







学习需要记录,更需要温习!
上一篇我们总结了什么是线性表,线性表的ADT类型,线性表的两种存储类型顺序存储结构和链式存储结构,今天正式进入线性表的顺序存储结构的总结和归纳,也就是数据结构的线性表的顺序表的讲解。
1、什么是顺序表?
顺序表就是用一组连续的存储单元依次存储线性表的数据元素。对应到C语言中也就是一块数组空间,我们都知道当我们声明一个静态数组时,系统就会为我们在栈区开辟一组连续的空间,当然也可以动态在堆区开辟一组空间,同样也是开辟一组连续的空间。这样我们就可以通过下标操作这块空间。所以顺序表的存储数据就是用数组存储我们线性表的数据元素,需要注意,这里的数组不仅仅是基本数据类型,也可以是自定义数据类型的数组。这里需要说明一下,这里提到的堆和栈与我们数据结构中说的堆栈不一样。
2、用代码如何实现顺序表的操作(C/C++语言)
2.1、如何定义结构
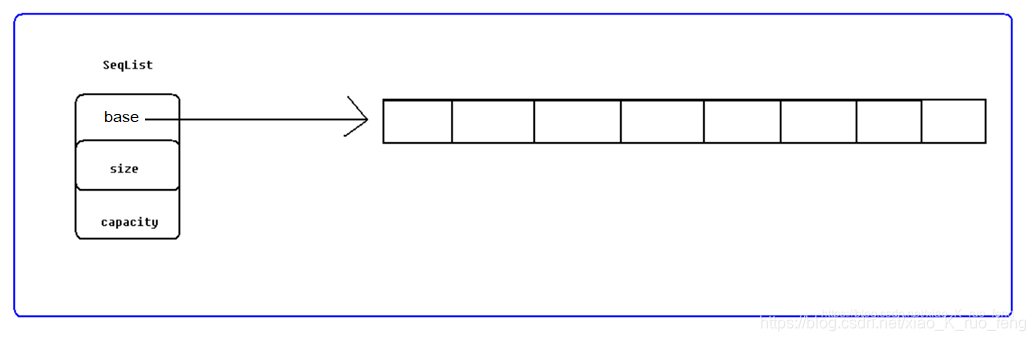
对于顺序表我们采用如图1结构保存顺序表SeqList,其中data指向实际一块连续存储空间,size保存该顺序表实际存储数据的大小,capacity保存该顺序表的容量。有人会问了为什么是这种结构,上一节中ADT已经决定了它的结构,其中data字段是必须的,capacity和size就不是必须的,是我们为了方便管理而添加的字段。该结构对应到C语言就是一个结构体,对应到C++中就是一个类。
data指向的空间在C语言中可以动态开辟也可以静态开辟,类型可以是基本数据类型,也可以是自定义数据类型;有人会注意到采用数组保存数据,存在一个问题,到底是开辟多大空间合适呢?这也是顺序表的缺点之一,但也不是完全不能解决的,现在问题是我们不知道该开辟多大空间,那么我们可以这样做:我们可以先开辟一定空间时候,当开始开辟的空间不足时(系统内存还有时),我们重新申请一块比原来大空间,将原有数据拷贝到新空间中,这就可以给用户造成一种假象,空间是可以增长的,而内存仍然是连续的。当物理内存真的不足时,才真正意义上去触发内存不足。具体怎么实现该逻辑我们后边给出代码实现,该章节我们只是先按照开辟一定空间去分析实现。
2.2、编码实现(C语言版本)
2.2.1、工程文件构成
按照之前的约定我们在实现过程中一般是三个文件一个utili.h文件,该文件存放一些公共头文件等信息,一个声明文件、一个实现文件,一个测试文件,整体工程结构如下图2,采用Linux下的vim编辑编写,gcc编译程序。

2.2.2、头文件宏定义等声明:
C语言没有bool类型,为了方便写代码,我们声明了以下几个宏,为了代码尽可能的通用,编码过程中数据类型我们不用具体类型采用typedef关键字声明一个类型别名。
// utili.h文件该文件
#include <stdlib.h>
#include <stdio.h>
#define SEQLIST_INIT_SIZE 8 // 顺序表空间容量
#define True 1 // 表示true
#define False 0 // 表示false
typedef int Bool; // 表示bool值
typedef int ElemType; // 元素值类型 2.2.3、顺序表结构定义
按照上图1的结构,我们用C语言定义的顺序表结构如下:
typedef struct SeqList
{
ElemType *base; // 指向数据空间
int capacity; // 数据空间容量
int size; // 实际使用空间大小
}SeqList;2.2.4、顺序表的相关操作
按照顺序表的ADT类型声明,主要有如下方法:
// 初始化顺序表,成功返回True,失败返回False
