









一、增加列
数据仓库最常碰到的扩展是给一个已经存在的维度表和事实表添加列。本节说明如何在客户维度表和销售订单事实表上添加列,并在新列上应用SCD2,以及对定时装载脚本所做的修改。假设需要在客户维度中增加送货地址属性,并在销售订单事实表中增加数量度量值。
先看一下增加列时模式发生的变化。
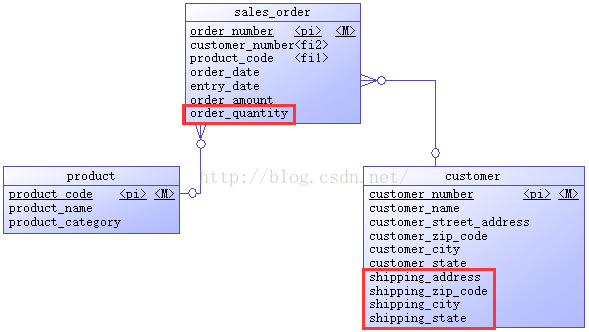
修改后源数据库模式如下图所示。
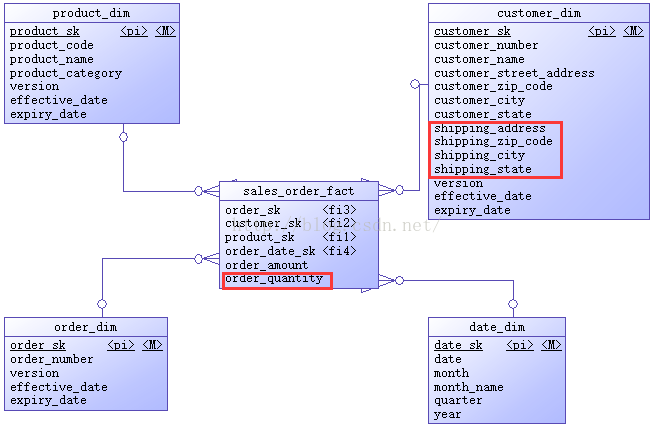
修改后DW数据库模式如下图所示。
1. 修改数据库模式
使用下面的SQL脚本修改源数据库模式。
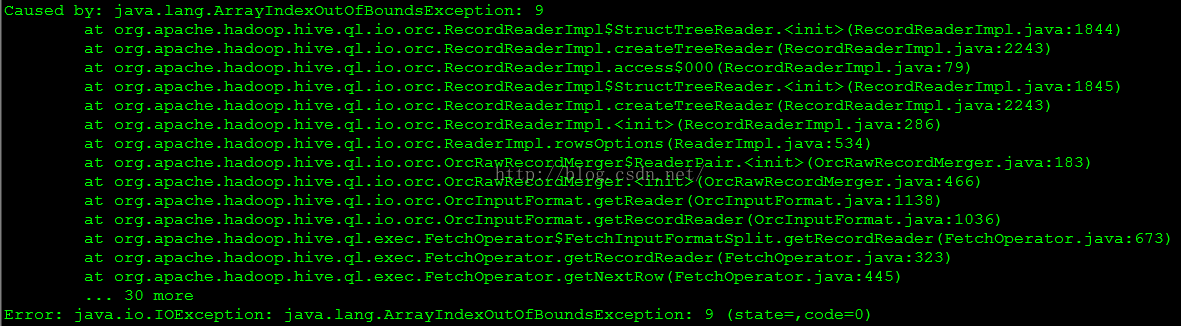 这个例子是在Hive1.1.0上执行的,jira上说2.0.0修复了ORC表模式修改的问题,可以参考以下链接的说明:
https://issues.apache.org/jira/browse/HIVE-11981
这个例子是在Hive1.1.0上执行的,jira上说2.0.0修复了ORC表模式修改的问题,可以参考以下链接的说明:
https://issues.apache.org/jira/browse/HIVE-11981
注意,在低版本的Hive上修改ORC表的模式,特别是增加列时一定要慎重。当数据量很大时,这会是一个相当费时并会占用大量空间的操作。
2. 重建Sqoop作业
使用下面的脚本重建Sqoop作业,增加order_quantity列。
3. 修改定期装载regular_etl.sql文件
修改数据库模式后,还要修改已经使用的定期装载HiveQL脚本。修改后的脚本如下所示。
4. 测试
(1)执行下面的SQL脚本准备客户和销售订单测试数据。
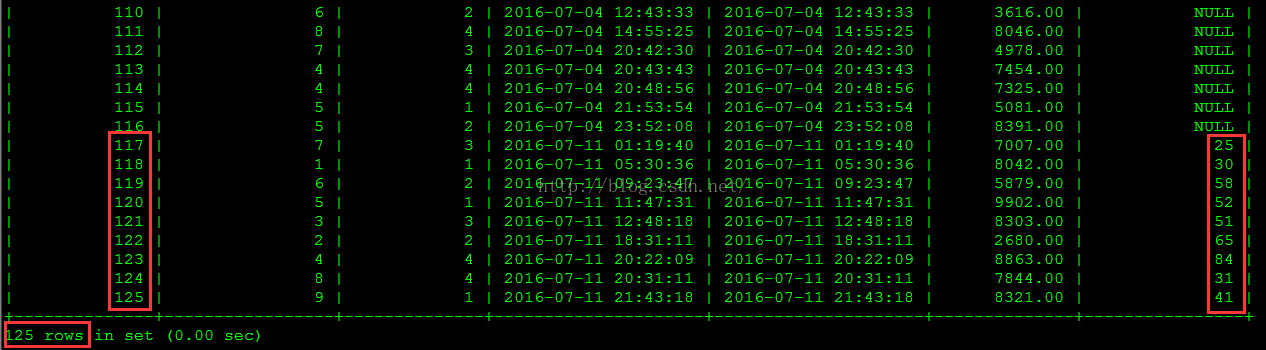
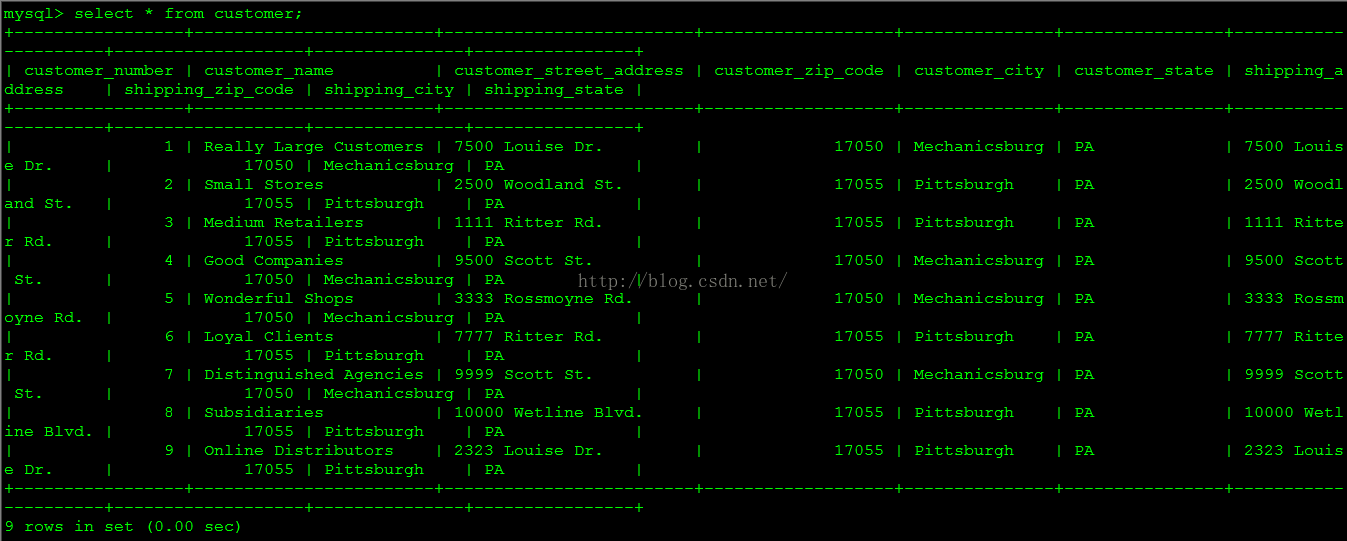 修改后的销售订单源数据如下图所示。
修改后的销售订单源数据如下图所示。
(2)执行定期装载并查看结果。
使用下面的命令执行定期装载。
至此,增加列所需的修改已完成。
数据仓库最常碰到的扩展是给一个已经存在的维度表和事实表添加列。本节说明如何在客户维度表和销售订单事实表上添加列,并在新列上应用SCD2,以及对定时装载脚本所做的修改。假设需要在客户维度中增加送货地址属性,并在销售订单事实表中增加数量度量值。
先看一下增加列时模式发生的变化。
修改后源数据库模式如下图所示。
修改后DW数据库模式如下图所示。
1. 修改数据库模式
使用下面的SQL脚本修改源数据库模式。
USE source;
ALTER TABLE customer
ADD shipping_address VARCHAR(50) AFTER customer_state
, ADD shipping_zip_code INT AFTER shipping_address
, ADD shipping_city VARCHAR(30) AFTER shipping_zip_code
, ADD shipping_state VARCHAR(2) AFTER shipping_city ;
ALTER TABLE sales_order
ADD order_quantity INT AFTER order_amount ; USE rds;
ALTER TABLE customer ADD COLUMNS
(shipping_address VARCHAR(50) COMMENT 'shipping_address'
, shipping_zip_code INT COMMENT 'shipping_zip_code'
, shipping_city VARCHAR(30) COMMENT 'shipping_city'
, shipping_state VARCHAR(2) COMMENT 'shipping_state') ;
ALTER TABLE sales_order ADD COLUMNS
(order_quantity INT COMMENT 'order_quantity') ; USE dw;
-- 修改客户维度表
ALTER TABLE customer_dim RENAME TO customer_dim_old;
CREATE TABLE customer_dim (
customer_sk INT comment 'surrogate key',
customer_number INT comment 'number',
customer_name VARCHAR(50) comment 'name',
customer_street_address VARCHAR(50) comment 'address',
customer_zip_code INT comment 'zipcode',
customer_city VARCHAR(30) comment 'city',
customer_state VARCHAR(2) comment 'state',
shipping_address VARCHAR(50) COMMENT 'shipping_address',
