






HashTable和HashMap的区别
在面试的过程中,经常会被问到HashTable和HashMap的区别,下面就这些区别做一个简单的总结。
1、继承的父类不同
Hashtable继承自Dictionary类,而HashMap继承自AbstractMap类,但二者都实现了Map接口。
2、线程安全性不同
Hashtable 中的方法是Synchronize的,而HashMap中的方法在缺省情况下是非Synchronize的。在多线程并发的环境下,可以直接使用Hashtable,不需要自己为它的方法实现同步,但使用HashMap时就必须要自己增加同步处理。
总结一句话:Hashtable(1.0版本)不建议在新代码中使用,不需要线程安全的场合可以用HashMap替换,需要线程安全的场合可以用ConcurrentHashMap替换。
3、是否提供contains方法
HashMap把Hashtable的contains方法去掉了,改成containsValue和containsKey,因为contains方法容易让人引起误解。
Hashtable则保留了contains,containsValue和containsKey三个方法,其中contains和containsValue功能相同。
4、key和value是否允许null值
Hashtable中,key和value都不允许出现null值。但是如果在Hashtable中有类似put(null,null)的操作,编译同样可以通过,因为key和value都是Object类型,但运行时会抛出NullPointerException异常。
HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,可能是 HashMap中没有该键,也可能使该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键, 而应该用containsKey()方法来判断。
5、遍历的内部实现方式不同
Hashtable、HashMap都使用了 Iterator。但由于历史原因,Hashtable还使用了Enumeration的方式 。
6,数组初始化和扩容方式不同
HashTable在不指定容量的情况下的默认容量为11,而HashMap为16,Hashtable不要求底层数组的容量一定要为2的整数次幂,而HashMap则要求一定为2的整数次幂。
具体扩容时,Hashtable将容量变为原来的2倍加1,而HashMap扩容时,将容量变为原来的2倍。
HashTable
由于HashTable的性能问题,在实际编程中HashTable并不是很常见,更多的是使用HashMap或ConcurrentHashMap。
简单来说,HashTable是一个线程安全的哈希表,它通过使用synchronized关键字来对方法进行加锁,从而保证了线程安全。但这也导致了在单线程环境中效率低下等问题。
HashTable存储模型
HashTable保存数据是和HashMap是相同的,使用的也是Entry对象。HashTable类继承自Dictionary类,实现了Map,Cloneable和java.io.Serializable三个接口,其UML图如下图所示。
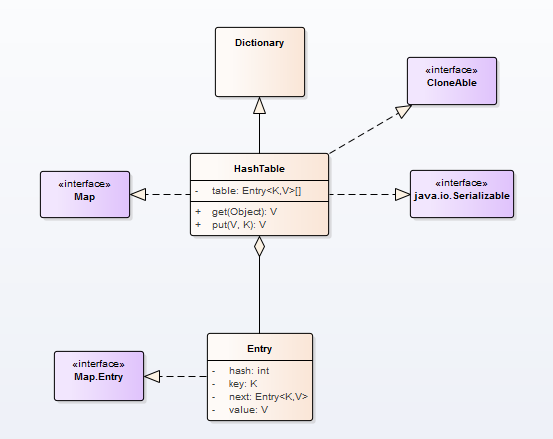
HashTable的功能与与HashMap中的功能相同,主要有:put,get,remove和rehash等。
HashTable的主要方法的源码实现逻辑与HashMap中非常相似,有一点重大区别就是所有的操作都是通过synchronized锁保护的。也就是说,只有获得了对应的锁,才能进行后续的读写等操作。
下面就HashTable常见的方法给大家做一个简单的解析。
构造方法
HashTable的构造方法源码如下:
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry<?,?>[initialCapacity];
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}
public Hashtable() {
this(11, 0.75f);
}从构造函数中可以得到如下的信息:HashTable默认的初始化容量为11(与HashMap不同,HashMap是16),负载因子默认为0.75(与HashMap相同)。而正因为默认初始化容量的不同,同时也没有对容量做调整的策略,所以可以先推断出,HashTable使用的哈希函数跟HashMap是不一样的。
put
put方法的主要逻辑如下:
- 先获取synchronized锁;
- put方法不允许null值,如果发现是null,则直接抛出异常;
- 计算key的哈希值和index;
- 遍历对应位置的链表,如果发现已经存在相同的hash和key,则更新value,并返回旧值;
- 如果不存在相同的key的Entry节点,则调用addEntry方法增加节点;
- addEntry方法中,如果需要则进行扩容,之后添加新节点到链表头部。
Put方法的源码如下:
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
//计算桶的位置
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
//遍历桶中的元素,判断是否存在相同的key
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
//不存在相同的key,则把该key插入到桶中
addEntry(hash, key, value, index);
return null;
}
涉及的Entry对象的源码如下:
private void addEntry(int hash, K key, V value, int index) {
modCount++;
Entry<?,?> tab[] = table;
//哈希表的键值对个数达到了阈值,则进行扩容
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) tab[index];
//把新节点插入桶中(头插法)
tab[index] = new Entry<>(hash, key, value, e);
count++;
}从上面的源码可以看到,put方法一开始就会进行值的null值检测,同时,HashTable的put方法也是使用synchronized来修饰。你可以发现,在HashTable中,几乎所有的方法都使用了synchronized来保证线程安全。
get
get方法的主要逻辑如下:
- 先获取synchronized锁;
- 计算key的哈希值和index;
- 在对应位置的链表中寻找具有相同hash和key的节点,返回节点的value;
