







正规表示法:
处理字符串的方法,以行为单位进行字符串的处理,通过一些特殊符号的帮助可以简单的实现搜寻、删除、取代等处理。可以分为基础正规表示法和延伸正规表示法。
注意,正规表示法和通配符是完全不一样的东西,通配符是bash接口的一个功能,但正规表示法是字符串处理的表示方式
要使用正规表示法必须要求被使用的工具支持正规表示法,常见的有grep,sed,vim等
grep [-nvAB] [--color=auto] '搜寻字符串' filename
-n:显示时添加行号
-v:反向选择,即选择没有所搜寻字符串的行
-A:后接数字,after,除了本行,后续的n行也列出
-B:后接数字,before,除了本行,前面的n行也列出
--color=auto:添加颜色显示(Ubuntu中已用alias默认添加该选项)
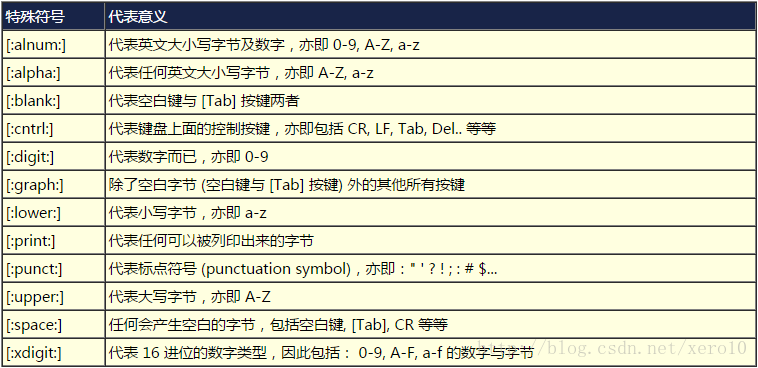
[]:无论[]中有几个字符串,都代表1个字符(例如搜寻 't[ae]st'是搜寻'tast'或'test')。在[]中可以用"-"表示范围,如[1-5]
^:在[]中表示反向选择,即不含有"^"后字符的内容;在[]外表示行首字符
$:表示行尾字符
.:代表只有一个任意字符
*:代表重复它之前的那一个字符任意次(常用.*表示任意个任意字符)
{}:限定重复次数,使用时需要用"\"跳脱(例:两个o:'o\{2\}';2-5个o:'o\{2,5\}';2个以上o:'o\{2,\}')
grep在数据中查找字符串时,是以“整行”为单位进行提取的
单引号内的是正规表示法的字符,可能需要跳脱