shipping_zip_code INT COMMENT 'shipping_zip_code',
shipping_city VARCHAR(30) COMMENT 'shipping_city',
shipping_state VARCHAR(2) COMMENT 'shipping_state',
version INT comment 'version',
effective_date DATE comment 'effective date',
expiry_date DATE comment 'expiry date'
)
CLUSTERED BY (customer_sk) INTO 8 BUCKETS
STORED AS ORC TBLPROPERTIES ('transactional'='true');
INSERT INTO customer_dim
SELECT customer_sk,
customer_number,
customer_name,
customer_street_address,
customer_zip_code,
customer_city,
customer_state,
NULL,
NULL,
NULL,
NULL,
version,
effective_date,
expiry_date
FROM customer_dim_old;
DROP TABLE customer_dim_old;
-- 修改销售订单事实表
ALTER TABLE sales_order_fact RENAME TO sales_order_fact_old;
CREATE TABLE sales_order_fact (
order_sk INT comment 'order surrogate key',
customer_sk INT comment 'customer surrogate key',
product_sk INT comment 'product surrogate key',
order_date_sk INT comment 'date surrogate key',
order_amount DECIMAL(10 , 2 ) comment 'order amount',
order_quantity INT COMMENT 'order_quantity'
)
CLUSTERED BY (order_sk) INTO 8 BUCKETS
STORED AS ORC TBLPROPERTIES ('transactional'='true');
INSERT INTO sales_order_fact SELECT *,NULL FROM sales_order_fact_old;
DROP TABLE sales_order_fact_old;use test;
drop table if exists t1;
create table t1(c1 int, c2 string)
clustered by (c1) into 8 buckets
stored as orc TBLPROPERTIES ('transactional'='true');
insert into t1 values (1,'aaa');
alter table t1 add columns (c3 string) ;
update t1 set c2='ccc' where c1=1;
select * from t1; 注意,在低版本的Hive上修改ORC表的模式,特别是增加列时一定要慎重。当数据量很大时,这会是一个相当费时并会占用大量空间的操作。
2. 重建Sqoop作业
使用下面的脚本重建Sqoop作业,增加order_quantity列。
last_value=`sqoop job --show myjob_incremental_import --meta-connect jdbc:hsqldb:hsql://cdh2:16000/sqoop | grep incremental.last.value | awk '{print $3}'`
sqoop job --delete myjob_incremental_import --meta-connect jdbc:hsqldb:hsql://cdh2:16000/sqoop
sqoop job \
--meta-connect jdbc:hsqldb:hsql://cdh2:16000/sqoop \
--create myjob_incremental_import \
-- \
import \
--connect "jdbc:mysql://cdh1:3306/source?useSSL=false&user=root&password=mypassword" \
--table sales_order \
--columns "order_number, customer_number, product_code, order_date, entry_date, order_amount, order_quantity" \
--hive-import \
--hive-table rds.sales_order \
--incremental append \
