







一:课程计划
1、 solr介绍
2、 solr安装配置(重点)
3、 solr的基本使用(重点)
4、 solrj的使用(重点)
5、 hbase + solr代码示例
二: Solr介绍
2.1 什么是solr
Solr也是Apache下一个项目,它是使用java开发的,它是基于Lucene的全文搜索服务器。
Solr如何进行索引和搜索
索引:客户端(可以是浏览器可以是java程序)发送post请求到solr服务器,发给solr服务器一个文档(xml、json),就可以进行一个添加索引删除索引、修改索引的操作。
搜索:客户端(可以是浏览器可以是java程序)发送get请求到solr服务器,请求solr服务器给它响应一个结果文档(xml、json),程序员拿到这些文档就可以对其进行解析。进行视图渲染。
Solr本身没有UI界面的功能。
2.2 solr + hbase
实现原理:
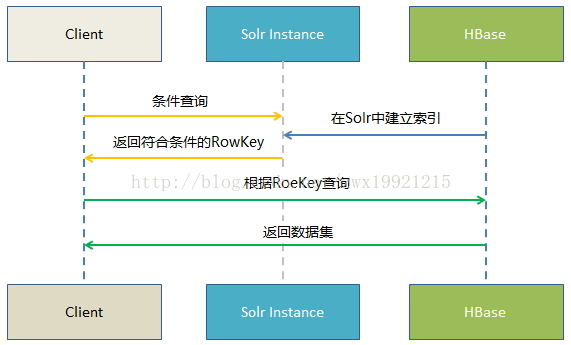
1. 在向Hbase增、删时同时把涉及条件过滤的字段和rowkey在Solr中建立索引;
2. 通过Solr的多条件查询快速获得符合过滤条件的rowkey;
3. 拿到这些rowkey之后在HBASE中通过指定rowkey进行查询。
2.3 Solr和lucene的区别
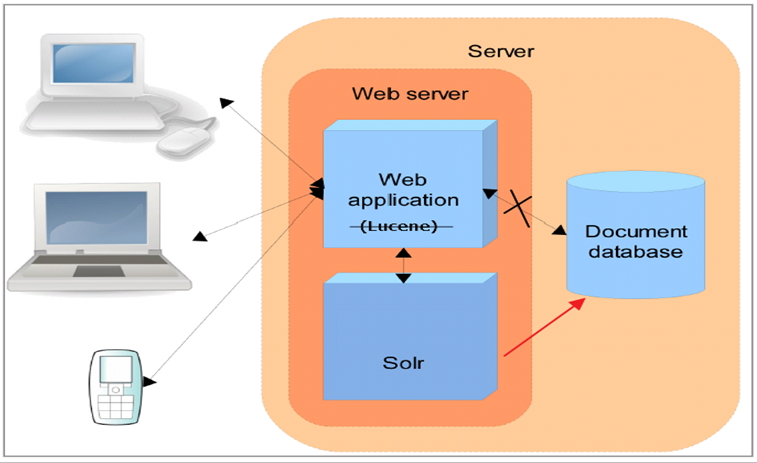
Lucene是一个全文检索的工具包,它是一堆jar包,不能单独运行,即不能独立对外提供服务。
Solr是一个全文搜索服务器,它可以独立运行,它能独立对外提供搜索和索引服务。
使用lucene开发站内搜索的话,程序员编写的代码量会比较大,而且在搜索和索引流程得考虑他的性能。
使用solr开发站内搜索的话,程序员只需编写少量的代码,快速的搭建出来站内搜索功能。而且性能方面不需要程序员去考虑,solr对它已经进行了处理。
三: Solr安装配置
3.1 Solr下载
Solr和lucene的版本是同步更新的
下载地址:http://archive.apache.org/dist/lucene/solr/
下载版本:5.2.0
目录:
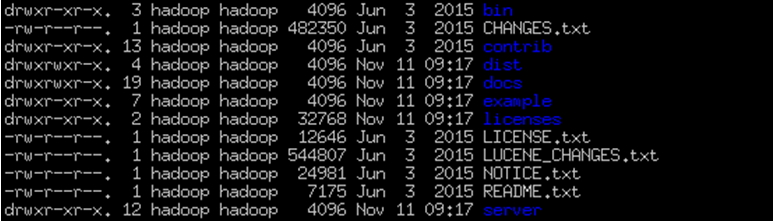
bin:solr的脚本
Contrib:solr为了增强自身的功能,所添加的扩展依赖包
Dist:solr build过程时产生的war包和jar包,还有它的一些依赖包
Docs:文档
Example:例子目录
3.2 SolrCore的安装配置
3.2.1 Solrhome和SolrCore
