







文档倒排索引主要是统计每个单词在各个文档中出现的频数,因此要以单词为key,value为文档以及该单词在此文档频数,即输出数据的格式形如:
< word1,[doc1,3] [doc2,4] ... > :表示word1这个单词在doc1文档中出现了3次,在doc2文档中出现了4次。
整个程序的输入是一系列文件,比如file01.txt, file02.txt, file03.txt ....,首先要将这些文件上传到hadoop hdfs中作为程序的输入。上传过程以及Java类的编译等可以参考这篇博客:运行Hadoop示例程序WordCount,这里不再详细介绍。本程序的源代码在文章最后面。
一、程序运行的大体思路
由于文档倒排索引考察的是一个单词和文档的关系,而系统默认的LineRecordReader是按照每行的偏移量作为map输入时的key值,每行的内容作为map的value值,这里的key值(即行偏移量对我们的意义不大),我们这里考虑将一个文档的名字作为关键字,而每一行的值作为value,这样处理起来比较方便,(即:map的输入形式为<fileName, a line>,主要是通过一个自定义的RecordReader类来实现,下面会有介绍)。整个程序数据处理流程如下面所示:
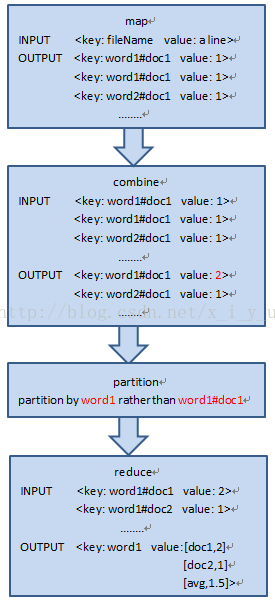
map类的主要作用是处理程序的输入,这里的输入形式是<fileName,a line>,即输入的关键字key是文件名如file01.txt,值value为一行数据,map的任务是将这一行数据进行分词,并以图中第一部分的形式进行输出。
combine类的主要作用是将map输出的相同的key的value进行合并(相加),这样有利于减少数据传输,combine是在本节点进行的。
partition的主要作用是对combine的输出进行分区,分区的目的是使key值相同的数据被分到同一个节点,这样在进行reduce操作的时候仅需要本地的数据就足够,不需要通过网络向其他节点寻找数据。上图中的 "partitionby word1 rather than word1#doc1" 意思是将word1作为分区时的关键字,而不是word1#doc1,因为我们在之前的输出的关键字的形式是word1#doc1的不是word1这样系统会默认按照进行word1#doc1分区,而我们最终想要的结果是按照word1分区的,所以需要我们自定义patition类。
reduce的操作主要是将结果进行求和整理,并使结果符合我们所要的形式。
2、程序和各个类的设计说明
这部分按照程序执行的顺序依次介绍每个类的设计和作用,有些子类继承了父类,但是并没有重新实现父类的方法,这里不详细介绍这些方法。
2.1、FileNameRecordReader类
FileNameRecordReader类继承自RecordReader,是RecordReader类的自定义实现,主要作用是将记录所在的文件名作为key,而不是记录行所在文件的偏移,获取文件名所用的语句为:
fileName = ((FileSplit) arg0).getPath().getName();
2.2、FileNameInputFormat类
因为我们重写了RecordReader类,这里要重写FileInputFormat类来使用我们的自定义FileNameRecordReader,这个类的主要作用就是返回一个FileNameRecordReader类的实例。
2.3、InvertedIndexMapper类
这个类继承自Mapper,主要方法有setup和map方法,setup方法的主要作用是在执行map前初始化一个stopwords的list,主要在map处理输入的单词时,如果该单词在stopwords的list中,则跳过该单词,不进行处理。stopwords刚开始是以一个文本文件的形式存放在hdfs中,程序在刚开始执行的时候通过Hadoop Configuration将这个文本文件设置为CacheFile供各个节点共享,并在执行map前,初始化一个stopwords列表。
InvertedIndexMapper的主要操作是map,这个方法将读入的一行数据进行分词操作,并以<key: word1#doc1 value: 1>的键值对形式,向外写数据,在map方法中,写出的value都是1。InvertedIndexMapper类的类图如下图2所示。
2.4、SumCombiner类
这个类主要是将前面InvertedIndexMapper类的输出结果进行合并,如果一个单词在一个文档中出现了多次,则将value的值设置为出现的次数和。
2.5、NewPartitioner类

2.5、InvertedIndexReducer类
InvertedIndexReducerreduce的输入形式为:<key: word1#doc1 value: 2> <key: word1#doc2 value: 1> <key: word2#doc1 value: 1>,如第一个图中所示可见同一个单词会作为多次输入,传递给reduce,而最终的结果要求只输出一次单词,而不同的文档如doc1,doc2要作为这个单词的value输出,我们的reduce在实现此功能时,设置两个变量CurrentItem和postingList,其中CurrentItem保存每次每次读入的key,初始值为空,postingList是一个列表,表示这个key对于的出现的文档以及在此文档中出现的次数。因为同一个key可能被读入多次,每次在读入key时,同上一个CurrentItem进行比较,如果跟上一个CurrentItem相同,表示读入的是同一个key,进而将新读入的key的文档追加到postingList中;如果根上一个CurrentItem不同,表示相同的单词以及读完了,这时候我们要统计上一个CurrentItem出现的总次数,以及含有此item的总的文章数,这些信息我们之前都存放在postingList中,只要遍历此时的postingList就能得到上述信息,并在得到信息之后重置CurrentItem和postingList。具体见代码实现。其类图如上图所示。
3、运行结果截图
我编译以及执行使用的命令如下,大家可以根据自己目录情况适当调整
javac -classpath ~/hadoop-1.2.1/hadoop-core-1.2.1.jar -d ./ InvertedIndexer.java