--check-column order_number \
--last-value $last_value3. 修改定期装载regular_etl.sql文件
修改数据库模式后,还要修改已经使用的定期装载HiveQL脚本。修改后的脚本如下所示。
-- 设置变量以支持事务
set hive.support.concurrency=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
set hive.compactor.initiator.on=true;
set hive.compactor.worker.threads=1;
USE dw;
-- 设置SCD的生效时间和过期时间
SET hivevar:cur_date = CURRENT_DATE();
SET hivevar:pre_date = DATE_ADD(${hivevar:cur_date},-1);
SET hivevar:max_date = CAST('2200-01-01' AS DATE);
-- 设置CDC的上限时间
INSERT OVERWRITE TABLE rds.cdc_time SELECT last_load, ${hivevar:cur_date} FROM rds.cdc_time;
-- 装载customer维度
-- 设置已删除记录和地址相关列上SCD2的过期,用<=>运算符处理NULL值。
UPDATE customer_dim
SET expiry_date = ${hivevar:pre_date}
WHERE customer_dim.customer_sk IN
(SELECT a.customer_sk
FROM (SELECT customer_sk,
customer_number,
customer_street_address,
customer_zip_code,
customer_city,
customer_state,
shipping_address,
shipping_zip_code,
shipping_city,
shipping_state
FROM customer_dim WHERE expiry_date = ${hivevar:max_date}) a LEFT JOIN
rds.customer b ON a.customer_number = b.customer_number
WHERE b.customer_number IS NULL OR
( !(a.customer_street_address <=> b.customer_street_address)
OR !(a.customer_zip_code <=> b.customer_zip_code)
OR !(a.customer_city <=> b.customer_city)
OR !(a.customer_state <=> b.customer_state)
OR !(a.shipping_address <=> b.shipping_address)
OR !(a.shipping_zip_code <=> b.shipping_zip_code)
OR !(a.shipping_city <=> b.shipping_city)
OR !(a.shipping_state <=> b.shipping_state)
));
-- 处理customer_street_addresses列上SCD2的新增行
INSERT INTO customer_dim
SELECT
ROW_NUMBER() OVER (ORDER BY t1.customer_number) + t2.sk_max,
t1.customer_number,
t1.customer_name,
t1.customer_street_address,
t1.customer_zip_code,
t1.customer_city,
t1.customer_state,
t1.shipping_address,
t1.shipping_zip_code,
t1.shipping_city,
t1.shipping_state,
t1.version,
t1.effective_date,
t1.expiry_date
FROM
(
SELECT
t2.customer_number customer_number,
t2.customer_name customer_name,
t2.customer_street_address customer_street_address,
t2.customer_zip_code customer_zip_code,
t2.customer_city customer_city,
t2.customer_state customer_state,
t2.shipping_address shipping_address,
t2.shipping_zip_code shipping_zip_code,
t2.shipping_city shipping_city,
t2.shipping_state shipping_state,
t1.version + 1 version,
