







 本文深入探讨Netty框架中HTTP协议的高效解析机制,重点分析keep-alive、gzip压缩及chunked传输编码等内容,揭示Netty如何实现高性能HTTP数据处理。
本文深入探讨Netty框架中HTTP协议的高效解析机制,重点分析keep-alive、gzip压缩及chunked传输编码等内容,揭示Netty如何实现高性能HTTP数据处理。
本文主要介绍netty对http协议解析原理,着重讲解keep-alive,gzip,truncked等机制,详细描述了netty如何实现对http解析的高性能。
1 http协议
1.1 描述
| 标示 | ASCII | 描述 | 字符 |
|---|---|---|---|
| CR | 13 | Carriage return (回车) | \n |
| LF | 10 | Line feed character(换行) | \r |
| SP | 32 | Horizontal space(空格) | |
| COLON | 58 | COLON(冒号) | : |
http协议主要使用CRLF进行分割。
1.2 请求包
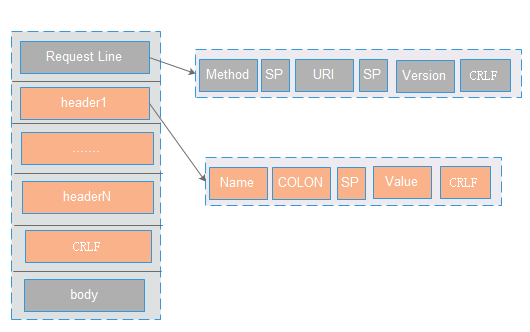
主要包含三部分:请求行(line),请求头(header),请求正文(body)
请求行(Line):主要包含三部分:Method ,URI ,协议/版本。 各部分之间使用空格(SP)分割。整个请求头使用CRLF分割。(比如:POST /1.0.0/_health_check HTTP/1.1 CRLF)
请求头(Header): 格式为(name :value),用于客户端请求的描述信息。header之间以CRLF进行分割。最后一个header会多加一个CRLF。( 比如:Connection: keep-alive CRLF CRLF)
请求正文(body) :里面主要是Post提交的数据(可支持多种格式,格式在Content-Type定义,长度是在Content-Length里面定义)。
1.3 响应包
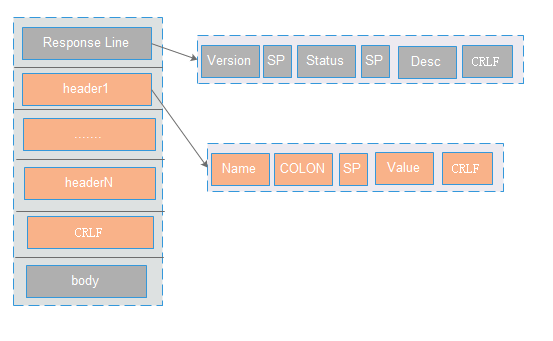
主要包含三部分:状态行(line),响应头(header),响应正文(body)
状态行(line):包含三部分:http版本,服务器返回状态码,描述信息。以CRLF进行分割。 ( 比如:HTTP/1.1 200 OK CRLF)
响应头(header) : 格式为(name :value),用于服务器返回的描述信息。header之间以CRLF进行分割。最后一个header会多加一个CRLF (比如:Content-Type: text/html CRLF Content-Encoding:gzip CRLF CRLF)
响应正文(body):里面主要是返回数据(可支持多种格式,格式在Content-Type定义,长度是在Content-Length里面定义)。
2 chunked介绍
2.1 背景
HTTP协议通常使用Content-Length来标识body的长度,在服务器端,需要先申请对应长度的buffer,然后再赋值。如果需要一边生产数据一边发送数据,就需要使用"Transfer-Encoding: chunked" 来代替Content-Length,也就是对数据进行分块传输。
2.2 Content-Length描述
1:http server接收数据时,发现header中有Content-Length属性,则读取Content-Length 的值,确定需要读取body的长度。
