小项目,通过编写Python 3.0的爬虫来提升动手能力。由于Python 3.0与2.0的差异,博主对原有的2.0版本爬虫代码进行了调整和修改,最终成功运行。
博主分享了一个小项目,通过编写Python 3.0的爬虫来提升动手能力。由于Python 3.0与2.0的差异,博主对原有的2.0版本爬虫代码进行了调整和修改,最终成功运行。
做个小项目练练手,比较有动力继续下去,这边参考最简单的爬虫程序自己抄了一下。但是因为3.0的关系,无法直接使用,根据2.0版本的代码进行修改后成功了。
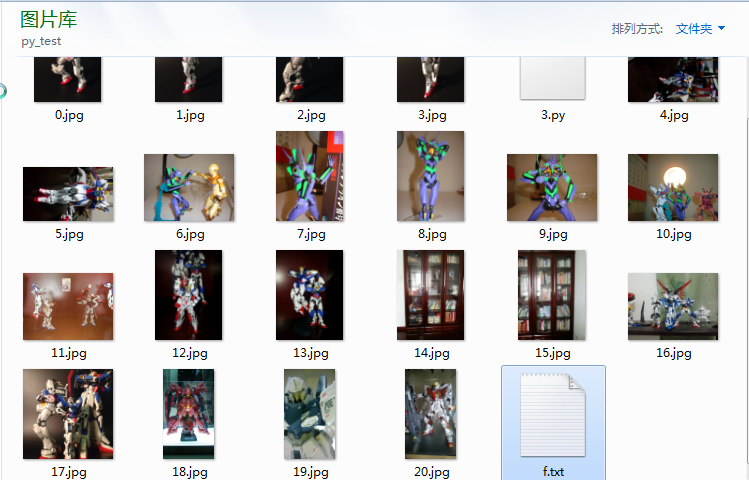
代码如下:
# -*- coding: utf-8 -*-
# 网上抄来的最简单的爬虫,用于批量下载图片
import urllib.request
import re
#该函数用于获取html内容
#使用到urlopen的函数
def getHtml(url):
page = urllib.request.urlopen(url)
#3.0直接使用read()函数会出现报错,提示是编码有问题。在后面加上编码就ok了。
html = page.read().decode("utf-8")
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6244
6244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