${hivevar:pre_date} effective_date,
${hivevar:max_date} expiry_date
FROM customer_dim t1
INNER JOIN rds.customer t2
ON t1.customer_number = t2.customer_number
AND t1.expiry_date = ${hivevar:pre_date}
LEFT JOIN customer_dim t3
ON t1.customer_number = t3.customer_number
AND t3.expiry_date = ${hivevar:max_date}
WHERE (!(t1.customer_street_address <=> t2.customer_street_address)
OR !(t1.customer_zip_code <=> t2.customer_zip_code)
OR !(t1.customer_city <=> t2.customer_city)
OR !(t1.customer_state <=> t2.customer_state)
OR !(t1.shipping_address <=> t2.shipping_address)
OR !(t1.shipping_zip_code <=> t2.shipping_zip_code)
OR !(t1.shipping_city <=> t2.shipping_city)
OR !(t1.shipping_state <=> t2.shipping_state)
)
AND t3.customer_sk IS NULL) t1
CROSS JOIN
(SELECT COALESCE(MAX(customer_sk),0) sk_max FROM customer_dim) t2;
-- 处理customer_name列上的SCD1
-- 因为hive的update的set子句还不支持子查询,所以这里使用了一个临时表存储需要更新的记录,用先delete再insert代替update
-- 因为SCD1本身就不保存历史数据,所以这里更新维度表里的所有customer_name改变的记录,而不是仅仅更新当前版本的记录
DROP TABLE IF EXISTS tmp;
CREATE TABLE tmp AS
SELECT
a.customer_sk,
a.customer_number,
b.customer_name,
a.customer_street_address,
a.customer_zip_code,
a.customer_city,
a.customer_state,
a.shipping_address,
a.shipping_zip_code,
a.shipping_city,
a.shipping_state,
a.version,
a.effective_date,
a.expiry_date
FROM customer_dim a, rds.customer b
WHERE a.customer_number = b.customer_number AND !(a.customer_name <=> b.customer_name);
DELETE FROM customer_dim WHERE customer_dim.customer_sk IN (SELECT customer_sk FROM tmp);
INSERT INTO customer_dim SELECT * FROM tmp;
-- 处理新增的customer记录
INSERT INTO customer_dim
SELECT
ROW_NUMBER() OVER (ORDER BY t1.customer_number) + t2.sk_max,
t1.customer_number,
t1.customer_name,
t1.customer_street_address,
t1.customer_zip_code,
t1.customer_city,
t1.customer_state,
t1.shipping_address,
t1.shipping_zip_code,
t1.shipping_city,
t1.shipping_state,
1,
${hivevar:pre_date},
${hivevar:max_date}
FROM
(
SELECT t1.* FROM rds.customer t1 LEFT JOIN customer_dim t2 ON t1.customer_number = t2.customer_number
WHERE t2.customer_sk IS NULL) t1
CROSS JOIN
(SELECT COALESCE(MAX(customer_sk),0) sk_max FROM customer_dim) t2;
-- 装载product维度
-- 设置已删除记录和product_name、product_category列上SCD2的过期
UPDATE product_dim
SET expiry_date = ${hivevar:pre_date}