2:http server发送数据时,根据需要发送byte的长度,在header中增加 Content-Length 项,其中value为byte的长度,然后将byte数据当做body发送到客户端。
2.3 chunked描述
1:http server接收数据时,发现header中有Transfer-Encoding: chunked,则会按照truncked协议分批读取数据。
2:http server发送数据时,如果需要分批发送到客户端,则需要在header中加上 Transfer-Encoding: chunked,然后按照truncked协议分批发送数据。
2.4 truncked协议
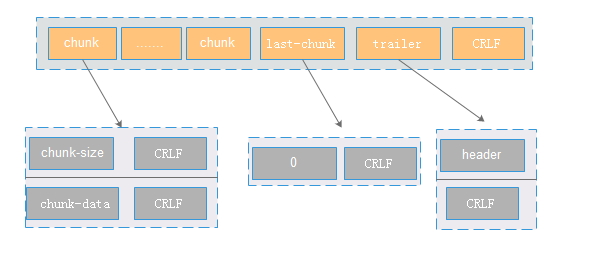
1:主要包含三部分:chunk,last-chunk和trailer。如果分多次发送,则chunk有多份。
2:chunk主要包含大小和数据,大小表示这个这个trunck包的大小,使用16进制标示。其中trunk之间的分隔符为CRLF。
3:通过last-chunk来标识chunk发送完成。 一般读取到last-chunk(内容为0)的时候,代表chunk发送完成。
4:trailer 表示增加header等额外信息,一般情况下header是空。通过CRLF来标识整个chunked数据发送完成。
2.5 优点
1:假如body的长度是10K,对于Content-Length则需要申请10K连续的buffer,而对于Transfer-Encoding: chunked可以申请1k的空间,然后循环使用10次。节省了内存空间的开销。
2:如果内容的长度不可知,则可使用trunked方式能有效的解决Content-Length的问题
3:http服务器压缩可以采用分块压缩,而不是整个快压缩。分块压缩可以一边进行压缩,一般发送数据,来加快数据的传输时间。
2.6 缺点
1:truncked 协议解析比较复杂。
2:在http转发的场景下(比如nginx) 难以处理,比如如何对分块数据进行转发。
3 压缩
3.1 背景
在http请求(特别是移动端),如果请求的资源比较多,则网络的开销会比较大,用户体验较差。则可以开启数据的无损压缩,节省传输的流量,提升数据的加载性能。
3.2 压缩类型
1:压缩需要客户端,服务器端同时支持。在chrome中,请求默认会加上Accept-Encoding: gzip, deflate,客户端默认开启数据压缩。而tomcat默认关闭压缩,如果开启需要增加配置。
2:在请求时,需要通过header的Accept-Encoding: gzip, deflate 来告诉服务器客户端支持的压缩类型。
3:在返回时,http server会在返回的header中添加Content-Encoding: gzip 来告诉客户端数据的压缩方式。
4:压缩类型主要包含如下几种:
gzip 说明body采用GNU zip编码
compress 说明body采用Unix的文件压缩程序
deflate 说明body是用zlib的格式压缩的
identity 说明没有对实体进行编码。
其中 gzip, compress, 以及deflate编码都是无损压缩算法,不会导致信息损失。 gzip效率最高,使用较为广泛。
3.3 tomcat实现
tomcat默认是关闭gzip压缩,开启需要在server.xml中的Connector标签中加如下配置:
compression=”on” 打开压缩功能;
compressionMinSize=”2048″ 启用压缩的阈值,只有数据量小于2048 才会对内容进行压缩;
noCompressionUserAgents=”gozilla, traviata” 对于以下的浏览器,不启用压缩 ;