Solrhome是一个目录,它是solr运行的主目录,它包括多个SolrCore目录,SolrCore目录中就solr实例的运行配置文件和数据文件。
Solrhome中可以包括多个SolrCore,每个SolrCore互相独立,而且可以单独对外提供搜索和索引服务。
3.2.2 SolrHome
Solrhome的位置:
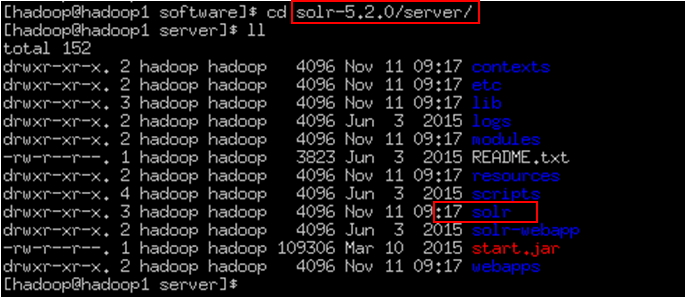
将此目录copy到其他位置为了便于理解将此命名为:solrHome。
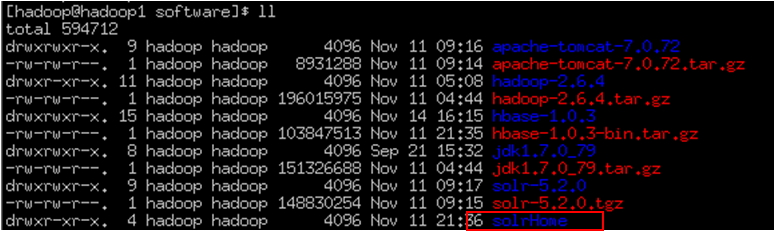
3.2.3 SolrCore
SolrCore位置:

将此solr文件夹copy到刚才的solrHome文件夹中、为了方便理解将此命名为solrCore0(改名称后目录下core.properties里名称也要改)
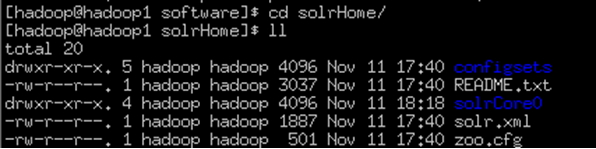
在solrCore0下新建文件夹data

在data下新建文件夹index、tlog

3.3 Solr部署到Tomcat
Solr需要运行一个servlet容器,它默认通过了一个servlet容器:jetty(java写的),项目中大多使用的是Tomcat
3.3.1 把solr的war部署到Tomcat中
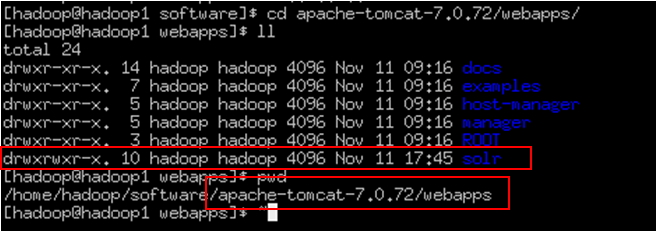
solr.war的位置:
复制到tomcat的webapps下、tomcat执行以下会生成solr文件夹、将solr.war删除
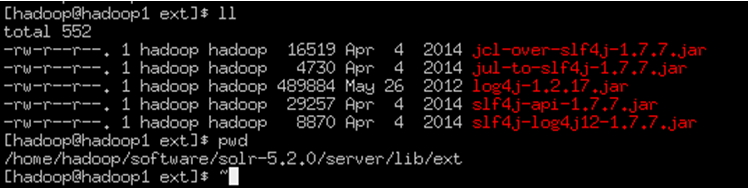
添加扩展依赖包、将如下位置的jar、copy到tomcat/webapps/solr/WEB-INF/lib
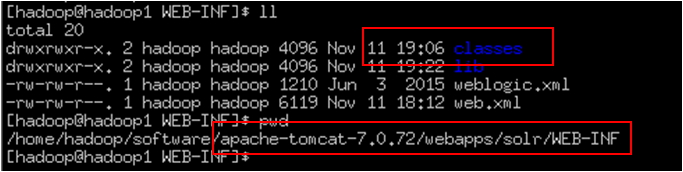
添加log4j日志配置文件:在如下目录下新建文件夹classes用于存放配置文件
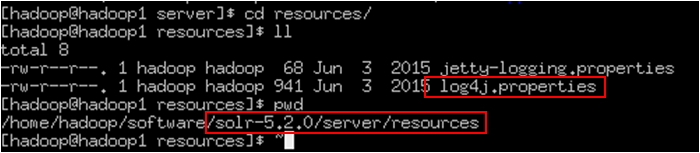
Log4j配置文件位置:(将此文件copy到classes中)
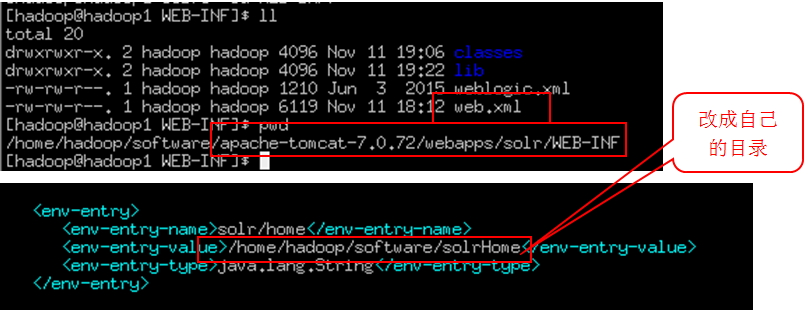
在web.xml中指定solrhome的位置
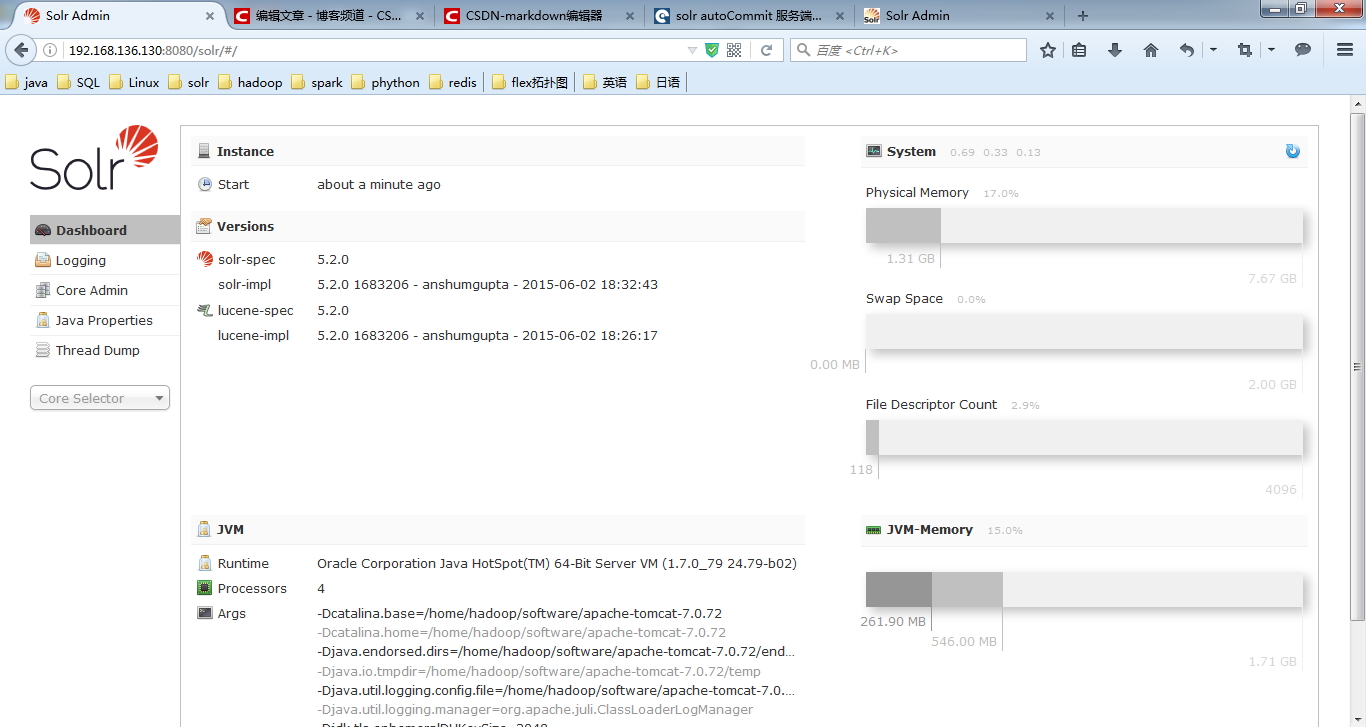
3.3.2 启动Tomcat进行访问
3.3.2.1 访问地址
http:/xxxxxxxxx:8080/solr/
