






IT管理者本来寄希望于SOA解决系统运维中的一些问题,而这个治病的良药,偏偏又可能带来新的疾病,如网银因系统拥堵而变慢。如何克服SOA架构下的新问题,也就成了IT管理者所要面临的首要任务。
系统运行维护一直是企业IT部门的重头戏,而在银行这样拥有众多应用系统的大型企业,运维问题显得更加突出。当SOA架构出现时,银行的科技部又不得不去面临一些崭新的难题。他们本来寄希望SOA解决系统运维中的一些问题,而这个治病的良药,偏偏又会带来了副作用,如何在SOA架构下克服这些不良反应,也就成了IT管理者所要面临的首要任务。
业务高峰期的拥堵
系统拥堵是经常会看到的场景。以网银系统为例,上午10点钟左右,是一天中最为集中的业务高峰,网银系统发生了拥堵,造成的问题是客户不能正常访问和登录。在实际工作中,首先能够发现问题的往往不是IT运维部门,而是客户服务部门,因为他们接到了大量的客户投诉以及抱怨,当问题不断发现和积累之后才逐步上报到IT管理者手中,然后运维部门才能予以解决。
这时,系统堵塞已发生半个小时之久,并造成了较为广泛的不良影响。为什么运维人员没能及时发现问题呢?其实,这不是他们工作不负责任,也不是领导的玩忽职守。网银系统拥堵的原因并非出现在某个系统上,而是出现在SOA整合之后,多个系统并行和协同的处理引起了系统拥堵。
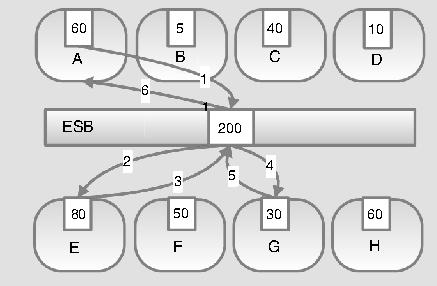
通过一个服务链路的示意图,网银系统拥堵的原因更容易被理解。如图所示,A、B、C、D是银行的客户服务渠道,E、F、G、H都是后台应用系统。假设A是网银渠道,银行客户在A渠道上提交的服务请求被发送到ESB上,服务总线将请求进行处理和转换之后,再发送到其他的后台应用系统E和G,可能是一个,也可能是多个,而且其中要保证整个服务和事务的一致性,最后再将应答返回给渠道系统A。
经分析,笔者发现每个应用系统都会存在自己的流量控制、超时控制、安全控制和用户访问控制。因为经过了上线前的集成测试和压力测试,所以点对点地去访问某一个系统是不会有任何问题的。可是当通过SOA进行系统整合之后,却发现各个系统之间的控制参数设置,并不是最优的,甚至会造成互相矛盾和制约。
如图所示,系统A、B、C、D、E、F、G、H所设定的流量控制值分别是60、5、40、10、80、50、30、60,ESB的流量控制值是200。如果现在A系统流量值达到了60的峰值,执行1~4步骤时,整个系统的服务都是正常的,但是由于G系统的设定值有限,大于30的并发服务请求被G系统拒绝,从而导致E系统需要做回滚处理、A系统的用户服务请求造成堵塞。这样来看,A系统设定的60并发流量是存在风险隐患的,在目前G系统不能提升处理能力的情况下,只能设定为30,这就是所谓的木桶短板效应。
参数设置难题
前面列举的只是最为简单的例子,其实在实际工作中所面临的问题更为复杂、困难。针对SOA架构所带来的改变,运维管理上带来的困扰主要体现在参数设置和系统监控两个方面。
系统参数的设置不尽合理的原因主要有六个方面。
第一,各系统建设和运行维护都是靠独立的项目组来完成,各自形成了一套自成体系的流量和超时控制方法,可是当多个系统并行运行在SOA架构下的时候,没有一个统一的规则和机制来进行管理,必然会造成系统的整体运行不够协调和匹配。
第二,各系统的控制参数都是根据当初自身的处理能力评估值来设定的,可是这些评估值与实际系统运行态的访问压力相比来说相去甚远,这也是导致系统运行效率低下的原因之一。
第三,在正常交易状况下,系统整体是稳定运行的,可是当访问量增大系统拥堵发生时,服务一旦被拒绝,必然会产生大量的冲正服务来占用通道流量,影响了其他正常服务请求。