WHERE product_dim.product_sk IN
(SELECT a.product_sk
FROM (SELECT product_sk,product_code,product_name,product_category
FROM product_dim WHERE expiry_date = ${hivevar:max_date}) a LEFT JOIN
rds.product b ON a.product_code = b.product_code
WHERE b.product_code IS NULL OR (a.product_name <> b.product_name OR a.product_category <> b.product_category));
-- 处理product_name、product_category列上SCD2的新增行
INSERT INTO product_dim
SELECT
ROW_NUMBER() OVER (ORDER BY t1.product_code) + t2.sk_max,
t1.product_code,
t1.product_name,
t1.product_category,
t1.version,
t1.effective_date,
t1.expiry_date
FROM
(
SELECT
t2.product_code product_code,
t2.product_name product_name,
t2.product_category product_category,
t1.version + 1 version,
${hivevar:pre_date} effective_date,
${hivevar:max_date} expiry_date
FROM product_dim t1
INNER JOIN rds.product t2
ON t1.product_code = t2.product_code
AND t1.expiry_date = ${hivevar:pre_date}
LEFT JOIN product_dim t3
ON t1.product_code = t3.product_code
AND t3.expiry_date = ${hivevar:max_date}
WHERE (t1.product_name <> t2.product_name OR t1.product_category <> t2.product_category) AND t3.product_sk IS NULL) t1
CROSS JOIN
(SELECT COALESCE(MAX(product_sk),0) sk_max FROM product_dim) t2;
-- 处理新增的product记录
INSERT INTO product_dim
SELECT
ROW_NUMBER() OVER (ORDER BY t1.product_code) + t2.sk_max,
t1.product_code,
t1.product_name,
t1.product_category,
1,
${hivevar:pre_date},
${hivevar:max_date}
FROM
(
SELECT t1.* FROM rds.product t1 LEFT JOIN product_dim t2 ON t1.product_code = t2.product_code
WHERE t2.product_sk IS NULL) t1
CROSS JOIN
(SELECT COALESCE(MAX(product_sk),0) sk_max FROM product_dim) t2;
-- 装载order维度
INSERT INTO order_dim
SELECT
ROW_NUMBER() OVER (ORDER BY t1.order_number) + t2.sk_max,
t1.order_number,
t1.version,
t1.effective_date,
t1.expiry_date
FROM
(
SELECT
order_number order_number,
1 version,
order_date effective_date,
'2200-01-01' expiry_date
FROM rds.sales_order, rds.cdc_time
WHERE entry_date >= last_load AND entry_date < current_load ) t1
CROSS JOIN
(SELECT COALESCE(MAX(order_sk),0) sk_max FROM order_dim) t2;
-- 装载销售订单事实表
INSERT INTO sales_order_fact
SELECT
order_sk,
customer_sk,
product_sk,
date_sk,
order_amount,
order_quantity
FROM
rds.sales_order a,
order_dim b,
customer_dim c,
product_dim d,
date_dim e,
rds.cdc_time f