看到该界面表示安装成功。

3.4 界面功能介绍
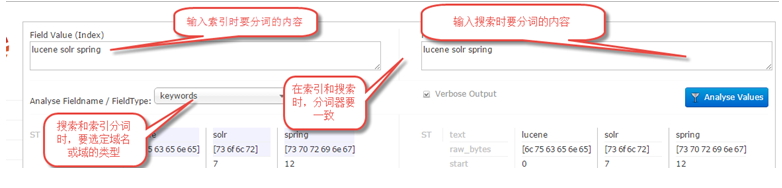
3.4.1 Analysis
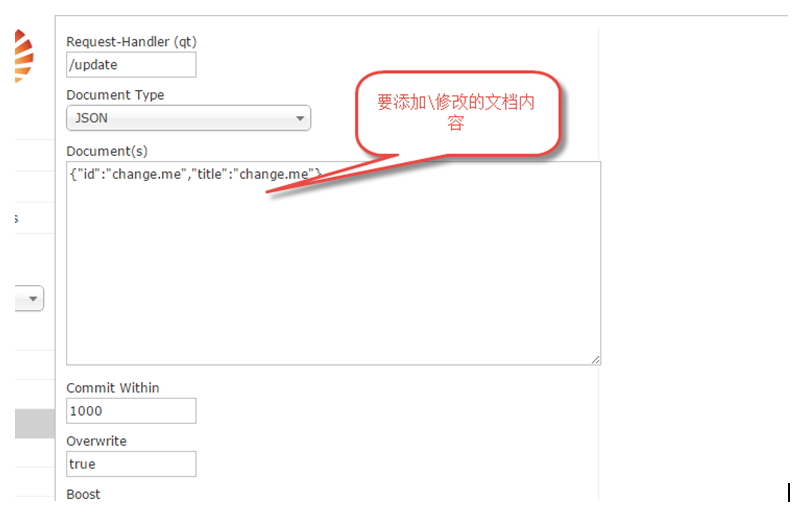
3.4.2 Document
通过该界面操作,可以对索引库进行添加索引、删除索引、修改索引
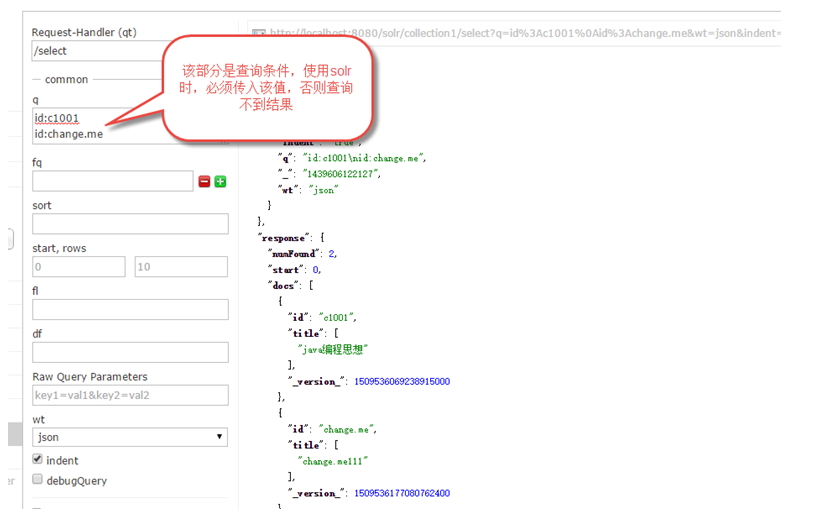
在solr中,添加或修改文档时,必须要传入一个唯一主键id
3.4.3 Query
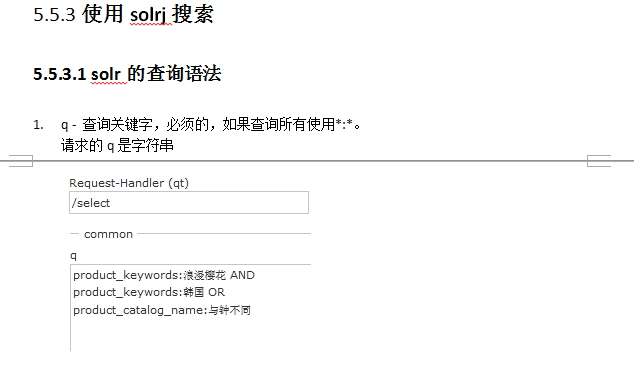
q:查询
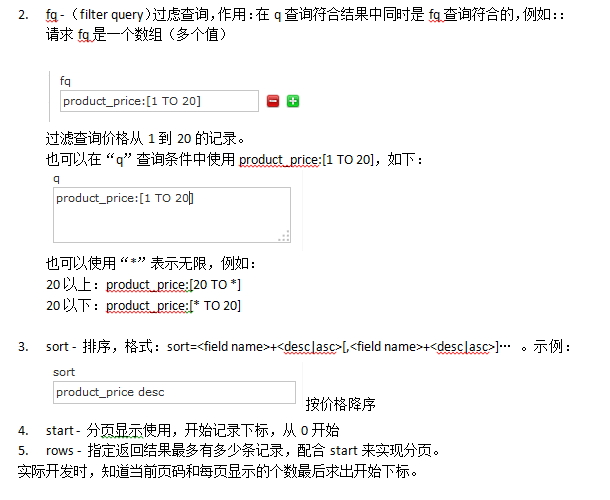
fq:过滤
sort:排序
start,rows:一看就是分页其他自己摸索
3.5 多SolrCore配置
一个solr工程中可以配置多个SolrCore实例。
配置多个SolrCore实例有啥好处:
1、 一个solr工程配置多个SolrCore,而且每个solrcore之间是互相独立,可以单独对外提供搜索和索引服务。这类似于数据库。一个数据库可以有多个实例。如果有新需求,可以直接扩展实例。
2、 多Solrcore在管理索引文件时,可以进行分类管理。
3、 使用solrcloud(solr集群)必须要建立多SolrCore。
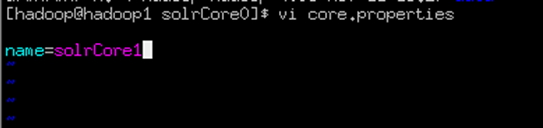
复制solrhome下的solrCore0到本目录下,并且改名为solrCore1
修改solrCore1文件中core.properties
四: Solr的基本使用
4.1 Schema.xml
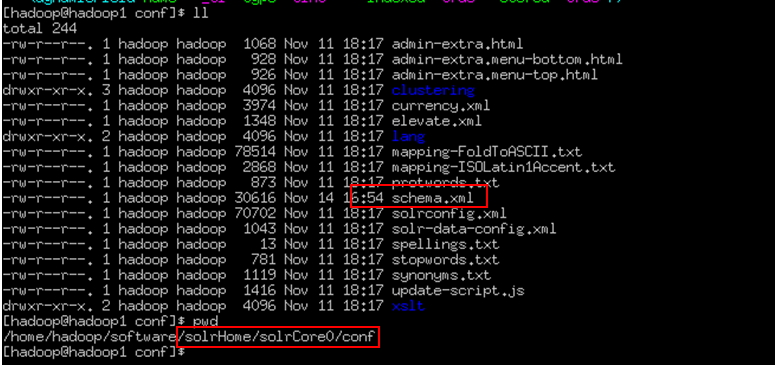
Schema.xml文件在SolrCore中conf目录下。这个文件主要 是配置域名及域的类型等信息。Solr中的域要先定义后使用。
文件位置:
4.1.1 Field(重点)
配置solr的域:
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />Name:域名
Type:域的类型(也需要配置)
Indexed:是否索引
Stored:是否存储
Required:是否必须,一般只有id才设置
multiValued:是否可以多值。如果设置多值的话,里面的值就采用数组方式存储。比如商品图片(大图、中图、小图等等)
4.1.2 dynamicField
配置动态域:
<dynamicField name="*_i" type="int" indexed="true" stored="true"/>Name:指定域的名称,该域的名称是通过一个表达式来指定的
Type:域的类型(在使用动态域的时候,要分清该域对应的类型)
4.1.3 uniqueKey
指定一个主键的域,每个文档中都应该有一个唯一主键
<uniqueKey>id</uniqueKey>4.1.4 copyField
复制域,将源域的内容复制到目标域中:
<copyField source="cat" dest="text"/>Source:源域
Dest:目标域
目标域:
<field name="text" type="text_general" indexed="true" stored="false" multiValued="true"/>4.1.5 fieldType(重点)
配置域的类型
<fieldType name="text_general" class ="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
Name:域的类型的名称
Class:指定solr的类型
Analyzer:配置分词器
Type:index(索引分词器)、query(搜索分词器)
Tokenizer:分词器
Filter:过滤器
4.2 配置中文分词器
使用ikAnalyzer中文分词器
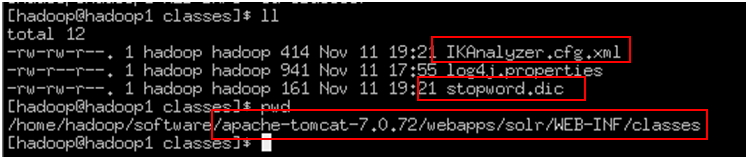
1、 把IKAnalyzer-5.0.jar添加到solr/WEB-INF/lib目录下
2、 复制IKAnalyzer的配置文件和自定义词典和停用词词典到solr的classpath下。
3、 配置fieldType,指定使用中文分词器

4、 配置field,使用中文分词器的fieldType
<field name="titleIK" type="test_ik" stored="true" required="false" multiValued="false" />5、 重启Tomcat测试
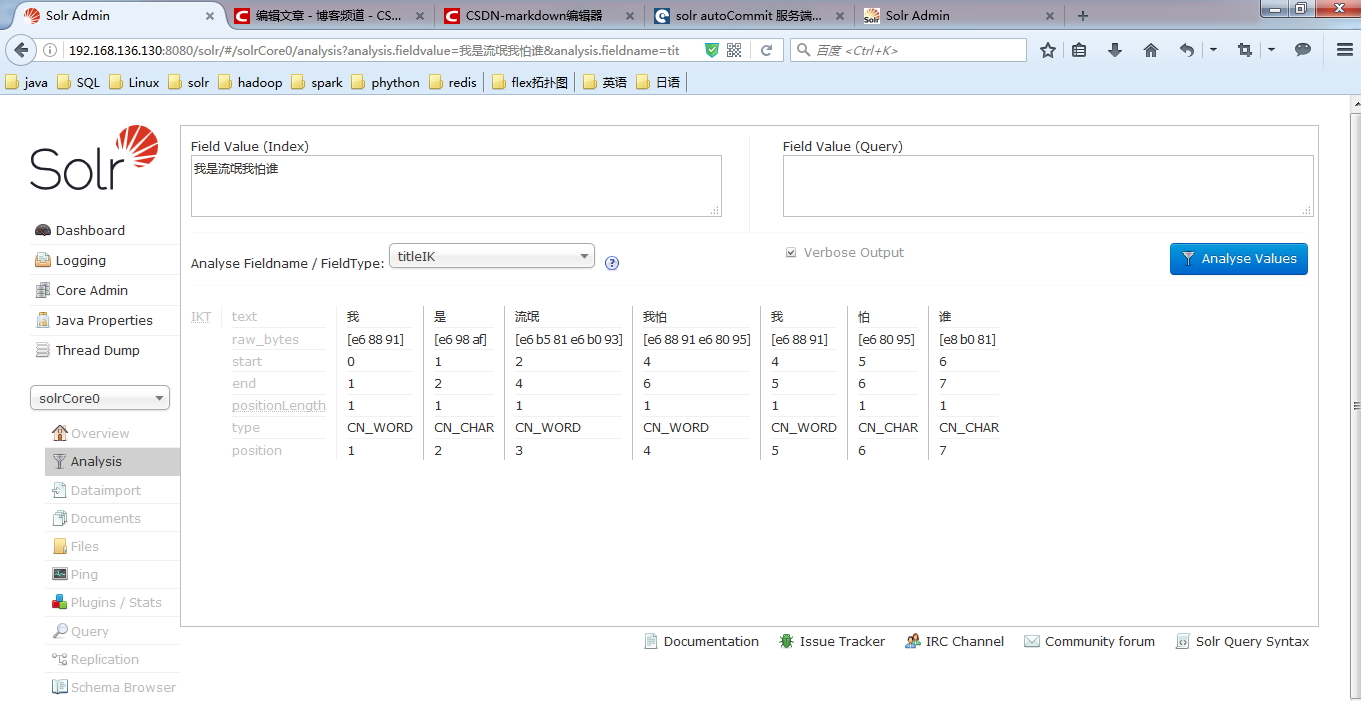
4.4 DataimportHandler
DataimportHandler,它可以把数据从关系数据库中查询出来,然后倒入到索引库中。自己去研究、觉得实际用处不大就没尝试。
五:Solrj的使用
5.1 什么是solrj
Solrj是访问solr服务的java程序客户端。
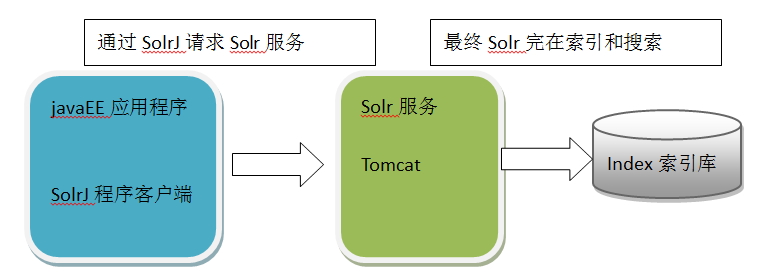