jar -cfv inverted.jar -C ./* .
hadoop jar ./inverted.jar InvertedIndexer input output
#运行结束后显示
hadoop fs -cat output/part-r-00000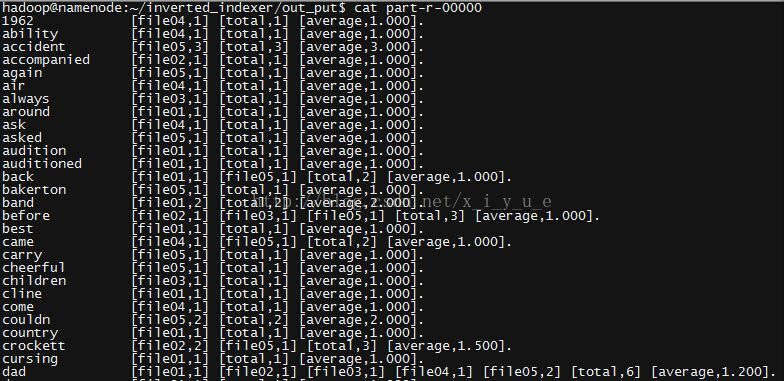
4、源程序
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.util.List;
import java.util.Set;
import java.util.StringTokenizer;
import java.util.ArrayList;
import java.util.TreeSet;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.lib.input.LineRecordReader;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class InvertedIndexer {
public static class FileNameInputFormat extends FileInputFormat<Text, Text> {
@Override
public RecordReader<Text, Text> createRecordReader(InputSplit split,TaskAttemptContext context) throws IOException,
InterruptedException {
FileNameRecordReader fnrr = new FileNameRecordReader();
fnrr.initialize(split, context);
return fnrr;
}
}
public static class FileNameRecordReader extends RecordReader<Text, Text> {
String fileName;
LineRecordReader lrr = new LineRecordReader();
@Override
public Text getCurrentKey() throws IOException, InterruptedException {
return new Text(fileName);
}
@Override
public Text getCurrentValue() throws IOException, InterruptedException {
return lrr.getCurrentValue();
}
@Override
public void initialize(InputSplit arg0, TaskAttemptContext arg1) throws IOException, InterruptedException {
lrr.initialize(arg0, arg1);
fileName = ((FileSplit) arg0).getPath().getName();
}
public void close() throws IOException {
lrr.close();
}
public boolean nextKeyValue() throws IOException, InterruptedException {
return lrr.nextKeyValue();
}
public float getProgress() throws IOException, InterruptedException {
return lrr.getProgress();
}
}
public static class InvertedIndexMapper extends Mapper<Text, Text, Text, IntWritable> {
private Set<String> stopwords;
private Path[] localFiles;
private String pattern = "[^\\w]";
public void setup(Context context) throws IOException,InterruptedException {
stopwords = new TreeSet<String>();
Configuration conf = context.getConfiguration();
localFiles = DistributedCache.getLocalCacheFiles(conf);
for (int i = 0; i < localFiles.length; i++) {
String line;
BufferedReader br = new BufferedReader(new FileReader(localFiles[i].toString()));
while ((line = br.readLine()) != null) {
StringTokenizer itr = new StringTokenizer(line);
while (itr.hasMoreTokens()) {
stopwords.add(itr.nextToken());
}
}
br.close();
}
}
protected void map(Text key, Text value, Context context) throws IOException, InterruptedException {
String temp = new String();
String line = value.toString().toLowerCase();
line = line.replaceAll(pattern, " ");
StringTokenizer itr = new StringTokenizer(line);
for (; itr.hasMoreTokens();) {
temp = itr.nextToken();
if (!stopwords.contains(temp)) {
Text word = new Text();
word.set(temp + "#" + key);