Bool InitSeqList(SeqList *seq);
// 销毁顺序表,成功返回True,失败返回False
Bool DestroySeqList(SeqList *seq);
// 清空顺序表,成功返回True,失败返回False
Bool CleanSeqList(SeqList *seq);
// 判断顺序表表是否为空,空返回True,不空返回False
Bool IsEmpty(SeqList seq);
// 获取顺序表的长度
int GetSeqListLength(SeqList seq);
// 获取第i个元素
Bool GetElem(SeqList *seq, int index, ElemType *elem);
// 头插,从顺序表头部插入
Bool insert_front(SeqList *seq, ElemType val);
// 尾插
Bool insert_back(SeqList *seq, ElemType val);
// 按值插入,按照从小到大的顺序
Bool insert_value(SeqList *seq, ElemType val);
// 按照位置插入
Bool insert_pos(SeqList *seq, int pos, ElemType val);
// 头删
Bool delete_front(SeqList *seq);
// 尾删
Bool delete_back(SeqList *seq);
// 按值删除,要求不能有重复的,当有重复时,只删除第一个元素
Bool delete_value(SeqList *seq, ElemType val);
// 按值删除,删除顺序表中出现的所有元素
Bool delete_value_all(SeqList *seq, ElemType val);
// 按照位置删除、
Bool delete_value_by_pos(SeqList *seq, int pos);
// 打印整个顺序表
Bool show_seqlist(SeqList seq);
// 排序,这里先只实现冒泡排序,更多更复杂排序,专题整理
Bool sort_seqlist(SeqList *seq);
// 逆置
Bool Resver(SeqList *seq);
// 查找数据
Bool find(SeqList *seq, ElemType item);2.2.4.1、初始化顺序表:Bool InitSeqList(SeqList *seq);
该方法用于初始化顺序表,当我们声明了一个顺序表时,并未为结构中的数据成员初始化,尤其是存储数据的空间采用动态开辟空间,此时base指针根本没有实际指向的空间,size和capacity也是随机值;那么我们就需要用初始化函数为顺序表做一些初始化工作,用C++语言的话,我们就不需要专门初始化函数,该功能就放在构造函数中。具体C语言代码如下:
/*
* 函数名称:Bool InitSeqList(SeqList *seq);
* 函数作用:初始化顺序表;
* 函数参数说明:
* *seq:顺序表;
* 函数返回值说明:
* 成功:成功返回True;
* 失败:失败返回False;
* 作者:xiaok
* 时间:2019-10-11
*
* 修改内容:无;
* 时间:无;
* 修改者:无;
* */
Bool InitSeqList(SeqList *seq)
{
seq->capacity = SEQLIST_INIT_SIZE;
seq->base = (ElemType*)malloc(sizeof(ElemType) * seq->capacity);
if (NULL == seq->base)