5.2 需求
使用solrj调用solr服务实现对索引库的增删改查操作。
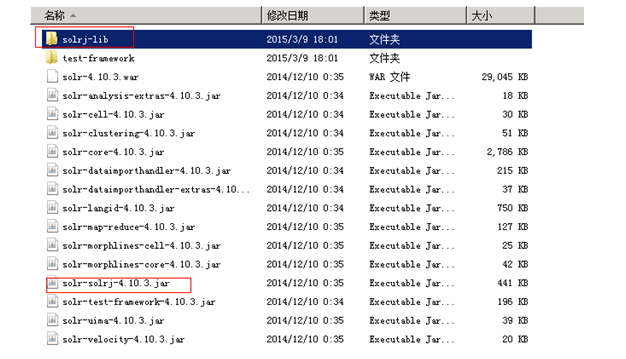
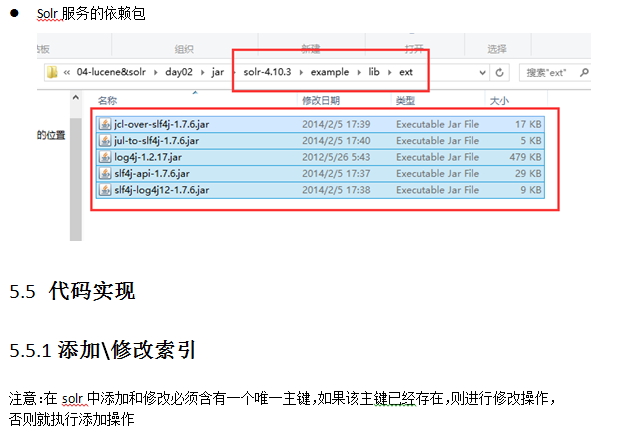
5.3 环境准备
说明:我的solr版本是5.2.0,以下版本4.10.3。但solrJ的使用都是一致的。以下会有很多特殊字符博客转换比较麻烦、因此直接拿之前的文档截图

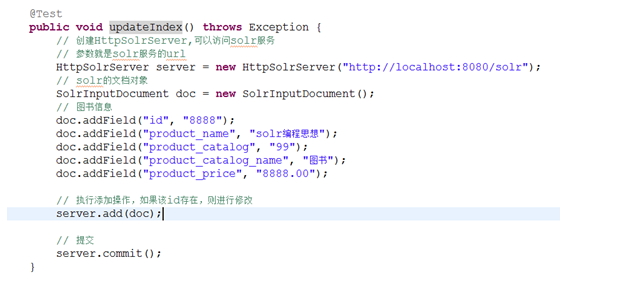
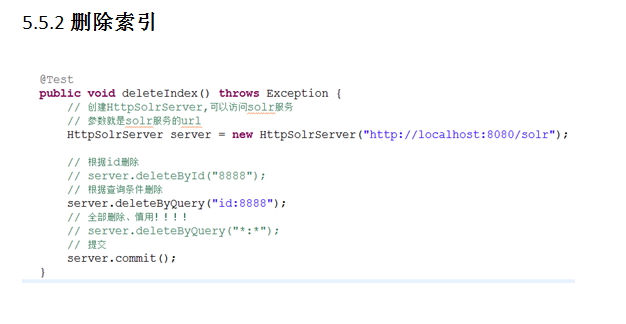
public class IndexSearch {
@Test
public void search() throws Exception {
// 创建HttpSolrServer,可以访问solr服务
// 参数就是solr服务的url
HttpSolrServer server = new HttpSolrServer("http://localhost:8080/solr");
// 创建solrQuery对象
SolrQuery query = new SolrQuery();
// 设置q,查询条件
query.set("q", "product_name:小黄人");
// 设置fq,过滤查询条件
query.set("fq", "product_catalog_name:幽默杂货");
// 设置sort,排序
query.set("sort", "product_price desc");
// 设置start、rows,分页信息(写上默认值)
query.setStart(0);
query.setRows(10);
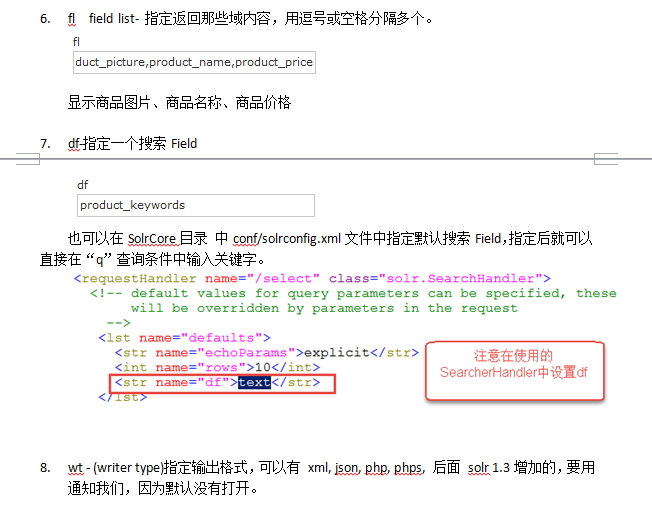
// 设置fl,即要显示的域的列表
// query.set("fl", "");
// 设置df"
query.set("df", "product_keywords");
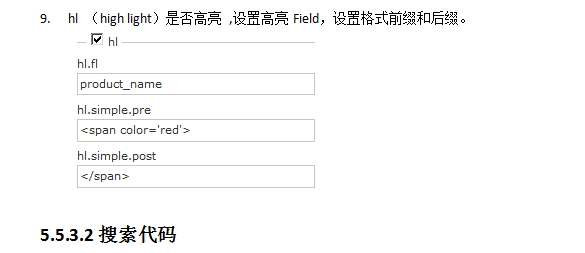
// 设置高亮
query.setHighlight(true);
query.addHighlightField("product_name");
query.setHighlightSimplePre("<font style=\"color:red\">");
query.setHighlightSimplePost("</font>");
// 执行搜索,并获得返回值