context.write(word, new IntWritable(1));
}
}
}
}
public static class SumCombiner extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static class NewPartitioner extends HashPartitioner<Text, IntWritable> {
public int getPartition(Text key, IntWritable value, int numReduceTasks) {
String term = new String();
term = key.toString().split("#")[0]; // <term#docid>=>term
return super.getPartition(new Text(term), value, numReduceTasks);
}
}
public static class InvertedIndexReducer extends Reducer<Text, IntWritable, Text, Text> {
private Text word1 = new Text();
private Text word2 = new Text();
String temp = new String();
static Text CurrentItem = new Text(" ");
static List<String> postingList = new ArrayList<String>();
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
String keyWord = key.toString().split("#")[0];
int needBlank = 15-keyWord.length();
for(int i=0;i<needBlank;i++){
keyWord += " ";
}
word1.set(keyWord);
temp = key.toString().split("#")[1]; //key的形式为word1#doc1,所以temp为doc1
for (IntWritable val : values) { //得到某个单词在一个文件中的总数
sum += val.get();
}
word2.set("[" + temp + "," + sum + "]"); //word2的格式为:[doc1,3]
if (!CurrentItem.equals(word1) && !CurrentItem.equals(" ")) {
StringBuilder out = new StringBuilder();
long count = 0;
double fileCount = 0;
for (String p : postingList) {
out.append(p);
out.append(" ");
count = count + Long.parseLong(p.substring(p.indexOf(",") + 1,p.indexOf("]")));
fileCount++;
}
out.append("[total," + count + "] ");
double average = count/fileCount;
out.append("[average,"+String.format("%.3f", average)+"].");
if (count > 0)
context.write(CurrentItem, new Text(out.toString()));
postingList = new ArrayList<String>();
}
CurrentItem = new Text(word1);
postingList.add(word2.toString());
}
public void cleanup(Context context) throws IOException,InterruptedException {
StringBuilder out = new StringBuilder();
long count = 0;
for (String p : postingList) {
out.append(p);
out.append(" ");
count = count + Long.parseLong(p.substring(p.indexOf(",") + 1,p.indexOf("]")));
}
out.append("[total," + count + "].");
if (count > 0)
context.write(CurrentItem, new Text(out.toString()));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
DistributedCache.addCacheFile(new URI("hdfs://namenode:9000/user/hadoop/stop_word/stop_word.txt"),conf);
Job job = new Job(conf, "inverted index");
job.setJarByClass(InvertedIndexer.class);
job.setInputFormatClass(FileNameInputFormat.class);
job.setMapperClass(InvertedIndexMapper.class);
job.setCombinerClass(SumCombiner.class);
job.setReducerClass(InvertedIndexReducer.class);
job.setPartitionerClass(NewPartitioner.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
4、参考文献
《深入理解大数据 大数据处理与编程实战》主编:黄宜华老师(南京大学)














 2554
2554











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