compressableMimeType="text/html,text/xml,text/plain,text/css,text/javascript,text/json,application/x-javascript,application/javascript,application/json" 压缩类,只有Content-Type为设置的类型,才会进行压缩。
是否进行压缩主要是从:数据的大小,浏览器的类型和内容的类型来控制。
3.4 优点
减少流量,帮公司节省带宽及流量,帮用户节省流量
客户端(特别是移动端),加载速度变快,提升用户体验。
3.5 缺点
服务器端需要更多的cpu资源进行计算,会降低服务器的整体吞吐量
服务器端需要多申请更多的内存资源。数据1k的话,不开启压缩,只需要申请1k的buffer; 而开启压缩的话(假设压缩后的大小为250B),则需要多申请250B的buffer,并且涉及到数据的拷贝
客户端也需要消耗更多的cpu来进行数据的解压缩。
4 keepalive
具体可参考: http://blog.csdn.net/hetaohappy/article/details/51851880
5 粘包,拆包
5.1背景
TCP是基于stream机制,其实就是一串没有边界的数据流。 这里主要面临两个问题:1:如何定义数据的边界 2:拆包和粘包的问题。HTTP协议是基于TCP,所以也会面临前面两个问题。
5.2 数据读取流程
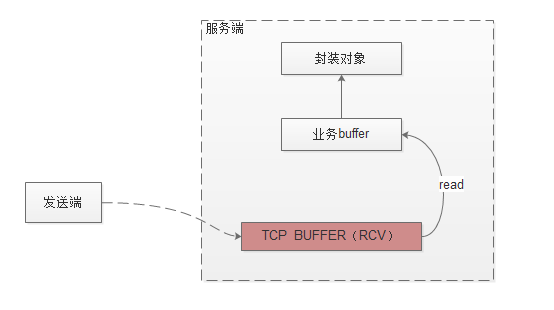
1:发送端发送数据,数据先通过网卡到服务端tcp的receive buffer中。服务端的上层应用如果需要读取数据,会申请一段业务buffer,调用JDK的IO接口,IO会将tcpreceive buffer的数据拷贝到业务的buffer里面。上层业务再通过设定的反序列化协议将业务buffer转换成对象进行业务处理。
2:服务端读取数据时,先申请一段业务buffer(大小一般是1k),通过调用JDK的channel.read(buffer) IO方法,IO会将tcp buffer的数据拷贝到业务buffer里面。返回值为读取字节的个数:如果返回值大于0,说明读取到了对应大小的数据;如果是0,表示没有读到数据,数据读取完成(可能业务buffer是满的,不能往里面写数据);如果是-1,代表tcp连接被关闭(一般处理是关闭到该连接)
3:在java里面可以设置socket的SO_RCVBUF 参数来设置buffer的大小。默认值保存在:cat /proc/sys/net/core/rmem_default 也可通过cat /proc/sys/net/ipv4/tcp_wmem查看。
5.3 粘包拆包说明

说明:假如服务端连续接收了4个包。 应用申请1k的buffer空间去读取tcp数据。读取的流程如下。
1:业务先申请1k大小的业务buffer,先调用JDK IO接口,会拷贝Receive Buffer的1k数据到业务的buffer里面。
2:每个包定义有边界。通过边界定义,读取到包1和包2分别进行反序列化的处理,转换为对象供上层应用处理。(解决粘包的问题)
3:如下图:在读取到包3的时候,由于把buffer读完还没有发现边界。便将包3(剩下的10个)的数据拷贝到buffer的最前端。然后再调用JDK IO接口,tcp receive buffer拷贝数据是从业务buffer的第10个位置进行拷贝赋值。拷贝完后再读取包3的数据,直到边界(解决拆包的问题)

4:然后读取包4,发现到边界后,并且数据没有可读的,则整个流程结束。
5.4 http解决方案:
1:请求行的边界是CRLF,如果读取到CRLF,则意味着请求行的信息已经读取完成。