QueryResponse response = server.query(query);
// 根据查询条件匹配出的结果对象
SolrDocumentList list = response.getResults();
// 匹配出的结果总数
long count = list.getNumFound();
System.out.println("匹配出的结果总数:" + count);
//获取高亮信息
Map<String, Map<String, List<String>>> highlighting = response.getHighlighting();
for (SolrDocument solrDocument : list) {
System.out.println("商品id:" + solrDocument.get("id"));
System.out.println("商品名称:" + solrDocument.get("product_name"));
System.out.println("商品分类:" + solrDocument.get("product_catalog"));
System.out.println("商品分类名称:"
+ solrDocument.get("product_catalog_name"));
System.out.println("商品价格:" + solrDocument.get("product_price"));
// System.out.println("商品描述:"+solrDocument.get("product_description"));
System.out.println("商品图片地址:" + solrDocument.get("product_picture"));
List<String> list2 = highlighting.get(solrDocument.get("id")).get("product_name");
if(list2!=null){
System.out.println("高亮后的信息:"+list2.get(0));
}
}
}
}
六: hbase + solr代码示例
6.1插入hbase的同时向solr中添加索引
是不是感觉很别扭、hbase增、删、改的同时还要修改solr索引。CDH版hbase-indexer解决了hbase增、删、改solr自动关联问题。请查看hbase-indexer那篇博客…
/**
* 插入Hbase的同时向solr中添加索引
