









最近刷Leetcode发现凡是找字符串中重复字符或者数组中找重复数据的时候就不知道从何下手了。
所以决定学习一下哈希表解题,哈希表的原理主要是解决分类问题,hash表是介于链表和二叉树之间的一种中间结构。链表使用十分方便,但是数据查找十分麻烦;二叉树中的数据严格有序,但是这是以多一个指针作为代价的结果。hash表既满足了数据的查找方便,同时不占用太多的内容空间,使用也十分方便。
定义hash数据结构,我采用的解决冲突的方法是分离链接法。
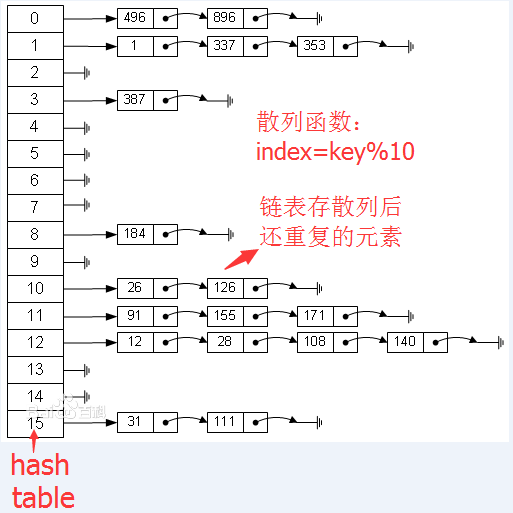
//单链表结构
typedef struct listnode* position;
typedef struct listnode* list;
struct listnode{
ElementType data;
position next;
};
//hash表结构
typedef struct hashtbl* hashtable;
struct hashtbl {
int tablesize;
list *thelists;
};哈希散列函数index = key%tablesize
index HashFunc(const ElementType key,int tablesize)
{
//unsigned int hashval = 0;
//while(*key != '\0')
//hashval = (hashval << 5) + *key++;
//return hashval % tablesize;
return key % tablesize;
}创建hash表,并初始化
hashtable InitializeHashTable(int tablesize)
{
hashtable H;
H = (hashtable)malloc(sizeof(hashtable));
if(NULL == H) return NULL;
H->tablesize = tablesize;
H->thelists = (list*)malloc(sizeof(list) * H->tablesize);
int i = 0;
for(i=0;i<H->tablesize;i++)//链表是有表头的单链表
{
H->thelists[i] = (list)malloc(sizeof(struct listnode));
H->thelists[i]->next = NULL;
}
return H;
}删除hash表
void DeleteHashTable(hashtable H)
{
position P,tem;
int i = 0;
for(i=0;i<H->tablesize;i++)
{
P = H->thelists[i]->next;
while(P != NULL)
{
tem = P;
free(tem);
P=P->next;
}
}
free(H->thelists);
free(H);
}往hash表中插入新元素
position Find(ElementType key,hashtable H)
{
position P;
list L;
L = H->thelists[ HashFunc( key, H->tablesize) ];
P = L->next;
while(P != NULL && P->data != key)
P = P->next;
return P;
}
void Insert(ElementType key,hashtable H)
{
position pos,newnode;
list L;
pos = Find(key,H);
if(pos == NULL)
{
newnode = (position)malloc(sizeof(position));
L = H->thelists[ HashFunc( key, H->tablesize) ];
newnode->data = key;
newnode->next = L->next;
L->next = newnode;
}
}打印hash表中所有的元素
void PrintHashTable(hashtable H)
{
position P;
int i = 0;
for(i=0;i<H->tablesize;i++)
{
P = H->thelists[i]->next;
printf("H->thelists[%d] = ",i);
while(P != NULL)
{
printf(" %d",P->data);
P=P->next;
}
printf("\n");
}
}测试main函数
int main()
{
int num[10] = {3,45,5,64,7,9,8,3,75,75};
hashtable H;
H = InitializeHashTable(10);
int i = 0;
for(i=0;i<10;i++)
{
Insert(num[i],H);
}
PrintHashTable(H);
DeleteHashTable(H);
}头文件
#include <stdlib.h>
#include <stdio.h>
#include <stdbool.h>
typedef int ElementType;
typedef unsigned int index;测试结果,可以看到图片中散列后在hash表中一样位置的都保存下来了,形成一个链表如数据75 5 45;但是相同的数据只保存一份,比如3和3,75和75
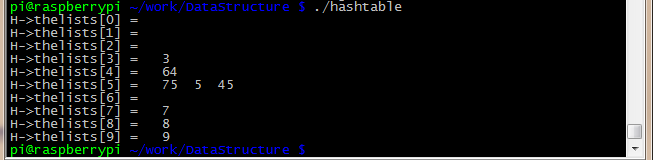
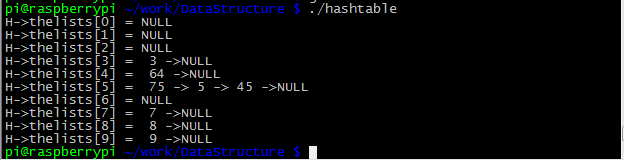














 1175
1175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