2:Header的边界是CRLF,如果连续读取两个CRLF,则意味着header的信息读取完成。
3:body的长度是有Content-Length 来进行确定。如果没有Content-Length ,则是chunked协议(具体参考前面的trunked协议)。
6 netty实现
6.1 http协议实现的抽象
很多http server(比如tomcat,resin)的实现都是基于servlet,但是netty对http实现并没有基于servlet。
下面将对请求request的抽象进行描述。 response对象的抽象比较类似,将不做描述。
:
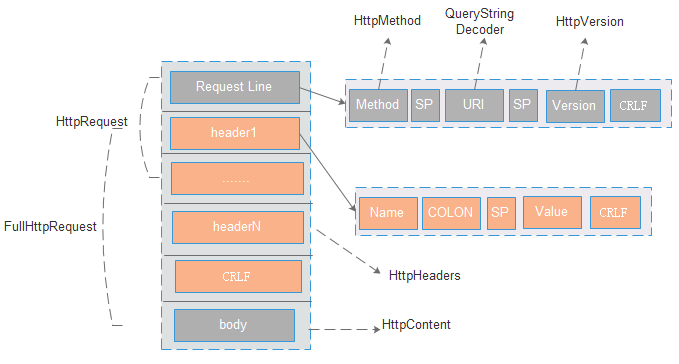
HttpMethod:主要是对method的封装,包含method序列化的操作
HttpVersion: 对version的封装,netty包含1.0和1.1的版本
QueryStringDecoder: 主要是对url进行封装,解析path和url上面的参数。(Tips:在tomcat中如果提交的post请求是application/x-www-form-urlencoded,则getParameter获取的是包含url后面和body里面所有的参数,而在netty中,获取的仅仅是url上面的参数)
HttpHeaders:包含对header的内容进行封装及操作
HttpContent:是对body进行封装,本质上就是一个ByteBuf。如果ByteBuf的长度是固定的,则请求的body过大,可能包含多个HttpContent,其中最后一个为LastHttpContent(空的HttpContent),用来说明body的结束。
HttpRequest:主要包含对Request Line和Header的组合
FullHttpRequest: 主要包含对HttpRequest和httpContent的组合
6.2 request的流程处理
6.2.1 实现:
只需要在netty的pipeLine中配置HttpRequestDecoder和HttpObjectAggregator。
6.2.2 原理:
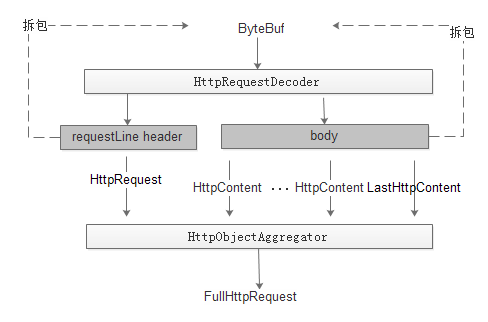
1:如果把解析这块理解是一个黑盒的话,则输入是ByteBuf,输出是FullHttpRequest。通过该对象便可获取到所有与http协议有关的信息。
2:HttpRequestDecoder先通过RequestLine和Header解析成HttpRequest对象,传入到HttpObjectAggregator。然后再通过body解析出httpContent对象,传入到HttpObjectAggregator。当HttpObjectAggregator发现是LastHttpContent,则代表http协议解析完成,封装FullHttpRequest。
3:对于body内容的读取涉及到Content-Length和trunked两种方式。两种方式只是在解析协议时处理的不一致,最终输出是一致的。
6.2.3 面临的问题:
1:假设申请的ByteBuf为1k,如果读取request Line,把ByteBuf都读取完了还没有发现边界(CRLF),如何处理?
一般的做法为:先申请1k大小的ByteBuf,如果发现当前ByteBuf大小不够。 一般会再申请之前大小2倍的ByteBuf(也就是2k),然后把之前1k的数据拷贝到新申请的2k的空间里面,然后再到JDK的io中读取数据。如果再不够用,则再申请2倍的byteBuf。 如果数据量比较大,会面临着申请新空间->拷贝数据->申请更大的空间->再拷贝数据.... 。该种方案性能极其低下,如何提升性能?