* @throws Exception
*/
public static void put() throws Exception {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd H:m:s");
HttpSolrServer solrServer = new HttpSolrServer(
"http://192.168.136.130:8080/solr/solrCore0");
List<Map<String,String>> dataList = new ArrayList<Map<String,String>>();
System.out.println("============start======" + format.format(new Date()));
String[] relation = {"friend","colleague"};
String[] loanlevel = {"1","2","3","4","5"};
for(int i=0;i<1000000;i++){
//
String f1Str = (int)(Math.random()*1000000) + "";
String f2Str = relation[((int)(Math.random()*2))];
String f3Str = loanlevel[((int)(Math.random()*5))];
// 插入Hbase
Map<String, String> mapData = new HashMap<String,String>();
mapData.put("rowKey", "rk" + i);
mapData.put("f1", f1Str);
mapData.put("f2", f2Str);
mapData.put("f3", f3Str);
dataList.add(mapData);
mapData = null;
// 插入solr
SolrInputDocument solrDoc = new SolrInputDocument();
solrDoc.addField("rowkey", "rk" + i);
solrDoc.addField("f1", f1Str);
solrDoc.addField("f2", f2Str);
solrDoc.addField("f3", f3Str);
solrServer.add(solrDoc);
solrDoc.clear();
solrDoc = null;
}
HBaseUtil.insertBatch("student", "info", dataList);
solrServer.commit(true, true, true);
System.out.println("=======111====end========" + format.format(new Date()));
}6.2在solr中通过索引得到rowkey、拿到rowkey去hbase中取数据
final Configuration conf;
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd H:m:s");
HttpSolrServer server = new HttpSolrServer("http://192.168.136.130:8080/solr/solrCore0");
HTable table = HBaseUtil.getNewTable("student");
Get get = null;
List<Get> list = new ArrayList<Get>();
// solr查询条件
SolrQuery query = new SolrQuery("f2:colleague AND f3:3");
query.setStart(0); //数据起始行,分页用
query.setRows(100); //返回记录数,分页用
QueryResponse response = server.query(query);
SolrDocumentList docs = response.getResults();
// 获得rowkey集合
for (SolrDocument doc : docs) {
get = new Get(Bytes.toBytes((String) doc.getFieldValue("rowkey")));
list.add(get);
}
// 通过rowkey集合在hbase取数据
Result[] res = table.get(list);
int i = 0;
for (Result rs : res) {
i++;
if(i < 4){
log.info("=======================result====:" + rs.toString());
}
}
table.close();













 7641
7641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









