







说明:2.0相对1.0的算法改进
首先1.0是用父子节点树来保存树的,一个父对应多个子节点,这就不可避免要使用List来保存子节点,由于List的大小有限制,在1.0的时候加载的数据小于10万条,没有出现List溢出问题。
所以2.0放弃使用父子节点的树,在数据结构上使用了兄弟节点树,也放弃使用List树解决了List溢出问题同时效率与空间的利用提升了一个等级
1.面向应用
最近公司新开发的电商平台,要实现一些违禁词过滤。需求很简单,就是从数据库中读取内容,包括资讯,产品,公司简介之类,看看是否存在违禁词,有的话就把这条记录的ID存入违禁词文档。可以应用于分词库匹配检索,如关键字、敏感词的标识,起到过滤的作用。
2.设计思想
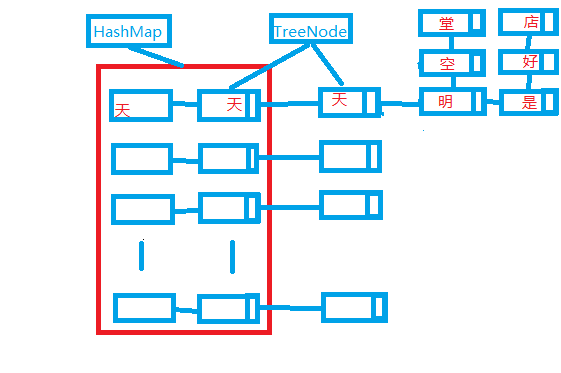
采用了哈希表与树相结合的思想,哈希表中放的是关键词的首字符相同和以该首字符开始的树根节点。
3.方案的优缺点
首先使用了树来保存违禁词,节省了前缀相同汉字的内存空间,以HashMap作为索引提高了匹配的效率。继承了HashMap的快速定位优点,在以树的形式保存关键字,比HashMap节省空间。又因为不同汉字开头的是不同的小树,小树的查询效率比所有的节点挂载在大树上的效率有更大的提高。
4.模拟效果图
节点类
TreeBrother .Class
package HashTree;
import java.io.Serializable;
public class TreeNode implements Serializable {
private int isLast; //是否是关键字结束节点
private String nodeName; //节点名
private TreeNode parentNode; //父节点
private TreeNode brotherNode; //兄弟节点
private TreeNode childNode; //子节点
public int getIsLast() {
return isLast;}
public void setIsLast(int isLast) {
this.isLast = isLast;}
public String getNodeName() {
return nodeName;}
public void setNodeName(String nodeName) {
this.nodeName = nodeName;}
public TreeNode getParentNode() {
return parentNode;}
public void setParentNode(TreeNode parentNode) {
this.parentNode = parentNode;}
public TreeNode getBrotherNode() {
return brotherNode;}
public void setBrotherNode(TreeNode brotherNode) {
this.brotherNode = brotherNode;}
public TreeNode getChildNode() {
return childNode;}
public void setChildNode(TreeNode childNode) {
this.childNode = childNode;}
}树的操作类
TreeHelper.Class
package HashTree;
import jxl.Cell;
import jxl.Sheet;
import jxl.Workbook;
import java.io.*;
import java.util.*;
/**
* Created by Administrator on 2016/3/22.
*
* @version $Revision$ $Date$
* 2016/3/22
* 14:09
* @author: Administrator
* @since 3.0
*/
public class TreeBrother {
private Boolean isExit; //是否存在违禁词
private int maxLength; //记录树的最大长度
private int index; //最大匹配位置
private Map<String, TreeNode> map; //树根索引
private List<String> indexList; //记录关键词的位置
private List<String> valueList; //记录关键词
private int wordCount; //违禁词总数
private int articleLength;
public static void main(String[] args) throws IOException {
TreeBrother treeBrother = new TreeBrother();
//加载树
Long loadStartTime = new Date().getTime();
treeBrother.readXlsBuildTree("F:\\words1.xls");
treeBrother.readXlsBuildTree(1, 1,2,"F:\\words2.xls");
treeBrother.readXlsBuildTree(1, 1,2,"F:\\words3.xls");
treeBrother.readFileBuildTree("F:\\lex-main.lex");
Long loadEndTime = new Date().getTime();
//读取文章
String str = treeBrother.readTxt("F:\\hello.txt");
//查找树
Long searchStartTime = new Date().getTime();
treeBrother.findWordLocation(str);
Long searchEndTime = new Date().getTime();
//显示树的信息
treeBrother.showInfo(loadEndTime-loadStartTime,searchEndTime-searchStartTime);
}
public</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 608
608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









