







源码下载地址:http://download.csdn.net/detail/wxq714586001/8878103
一共由两个scrapy工程实现。
第一个工程zhihu_topic:实现抓取关注人数超过2000的知乎话题、相应链接、父子话题并存入MySQL数据库。这个工程只要执行一次,第二个工程会利用这里获取到的链接(link_id)。
usage:
scrapy crawl topic
下面是从数据库中获取一部分话题的截图

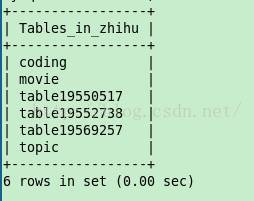
第二个工程zhihu:
先贴出配置文件
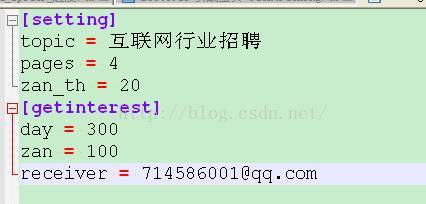
topic表示抓取的话题,确保和数据库中保存的名字一致。
pages表示抓取的页数的位数,例如1表示抓取(1~9)页,2表示抓取(1-99)页。
zan_th表示赞数的最低阈值,超过这个阈值的回答才会被抓取下来。
day表示发送邮件时,最近300天内的回答才会被发送。
zan表示发送邮件时,超过100个赞的回答才会被发送。
receiver表示接受者的qq邮箱。
usage:
scrapy crawl zhihu
效果图

注意:
在抓取完成后会立即自动发送邮件。














 1853
1853











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









