







进程
定义:
进程是程序执行时的一个实例。
轻量级进程(LWP):
两个轻量级进程之间可以共享一些资源,诸如地址空间,同一打开文件集等来访问相同的应用程序结构集。只要其中一个修改共享资源,另一个就立即查看这种修改(同步情况下)。
线程 VS 轻量级进程:
轻量级进程能很好共享公共资源。同时,又不会在系统阻塞进程的时候,阻塞了线程,因为每个LWP都有内核独立调度。
线程组:
Linux 中实现线程组的方式是用多个轻量级进程构成的集合。线程组中有一个领头的线程叫做首领线程,线程组中的每个线程的PID号相同!也就是该组中第一个轻量级进程的PID。(因为每个线程都是一个LWP,所以有一个PID号)
标识一个进程 ——进程描述符
程序能够独立调度的每个执行上下文都必须拥有自己的进程描述符。Linux 的进程描述符保存在 task_struct中。
获取进程描述符
1如果该进程是当前CPU正在执行的进程
current宏得到。它等价于
ð current_thread_info()->task.
ð 产生的汇编如下
movl $oxffffe000, %ecx
andl %ecx, %ecx
movl (%ecx), p
理论推导:
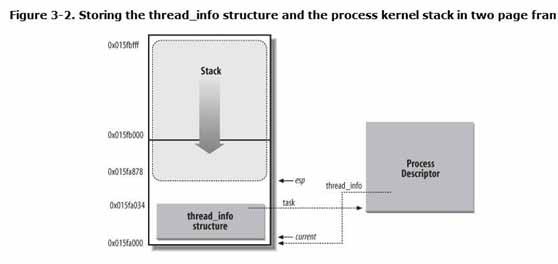
每个进程都有一个thread_info的结构体成员,这个结构体和内核堆栈一起分配在一个联合体内, thread_union。定义如下
union thead_union {
struct thread_info thread_info;
unsigned long stack[2048]; //内核堆栈
};
此结构体的大小是 2048 * 4,正好是2个页框(一个页框4K)大小。
CPU 的堆栈寄存器esp指向当前进程的堆栈。忽略掉低13位(8K)就是thread_info结构体的基地址。通过thread_info的成员task可以指向他的进程描述符地址。
current_thread_info() : 得到 thread_info的基地。
current_thread_info()->task : 得到当前进程描述符的地址。
2.寻找非当前运行进程
2.1 进程切换时,从TASK_RUNNING链表中寻找最合适的进程。
早期Linux的TASK_RUNNING链表是一个单循环链表,为了找到最佳可运行进程必须扫描整个链表!这样做是开销是非常大的。
Linux2.6实现的运行队列有所不同,他采取以空间换时间的策略,为每个优先级都分配一个链表头。这样就把长的链表切割成多个段链表。所有的这些链表都组装在一个结构体内,其结构如下:
struct prio_array_t{
intnr_active; //链表中进程描述符的数量
unsigned long bitmap[5]; //优先权位图:当且仅当某个优先权的进程链表不为
//空时设置相应的位标志为1
struct list_head[140]; //140个优先权队列的头结点
}
注:1. Linux的进程优先级从 0——139 ,共140个优先级。
2. 存储进程描述符的数据结构为什么不选择小根堆?
因为小根堆是数组操作,意味着这是静态的,因为Linux中最多有32767个(215-1)进程描述符,意味着你要一次申请 32767个 list_head。会造成极大的浪费。
3.Linux中最大的进程描述符数目为什么是32767?
因为Linux用pidmap_array位图来表示那些进程PID号已经使用,它分配在一个单独的页框中,一个页框是4K,能够表示的最大位数是 4 * 1024 * 8(位) = 215 = 32768.为什么会减1,没有弄太清楚,估计是init进程(swapper进程)作为0号进程占了一位吧?!
2.2通过PID号和 类型寻找进程描述符
首先通过PID号来查找一个进程描述符,不能像TASK_RUNNIN
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 349
349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