sed [-nefr] [动作]
-n:使用silent模式。一般sed的用法中,所有来自stdin的数据都会被列到屏幕上,但在silent模式下,只有被sed处理过的内容才会被列出
-e:直接在指令列模式上进行sed的动作编辑
-f:-f filename可以执行filename中的sed动作
-r:支持延伸正规表示法的语法(预设是基础正规表示法的语法)
-i:直接修改读取的档案,而不是由屏幕输出
动作说明:[n1,n2]function
n1,n2:可选参数,代表进行动作的次数。如在10到20之间进行,则【10,20[动作行为]】
function:
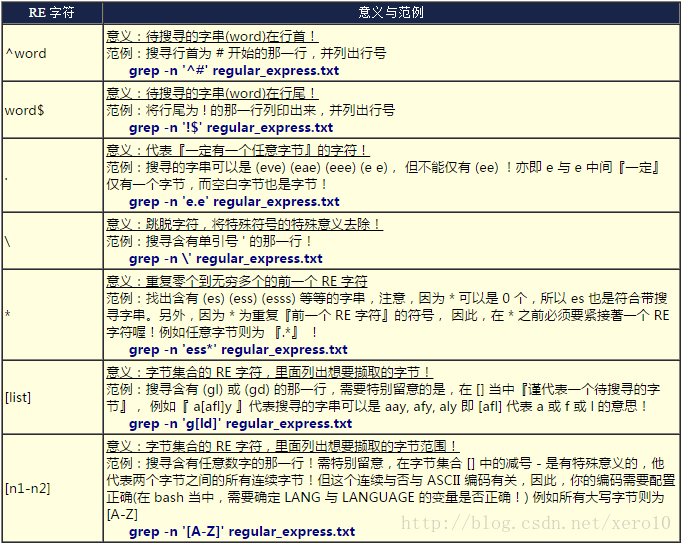
a:新增,后接字符串,字符串会出现在当前的下一行
c:取代,后接字符串,取代n1,n2之间的行
i:插入,后接字符串,字符串会出现在当前的上一行
p:打印,将某个选择的数据打出
s:取代
sed后面接的动作一定要用单引号''括起来,如果要接两个或以上的动作时每个动作前要加-e
例:
列出/etc/passwd的内容,删除第2行到最后一行:cat -n /etc/passwd | sed '2,$d'
列出/etc/passwd的内容,在第二行后添加"drink tea":cat -n /etc/passwd | sed '2a drink tea'(若想增加多行,则需要以反斜杠加回车进行跳脱,再输入新的一行)
列出/etc/passwd的内容,以"No these lines"取代2-5行:cat -n /etc/passwd | sed '2,5 c No these lines'
仅列出/etc/passwd的5-7行:cat -n /etc/passwd | sed -n '5,7p'
除了整行的处理模式之外,sed还可以用行为单位,进行部分数据的搜索取代功能:
sed 's/要被取代的字符串/新字符串/g'
延伸正规表示法:
可以通过群组功能"|"进行搜寻,如:egrep -v '^$|^.*#' test
printf '打印格式' 实际内容
格式:
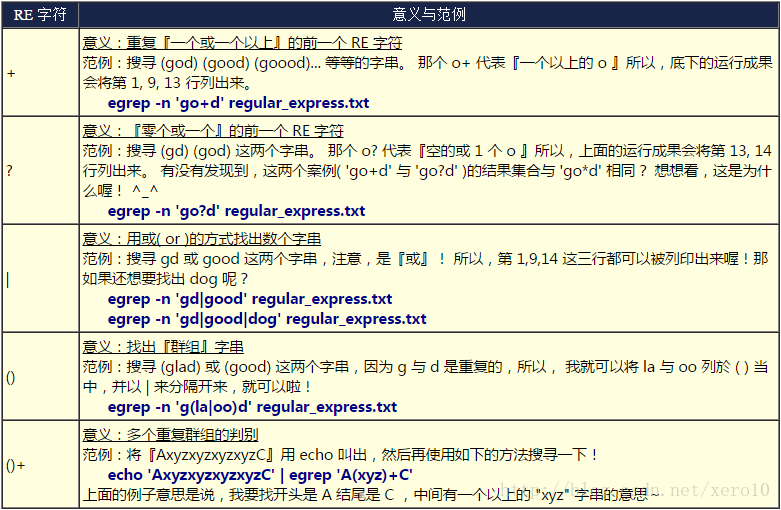
\a:警告声音输出
\b:退格键
\f:清除屏幕
\n:输出新的一行
\r:即Enter
\t:水平[tab]
\v:垂直[tab]
\xNN:NN为两位的数字,可以转数字为字符
%ns:n是数字,s代表string,打印n位字符串
%ni:n是数字,i代表integer,打印n位整数
%N.nf:n与N均为数字,f代表float
例:printf '%s\t %i\t %i\t %i\n' `cat test` | grep -v 'Name'
awk:倾向于将一行分成若干个字段来处理(默认分隔符为空格或tab),适合小型数据处理
awk '条件1{动作1} 条件2{动作2} ...' filename
每个字段都有变量名($1,$2...)。特殊变量:
NF:每一行($0)拥有的字段总数
NR:目前awk所处理的数据是第几行
FS:目前的分隔字符,默认是空格或tab
awk后续的所有动作是以单引号括住的,如果要以print打印时,非变量的文字部分需要用双引号引出
所有的awk动作({}中的动作),如果需要多个指令辅助可利用";"间隔,或直接以Enter隔开每个指令
与bash shell不同,在awk中变量可以直接使用,不需要加$
例:last -n 5 | awk '{print $1 "\t" $3}':打印第一个和第三个字段
例:last -n 5 | awk '{print $1 "\t Lines: " NR "\t Columns: " NF}'
例:cat /etc/passwd | awk '{FS=":"} $3 < 10 {print $1 "\t" $3}'
/etc/passwd以“:”分隔,打印第三个字段小于10的行的第一个字段和第三个字段(第一行无法打出,因为读入第一行时分隔符仍为空格,定义的FS=":"从第二行开始生效)要从第一行开始生效:cat /etc/passwd | awk 'BEGIN {FS=":"} $3<10 {print $1 "\t" $3}'
例:cat test | awk 'NR==1'{print "%10s %10s %10s %10s %10s\n",$1,$2,$3,$4,"Total"} NR>=2{total=$2+$3+$4 print "%10s %10d %10d %10d %10d\n", $1,$2,$3,$4, total}'
第一行单独处理,并进行加法计算
diff:以行为单位对比两个档案间的差异(还可以对比不同目录下相同文件名的内容)
diff [-bBi] from-file to-file
-b:忽略一行中仅有多个空格的差异
-B:忽略空白行的差异
-i:忽略大小写的不同
from-file或to-file可以用"-"取代。对比结果:
4d3:左边第4行被删掉了(d),基准是右边第3行;6c5:左边第6行被取代(c),基准是右边第5行
cmp:以字节为单位对比两个档案
cpm [-s] file1 file2
-s:列出所有的不同点的字节(预设仅会输出第一个不同)
patch:用补丁档更新/还原档案
用diff制作补丁档:
diff -Naur pw pw_new > pw.patch
更新档案:patch -pN < patch_file
还原档案:patch -R -pN < patch_file
-p:后接数字,代表取消几层目录
-R:还原档案
例:更新pw:patch -p0 < pw.patch
例:还原pw:patch -R -p0 < pw.patch
pr:打印纯文本文档(页眉会增加档案时间、档案名和页码)















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