2:如果申请的buffer在堆上面,由于该buffer存活周期很短,会造成频繁的GC,影响系统性能。
6.2.4 性能优化:
1:使用堆外内存,也就是DirectBuffer。来减少GC的次数。
2:使用buffer pool,避免频繁的申请及释放内存。一般pool有两层,ThreadLocal的pool和全局的pool。 申请buffer空间时,先看ThreadLocal是否有未使用的buffer,如果没有,再从全局的pool中获取buffer。一般的内存管理策略是pool里面的buffer大小全部一致(比如1k),但是 如果需要申请2k的空间,必须要新建2k空间的buffer。如果频繁申请大于1K空间内存,则性能比较低下。 netty为了解决该问题,使用了较为复杂的内存管理策略,具体可参考 http://blog.csdn.net/youaremoon/article/details/47910971
3:零拷贝:前面提到拷贝数据的性能问题,采用零拷贝机制可有效解决该问题
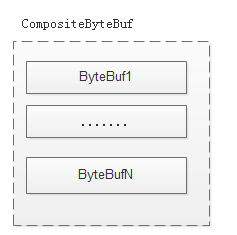
CompositeByteBuf(组合): 比如读取request Line,申请1k的空间ByteBuf,如果没有发现边界(CRLF)。再申请1k的空间ByteBuf到JDK的io中读取数据。将老的ByteBuf和新申请的ByteBuf组合成CompositeByteBuf,更改CompositeByteBuf的读写指针来避免数据的拷贝。
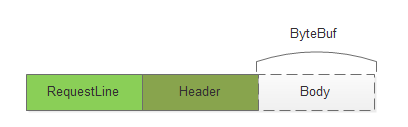
slice(切分): 比如在1k的ByteBuf里面先读取requestLine,Header进行解析对象,最后读取body。由于body的数据还需要保存在内存里面供业务使用。一般的做法是新申请一块空间,将body的数据拷贝到新申请的空间上。这里通过虚拟一个ByteBuf,然后将读写的指针指向真实的ByteBuf的body区域上面,来避免数据的拷贝。
6.3 response的流程处理
6.3.1实现
只需要在netty的pipeLine中配置HttpResponseEncoder
6.3.2原理
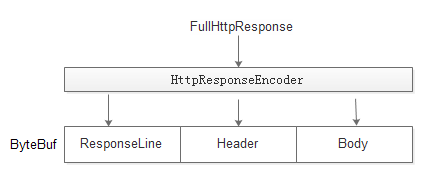
1:输入是FullHttpResponse对象,输出是ByteBuf。socket再将ByteBuf数据发送到访问端。
2:对FullHttpResponse按照http协议进行序列化。判断header里面是ContentLength还是Trunked,然后body按照相应的协议进行序列化。
3:具体原理和request请求方式比较类似,这次不再详细描述。
6.4 压缩实现
6.4.1 实现
在HttpResponseEncoder之前加上 HttpContentCompressor 。response对象先进过HttpContentCompressor 压缩后,再经过HttpResponseEncoder进行序列化。
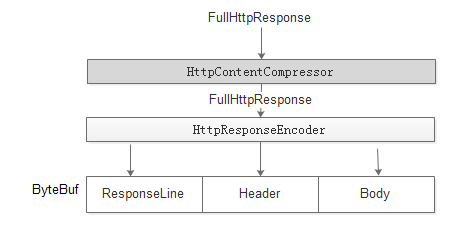
1:压缩主要是针对body进行压缩。http1.1不支持对header的压缩。
2:压缩后body的输出是trunked,而不是Content-length的形式。
6.4.2 Gzip格式
gzip压缩后主要包含三部分:

gzip头:主要存储的是gzip的压缩方式
deflate编码:内容采用的是deflate压缩算法
gzip尾:主要是采用CRC32算法对编码内容进行校验。
7 安全配置
| 参数 | 推荐 | 返回错误码 | 描述 |
|---|---|---|---|
| requst Line size | 2k | 414 | 主要是限制url的长度 |
| header size | 4k | 414 | 避免header过长 |
| body size | 60M | 413 | 此处一般和业务关联,一般设置相对较大 |
| keepalive timeout | 75 | 如果连接在设定时间内没有使用,则关闭掉连接,避免维护的连接过多 |
GET和POST的区别,笔者之前理解的其中一项是:get的url长度有限制,post的body长度没有限制。
其实这种理解是有偏差的:不管是url长度限制或者body长度限制都是有后端http容器配置的。 body的长度限制一般比get的url长度限制稍大。


















 8804
8804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