第四,各个系统过于强调自我保护机制,运维人员希望能够把系统安全风险降到最低,所以在设定系统参数时,会尽量考虑配置到系统承载能力的下限。可是从整体应用上来讲,保守的参数设置并不足以满足系统的访问压力,从而降低了整体SOA架构的系统资源利用率。
第五,从SOA架构整体运行来看,并不能在拥堵发生时,发现在某个系统内发生的是系统故障还是系统过载,而对于这两种情况,运维人员完全会采取不同的处理方式。对于系统故障,应该采用系统隔离和故障修复的方式,而对于系统过载,是可以采用降低压力和过载分流来进行处理。而在目前状况下,这两种情况是难以区分的。
第六,没有结合故障隔离机制,也就是在系统故障发生时,需要将堵塞的服务请求进行隔离,避免影响正常的用户访问,而且单点所造成的系统堵塞很容易扩散到整个SOA架构中的相关系统中,导致所有的服务请求受到影响。
多系统监控难题
部署SOA后,原本不完善的系统监控和预警机制可能会暴露出更多的问题。
第一,原有的应用系统自身都带有监控管理,监控功能是作为系统的一个附加组件来进行部署的,而没有统一集中到一个管理和操作平台上。
第二,随着系统之间的关联性不断增强,在运维人员的监控平台上,就需要同时打开多个监视界面才能及时跟踪系统的运行状况,需要操作者烦琐地登录多个不同的界面来进行操作和分析,从而造成了很多问题并不能够及时地被发现和解决。
第三,即使在单一系统内,监控数据来源的方式也是多种多样的。为了便捷,有的通过UNIX的SHELL脚本来进行监控,有的采取直接跟踪系统日志文件的方法,对于那些基于中间件的系统,也可以通过Weblogic或者Websphere的监控界面,而通过系统自身整合的IE界面来进行系统监控的方式已经算是凤毛麟角了。因此,运维人员就要深入了解系统内部的状况,当发生问题时,需要查询几处日志或者打开几个监控界面之后才能定位问题,这大大降低了工作效率。
在SOA架构建立起来之后,SOA系统不只是简单将各个系统技术平台进行整合,还存在大量业务整合和运维管理问题。一个服务流程的处理会涉及到多个业务处理主体,涉及到多个部门的统一配合和业务协作。
从上面的问题分析中,笔者发现银行SOA系统运维中的问题,大多并不是发生在正常运行的情况下,而是发生在系统堵塞和故障时,而这些特殊状况是难以进行预期和评估的,所以需要在实际工作中不断总结和完善。
对运维管理的关注是在系统SOA部署之后的重点,但值得银行科技部注意的是:运维管理体系的创建只有被提前到SOA项目的规划、建模和工程实施的时候,才能确保未来部署的服务和组合应用能够被真正地管理。运维管理涉及到的系统有3类,1.服务工程规范有效性度量体系:服务计分卡、服务重用评价、一致性度量、交付效率等;2.基础设施运行度量体系:服务水平协议 (SLA) 、审计信息、服务使用率、异常及失败、服务消费能力;3.业务流程度量体系:业务活动监控、SLA目标、异常及失败统计监控。
在SOA的部署过程中,旧的业务流程要优化、旧的系统要调整、旧的管理制度要废除,那么运维管理当然也不能固步自封,需要在新的体系下,制定新的规范、部署新的人员,建设新的监控预警平台。
总而言之,SOA将会让现有的IT系统发生改变,带来系统互连互通的优势。在SOA架构下,IT运维部门再也不能只从单系统角度去考虑运维问题,而需要从整个架构的宏观管理层面去改变旧有的工作模式。银行科技部门只有让改变后的系统能够正常和稳定地运行,才能将SOA的优势落到实处,才能让银行真正的在架构优化调整中受益。














 3248
3248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