WHERE
a.order_number = b.order_number
AND a.customer_number = c.customer_number
AND a.order_date >= c.effective_date
AND a.order_date < c.expiry_date
AND a.product_code = d.product_code
AND a.order_date >= d.effective_date
AND a.order_date < d.expiry_date
AND to_date(a.order_date) = e.date
AND a.entry_date >= f.last_load AND a.entry_date < f.current_load ;
-- 更新时间戳表的last_load字段
INSERT OVERWRITE TABLE rds.cdc_time SELECT current_load, current_load FROM rds.cdc_time;4. 测试
(1)执行下面的SQL脚本准备客户和销售订单测试数据。
USE source;
/***
客户数据的改变如下:
更新已有八个客户的送货地址
新增客户9
***/
UPDATE customer SET
shipping_address = customer_street_address
, shipping_zip_code = customer_zip_code
, shipping_city = customer_city
, shipping_state = customer_state ;
INSERT INTO customer
(customer_name
, customer_street_address
, customer_zip_code
, customer_city
, customer_state
, shipping_address
, shipping_zip_code
, shipping_city
, shipping_state)
VALUES
('Online Distributors'
, '2323 Louise Dr.'
, 17055
, 'Pittsburgh'
, 'PA'
, '2323 Louise Dr.'
, 17055
, 'Pittsburgh'
, 'PA') ;
/***
新增订单日期为2016年7月12日的9条订单。
***/
SET @start_date := unix_timestamp('2016-07-12');
SET @end_date := unix_timestamp('2016-07-13');
DROP TABLE IF EXISTS temp_sales_order_data;
CREATE TABLE temp_sales_order_data AS SELECT * FROM sales_order WHERE 1=0;
SET @order_date := from_unixtime(@start_date + rand() * (@end_date - @start_date));
SET @amount := floor(1000 + rand() * 9000);
SET @quantity := floor(10 + rand() * 90);
INSERT INTO temp_sales_order_data VALUES (117, 1, 1, @order_date, @order_date, @amount, @quantity);
SET @order_date := from_unixtime(@start_date + rand() * (@end_date - @start_date));
SET @amount := floor(1000 + rand() * 9000);
SET @quantity := floor(10 + rand() * 90);
INSERT INTO temp_sales_order_data VALUES (118, 2, 2, @order_date, @order_date, @amount, @quantity);
SET @order_date := from_unixtime(@start_date + rand() * (@end_date - @start_date));
SET @amount := floor(1000 + rand() * 9000);
SET @quantity := floor(10 + rand() * 90);
INSERT INTO temp_sales_order_data VALUES (119, 3, 3, @order_date, @order_date, @amount, @quantity);
SET @order_date := from_unixtime(@start_date + rand() * (@end_date - @start_date));
SET @amount := floor(1000 + rand() * 9000);
SET @quantity := floor(10 + rand() * 90);