- 如果遍历结束都没有找到节点,则返回null。
get函数的源码如下:
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
//通过哈希函数,计算出key对应的桶的位置
int index = (hash & 0x7FFFFFFF) % tab.length;
//遍历该桶的所有元素,寻找该key
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}从上面的代码可以发现,get方法使用了synchronized来修饰,以保证线程的安全,并且它是通过链表的方式来处理冲突的。另外,我们还可以看见HashTable并没有像HashMap那样封装一个哈希函数,而是直接把哈希函数写在了方法中。
rehash扩容
rehash扩容方法主要逻辑如下:
数组长度增加一倍(如果超过上限,则设置成上限值);
更新哈希表的扩容门限值;
遍历旧表中的节点,计算在新表中的index,插入到对应位置链表的头部。
rehash方法的源码如下:
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
//扩容扩为原来的两倍+1
int newCapacity = (oldCapacity << 1) + 1;
//判断是否超过最大容量
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
//计算下一次rehash的阈值
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
//把旧哈希表的键值对重新哈希到新哈希表中去
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}HashTable的rehash方法相当于HashMap的resize方法。跟HashMap那种巧妙的rehash方式相比,HashTable的rehash过程需要对每个键值对都重新计算哈希值,而比起异或和与操作,取模是一个非常耗时的操作。这也是HashTable比HashMap低效的原因之一。
remove
remove方法主要逻辑如下:
- 先获取synchronized锁;
- 计算key的哈希值和index;
- 遍历对应位置的链表,寻找待删除节点,如果存在,用e表示待删除节点,pre表示前驱节点。如果不存在,返回null;
- 更新前驱节点的next,指向e的next。返回待删除节点的value值。
remove函数的源码如下:
public synchronized V remove(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>)tab[index];
for(Entry<K,V> prev = null ; e != null ; prev = e, e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
modCount++;
if (prev != null) {
prev.next = e.next;
} else {
tab[index] = e.next;
}
count--;
V oldValue = e.value;
e.value = null;
return oldValue;
}
}
return null;
}ConcurrentHashMap
HashMap是我们平时开发过程中使用的比较多的集合,但它是非线程安全的,在涉及到多线程并发的情况,进行get操作有可能会引起死循环,导致CPU利用率接近100%。例如:
final HashMap<String, String> map = new HashMap<String, String>(2);
for (int i = 0; i < 10000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
map.put(UUID.randomUUID().toString(), "");
}
}).start();
}
但是解决方法也有很多,如Hashtable和Collections.synchronizedMap(hashMap),不过这两个方案基本上是对读写进行加锁操作,一个线程在读写元素,其余线程必须等待,性能可想而知。此时,可以使用ConcurrentHashMap来解决。
JDK 1.7 ConcurrentHashMap实现
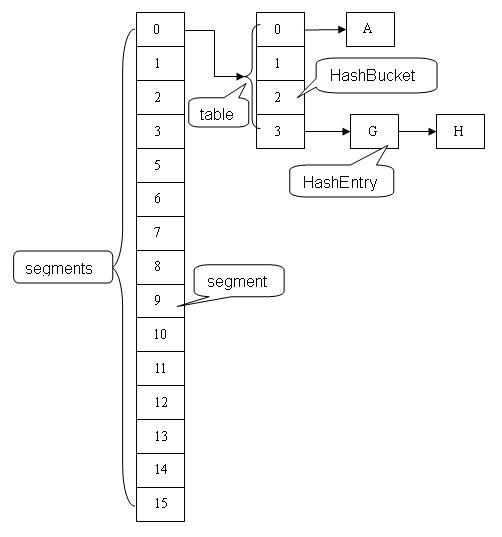
和HashMap不同,ConcurrentHashMap采用分段锁的机制,实现并发的更新操作,底层采用数组+链表的存储结构。ConcurrentHashMap最核心的两个核心静态内部类包括:Segment和HashEntry。
理解ConcurrentHashMap需要注意如下几个概念:
- Segment继承ReentrantLock用来充当锁的角色,每个 Segment 对象守护每个散列映射表的若干个桶;
- HashEntry 用来封装映射表的键 / 值对;
- 每个桶是由若干个 HashEntry 对象链接起来的链表。
一个 ConcurrentHashMap 实例中包含由若干个 Segment 对象组成的数组,其数据结构如下:
JDK1.8 ConcurrentHashMap实现
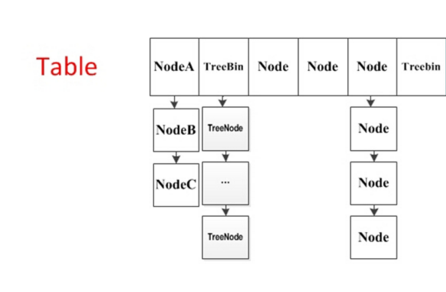
1.8的实现已经抛弃了Segment分段锁机制,而是采用CAS+Synchronized来保证并发更新的安全,底层采用数组+链表+红黑树的存储结构。而HashMap在1.8版本中也对存储结构进行了优化,采用数组+链表+红黑树的方式进行数据存储,红黑树可以有效的平衡二叉树,带来插入、查找性能上的提升。
ConcurrentHashMap在1.8版本的数据存储结构如下图:
初始化
只有在第一次执行put方法时才会调用initTable()初始化Node数组,该方法的源码如下:
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
sizeCtl默认为0,如果ConcurrentHashMap实例化时有传参数,sizeCtl会是一个2的幂次方的值。所以执行第一次put操作的线程会执行Unsafe.compareAndSwapInt方法修改sizeCtl为-1,有且只有一个线程能够修改成功,其它线程通过Thread.yield()让出CPU时间片等待table初始化完成。
关于具体的的一些put、get、table扩容等操作,大家可以自行搜索相关的资料。















 4249
4249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