{
return False;
}
seq->size = 0;
return True;
}2.2.4.2、销毁顺序表:Bool DestroySeqList(SeqList *seq);,成功返回True,失败返回False
有初始化就有销毁空间,当我们退出程序时,就要将我们开辟的空间释放了,该函数就是实现该功能的,对于数据空间采用静态数组的模式或许不用实现该方法,C++语言中不需要写该方法,该功能防止析构函数中。
/*
* 函数名称:Bool DestroySeqList(SeqList *seq);
* 函数作用:销毁顺序表;
* 函数参数说明:
* *seq:顺序表;
* 函数返回值说明:
* 成功:成功返回True;
* 失败:失败返回False;
* 作者:xiaok
* 时间:2019-10-11
*
* 修改内容:无;
* 时间:无;
* 修改者:无;
* */
Bool DestroySeqList(SeqList *seq)
{
if (NULL == seq)
{
return False;
}
seq->capacity = 0;
seq->size = 0;
free(seq->base);
seq->base = NULL; // 释放空间后,将指针指向NULL,防止野指针
return True;
}2.2.4.3、清空顺序表:Bool CleanSeqList(SeqList *seq);成功返回True,失败返回False
对于该方法我们要与上一个方法销毁方法区分,清空顺序表并不会释放存储空间,只是删除数据空间的元素,将size置0;对于顺序表,实际代码中我们并不会真的去擦除每个空间的数据信息,我们只要把size置为0,就达到了清空的目的;size记录着该顺序表实际存储数据个数,当我们置0时,对于使用者而言,存储空间的数据已经访问不到,已经达到了清空的目的。
清空顺序表后我们可以继续操做该顺序表,而销毁顺序表就要把空间释放掉,此次就不允许使用其他方法,空间已经不存在了,操作已经是非法。
/*
* 函数名称:Bool CleanSeqList(SeqList *seq);
* 函数作用:清空顺序表,与摧毁的区别是,不释放空间;
* 函数参数说明:
* *seq:顺序表;
* 函数返回值说明:
* 成功:成功返回True;
* 失败:失败返回False;
* 作者:xiaok
* 时间:2019-10-11
*
* 修改内容:无;
* 时间:无;
* 修改者:无;
* */
Bool CleanSeqList(SeqList *seq)
{
if (NULL == seq)
{
return False;
}
seq->size = 0;
return True;
}2.2.4.4、判断顺序表是否为空:Bool IsEmpty(SeqList seq);空返回True,不空返回False
该方法用于判断顺序表是否为空,我们在顺序表结构中维护了一个size字段,该字段表示实际存储数据的数量,那么我们判断顺序表是否为空,就很好做,只需要将size的大小和0比较就可以达到判空的目的。
/*
* 函数名称:Bool IsEmpty(SeqList seq);
* 函数作用:判断顺序表是否为空;
* 函数参数说明:
* seq:顺序表,该函数不需要修改顺序表的内容,因而以值传递;
* 函数返回值说明:
* 成功:成功返回True;
* 失败:失败返回False;
* 作者:xiaok
* 时间:2019-10-11
*
* 修改内容:无;
* 时间:无;
* 修改者:无;
* */
Bool IsEmpty(SeqList seq)
{
if (seq.size == 0)
return True;