INSERT INTO temp_sales_order_data VALUES (120, 4, 4, @order_date, @order_date, @amount, @quantity);
SET @order_date := from_unixtime(@start_date + rand() * (@end_date - @start_date));
SET @amount := floor(1000 + rand() * 9000);
SET @quantity := floor(10 + rand() * 90);
INSERT INTO temp_sales_order_data VALUES (121, 5, 1, @order_date, @order_date, @amount, @quantity);
SET @order_date := from_unixtime(@start_date + rand() * (@end_date - @start_date));
SET @amount := floor(1000 + rand() * 9000);
SET @quantity := floor(10 + rand() * 90);
INSERT INTO temp_sales_order_data VALUES (122, 6, 2, @order_date, @order_date, @amount, @quantity);
SET @order_date := from_unixtime(@start_date + rand() * (@end_date - @start_date));
SET @amount := floor(1000 + rand() * 9000);
SET @quantity := floor(10 + rand() * 90);
INSERT INTO temp_sales_order_data VALUES (123, 7, 3, @order_date, @order_date, @amount, @quantity);
SET @order_date := from_unixtime(@start_date + rand() * (@end_date - @start_date));
SET @amount := floor(1000 + rand() * 9000);
SET @quantity := floor(10 + rand() * 90);
INSERT INTO temp_sales_order_data VALUES (124, 8, 4, @order_date, @order_date, @amount, @quantity);
SET @order_date := from_unixtime(@start_date + rand() * (@end_date - @start_date));
SET @amount := floor(1000 + rand() * 9000);
SET @quantity := floor(10 + rand() * 90);
INSERT INTO temp_sales_order_data VALUES (125, 9, 1, @order_date, @order_date, @amount, @quantity);
INSERT INTO sales_order
SELECT NULL,customer_number,product_code,order_date,entry_date,order_amount,order_quantity FROM temp_sales_order_data ORDER BY order_date;
COMMIT ;(2)执行定期装载并查看结果。
使用下面的命令执行定期装载。
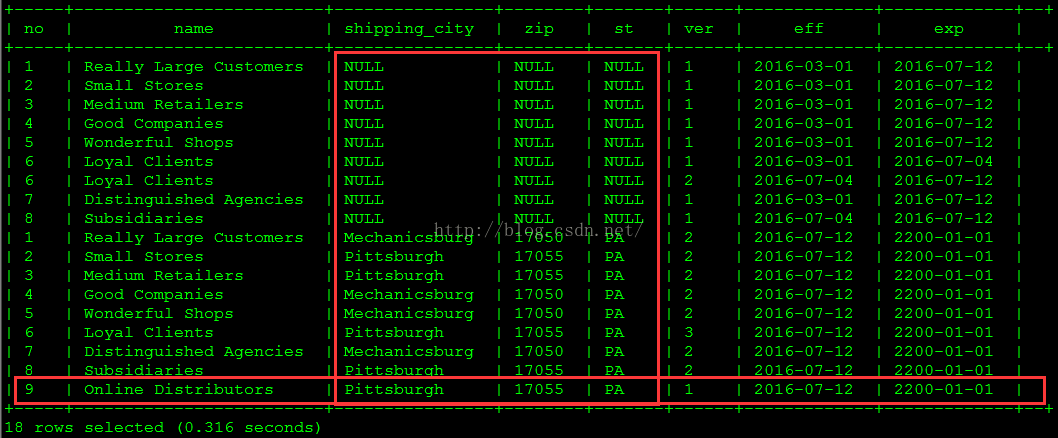
./regular_etl.sh use dw;
select customer_number no,
customer_name name,
shipping_city,
shipping_zip_code zip,
shipping_state st,
version ver,
effective_date eff,
expiry_date exp
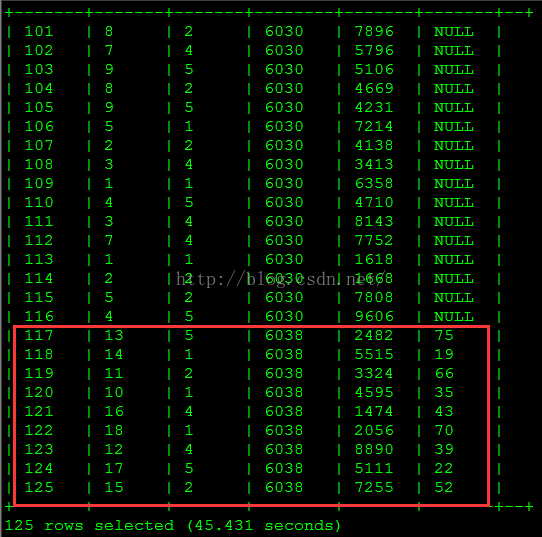
from customer_dim;select order_sk o_sk,
customer_sk c_sk,
product_sk p_sk,
order_date_sk od_sk,
order_amount amt,
order_quantity qty
from sales_order_fact
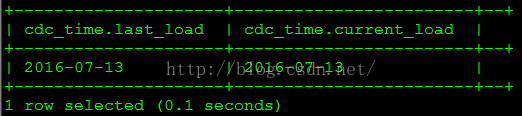
cluster by o_sk;select * from rds.cdc_time;至此,增加列所需的修改已完成。














 4811
4811











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









