






概率论是许多机器学习算法的基础,朴素贝叶斯就是基于概率来进行分类的方法。18世纪的一位神学家托马斯·贝叶斯率先引入先验知识和逻辑推理来处理不确定命题。
贝叶斯准则告诉我们如何较好条件概率中的条件与结果,即如果已知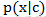
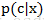
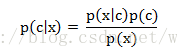
即有,使用贝叶斯准则,可以通过已知的三个概率来计算未知的概率值。
朴素贝叶斯的一般执行过程如下:
(1)收集数据
(2)准备数据:需要数值型或者布尔型数据。
(3)分析数据:有大量特征时,绘制特征作用不大,此时使用直方图效果更好。
(4)训练算法:计算不同独立特征的条件概率。
(5)测试算法:计算错误率。
(6)使用算法:可以在任意的分类场景中使用贝叶斯。
由统计学知,如果每个特征需要N个样本,那么对于10个特征将需要N^10个样本,所需样本数会随着特征数目增大而迅速增长。如果特征之间相互独立,那么样本数就可以从N^10减少到N*10。所谓的独立,指的是统计意义上的独立,即一个特征或单词出现的可能性与其它的各个单词无关。这也是朴素一词的含义。而且朴素贝叶斯分类器中的另一个假设是,每个特征同等重要。
下面是使用朴素贝叶斯算法进行垃圾邮件过滤的实例。
假设我们的邮件数据存储在文本中,那么下面开始解析文本数据:
def textParse(bigString):
import re
listOfTokens = re.split(r'\W*', bigString)
return [tok.lower() for tok in listOfTokens if len(tok) > 2]
该函数使用正则表达式按单词对字符串进行拆分,最后保存了长度大于2且被转换为小写的词汇使用情况。下面的函数根据文本中出现的单词的情况,得到不同词汇的集合:
def createVocabList(dataSet):
vocabSet = set([])
for document in dataSet:
vocabSet = vocabSet | set(document) #union of the two sets
return list(vocabSet)
下面的函数根据文本情况创建词汇向量:
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1
else: print "the word: %s is not in my Vocabulary!" % word
return returnVec
vocabList是前面我们得到的所有不同词汇的集合;inputSet是需要转换为词汇向量的单词列表。该函数返回了一个向量,其中的值都为0或1,表示词汇列表中某个词是否在该文本中出现。
使用朴素贝叶斯时,首先可以通过类别i(垃圾邮件或正常邮件)中文档数除以总的文档数来计算该类概率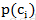
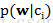
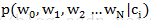
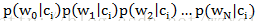
根据以上的分析,我们可以得到如下的初步分类器函数:
#函数的输入参数一次为:文档矩阵trainMatrix(存储各个词汇的出现情况)和每篇文档类别标签所构成的向量trainCategory(存储各篇文档的分类情况)
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix) #获取文档数
numWords = len(trainMatrix[0]) #需考虑地词汇数量
pAbusive = sum(trainCategory)/float(numTrainDocs)#侮辱性评论的百分比
#初始化相关参数-------1
p0Num = zeros(numWords); p1Num = zeros (numWords) #两个0向量
p0Denom = 0.0; p1Denom = 0.0
#循环查看每种分类中词汇的出现情况
for i in range(numTrainDocs):
if trainCategory[i] == 1:#为侮辱性文档
p1Num += trainMatrix[i] #计算各词汇出现次数
p1Denom += sum(trainMatrix[i])#累加文档的总词汇出现次数
else: #非侮辱性文档
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
#计算各种词汇的出现百分比-------2
p1Vect = p1Num/p1Denom #在NumPy中为向量的个元素都除以对应的数值
p0Vect = p0Num/p0Denom
return p0Vect,p1Vect,pAbusive
这就是我们得到的最初版本,但是它存在以下的问题。首先,如果我们在计算概率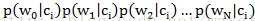
p0Num = ones(numWords); p1Num = ones (numWords) #两个1向量
p0Denom = 2.0; p1Denom = 2.0
另一个问题是下溢出,这是由于太多很小的数相乘所造成的。在计算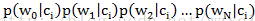
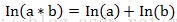
p1Vect = log(p1Num/p1Denom)
p0Vect = log(p0Num/p0Denom)
最终的分类训练器函数如下:
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCategory)/float(numTrainDocs)
p0Num = ones(numWords); p1Num = ones(numWords) #change to ones()
p0Denom = 2.0; p1Denom = 2.0 #change to 2.0
for i in range(numTrainDocs):
if trainCategory[i] == 1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = log(p1Num/p1Denom) #change to log()
p0Vect = log(p0Num/p0Denom) #change to log()
return p0Vect,p1Vect,pAbusive
完成训练步骤之后就是执行分类操作了,具体的实现代码比较简单,如下:
#输入参数依次为:待分类的文档词汇向量;0类各词汇出现概率的训练结果;1类各词汇出现概率的训练结果;1类出现的概率。
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
#我们在计算p0Vec和p1Vec时都是取了对数的,这里用sum其实就相当于在不取对数时的乘法操作
p1 = sum(vec2Classify * p1Vec) + log(pClass1)
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
函数中分别计算了输入向量所对应文档属于1类和0类的概率,其中sum(vec2Classify * piVec)代表的是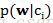
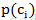














 451
451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