return False;
}2.2.4.5、// 获取顺序表的长度:int GetSeqListLength(SeqList seq);
顺序表结构中size记录着顺序表的实际长度,此时获取顺序表的长度我们只需要返回size的值就可以达到目的。
/*
* 函数名称:int GetSeqListLength(SeqList seq);
* 函数作用:获取顺序表的数据长度;
* 函数参数说明:
* seq:顺序表,该函数不需要修改顺序表的内容,因而以值传递;
* 函数返回值说明:
* 返回实际大小;
* 作者:xiaok
* 时间:2019-10-11
*
* 修改内容:无;
* 时间:无;
* 修改者:无;
* */
int GetSeqListLength(SeqList seq)
{
return seq.size;
}2.2.4.6、获取第i个元素:Bool GetElem(SeqList *seq, int index, ElemType *elem);
该函数实现获取指定下标位置的元素,由于是连续空间,也就是数组,我们只需要返回指定下标的值就可以,但是需要注意,需要对下标的合法性做判断,不能访问超过实际存储大小的元素,更不能越界访问。
获取第一个空间的元素在顺序表中几乎不需要什么时间,这也就是顺序表的优点,随机读取数据是很节省时间。
/*
* 函数名称:Bool GetElem(SeqList *seq, int index, int *elem);
* 函数作用:获取顺序表指定位置元素,通过elem带回该值;
* 函数参数说明:
* *seq:顺序表;
* index:下标;
* elem:成功带回指定位置元素的值;
* 函数返回值说明:
* 成功:成功返回True;
* 失败:失败返回False;
* 作者:xiaok
* 时间:2019-10-11
*
* 修改内容:无;
* 时间:无;
* 修改者:无;
* */
Bool GetElem(SeqList *seq, int index, int *elem)
{
// 判断index 是否非法
if (index < 0 || index > seq->size )
{
return False;
}
*elem = seq->base[index];
return True;
}2.2.4.7、头插,从顺序表头部插入:Bool insert_front(SeqList *seq, ElemType val);
头插是顺序表的一个重要方法,当我们需要头插的时候,也就是我们需要将新插入的元素放到第一个位置,如图3,假设此时我们需要将7插入到顺序表中,也就是我们需要将7放到121的位置。由于数组空间一旦开辟原则是不可以改变的,那么我们头插的时候,就需要将base指向的空间的元素依次向后移动一个位置,将第一个位置空出来;注意可不敢从头往后移动,这样移动完成后整个表的空间就只存储第一个元素了,我们要从尾部开始移动直到第一个元素,然后将新插入的元素赋值到首空间;然后size++,这样就可以做到头插。头插过程需要考虑异常情况,顺序表的容量是否满足。
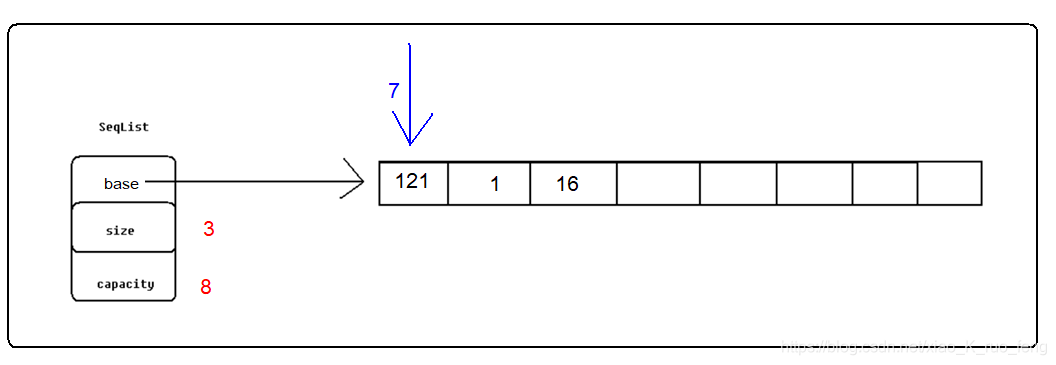
头插就会暴露出顺序表的缺点,当顺序表中本身就有很多数据时,那么此时我们进行头插,为了空出第一块空间我们不得不进行很长时间的拷贝,这样效率是很低的。
/*
* 函数名称:Bool insert_front(SeqList *seq, ElemType val);
* 函数作用:头插;
* 函数参数说明:
* *seq:顺序表;
* val:需要插入的数据;
* 函数返回值说明:
* 成功:成功返回True;
* 失败:失败返回False;
* 作者:xiaok
* 时间:2019-10-11
*
* 修改内容:无;
* 时间:无;
* 修改者:无;
* */
Bool insert_front(SeqList *seq, ElemType val)
{
int i = 0;
if (NULL == seq || NULL == seq->base)
{
return False;
}
if (seq->size == seq->capacity)
{
printf("out of memory\n");
return False;
}
for (i = seq->size; i > 0; --i)
{
seq->base[i] = seq->base[i - 1];
}
seq->base[0] = val;
seq->size++;
return True;
}2.2.4.8、尾插:Bool insert_back(SeqList *seq, ElemType val);
有头插对应的也有尾插,尾插相较于头插性能就提升了很多,size保存顺序表存储的实际元素的个数,对应的它的值刚好是最新一个可以插入的空间的下标,对于尾插只要空间不越界,就可以直接拷贝数据到size指向的内存。如图4,加入我们要尾插7,此时size的值也就是最新一个可以插入空间的下标。
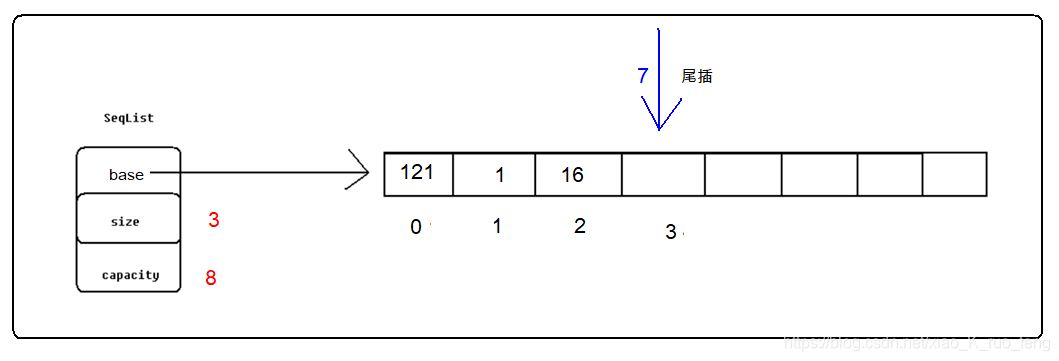
对于尾插,无论顺序表本身有多少元素,只要空间足够,插入效率都是一样的。这也就是它的优点。
/*
* 函数名称:Bool insert_back(SeqList *seq, ElemType val);
* 函数作用:尾插;
* 函数参数说明:
* *seq:顺序表;
* val:需要插入的数据;
* 函数返回值说明:
* 成功:成功返回True;
* 失败:失败返回False;
* 作者:xiaok
* 时间:2019-10-11
*
* 修改内容:无;
* 时间:无;
* 修改者:无;
* */
Bool insert_back(SeqList *seq, ElemType val)
{
if (NULL == seq || NULL == seq->base)
{
return False;
}
if (seq->size == seq->capacity)
{
printf("out of memory\n");
return False;
}
seq->base[seq->size++] = val;
return True;
}2.2.4.9、按值插入,按照从小到大的顺序:Bool insert_value(SeqList *seq, ElemType val);
按值插入要求顺序表需要有序,有序什么意思?就是说不一定连续,但是一定是按照从小到大或者从大到小的顺序依次存放。那么按值插的意思就是,如图:顺序表中本身存放着5,9,15,36,100,当我们要插入12时,依次从头到尾比较后发现12比9大比15小,那么就需要把12放到15的位置,15以及以后的元素都要依次向后移动,插入99同理。(我实现的是按照升序,也可以按照降序)
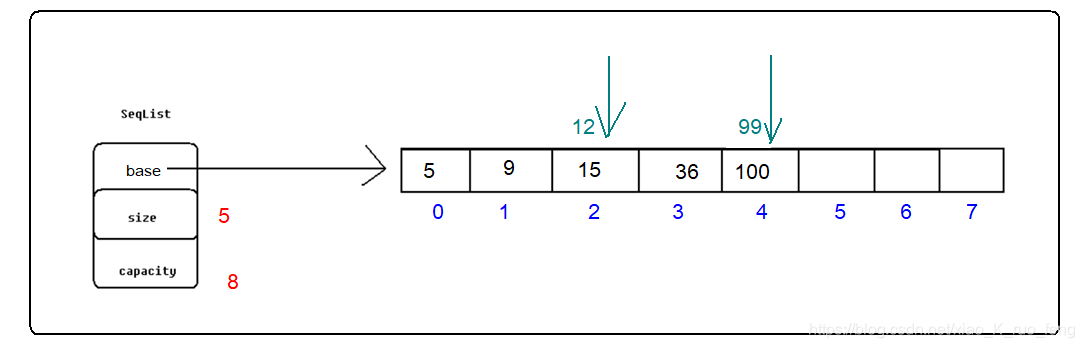
对于顺序表的按值插入效率是很不稳定,假如顺序表本身有很多数据,当我们需要插入的数据需要放到第一个位置,那么我们就需要移动整个顺序表,这和头插没有多大区别。
/*
* 函数名称:Bool insert_value(SeqList *seq, ElemType val);
* 函数作用:按值插入,采用升序,并且顺序表内元素不会重复;
* 函数参数说明:
* *seq:顺序表;
* val:需要插入的元素;
* 函数返回值说明:
* 成功:成功返回True;
* 失败:失败返回False;
* 作者:xiaok
* 时间:2019-10-11
*
* 修改内容:无;
* 时间:无;
* 修改者:无;
* */
Bool insert_value(SeqList *seq, ElemType val)
{
int i = 0;
int j = 0;
if (NULL == seq || NULL == seq->base)
{
return False;
}
if (seq->size == seq->capacity)
{
printf("out of memory\n");
return False;
}
for (i = 0; i < seq->size; ++i)
{
if (val < seq->base[i])
{
break;
}
}
j = seq->size;
for (j = seq->size; j > i; --j)
{
seq->base[j] = seq->base[j - 1];
}
seq->base[j] = val;
seq->size++;
return True;
}2.2.4.10、按照位置插入:Bool insert_pos(SeqList *seq, int pos, ElemType val);
对于顺序表的按位置插入和按值插入很类似,它省去了查找元素的过程,只要位置合法,然后将插入位置的元素以及后的边元素,依次向后移动一个位置,然后将待插入元素拷贝到插入位置。顺序表的按位置插入,也存在效率不稳定的问题,当我们插入的位置下标为0时,而此时顺序表的元素有很多,就不得不需要为腾出第一个空间付出代价。
/*
* 函数名称:Bool insert_pos(SeqList *seq, int pos, ElemType val);
* 函数作用:按照位置插入;
* 函数参数说明:
* *seq:顺序表;
* pos:即将插入的位置;
* val:需要插入的元素;
* 函数返回值说明:
* 成功:成功返回True;
* 失败:失败返回False;
* 作者:xiaok
* 时间:2019-10-11
*
* 修改内容:无;
* 时间:无;
* 修改者:无;
* */
Bool insert_pos(SeqList *seq, int pos, ElemType val)
{
int i = 0;
if (NULL == seq || NULL == seq->base)
{
return False;
}
// 空间是否已经满了
if (seq->size == seq->capacity)
{
printf("out of memory\n");
return False;
}
// 坐标是否合法
if (pos < 0 || pos > seq->size)
{
printf("out of index\n");
return False;
}
for (i = seq->size; i > pos; --i)
{
seq->base[i] = seq->base[i - 1];
}
seq->base[pos] = val;
seq->size++;
return True;
}2.2.4.11、头删:Bool delete_front(SeqList *seq);
顺序表的头删,我们直接采取覆盖策略,就是直接从头开始,将第二个元素覆盖第一个元素,依次进行最后覆盖到顺序表的有效末尾,然后size--;这也存在效率的问题,但是我也给出编码实现。
/*
* 函数名称:Bool delete_front(SeqList *seq);
* 函数作用:头删;
* 函数参数说明:
* *seq:顺序表;
* 函数返回值说明:
* 成功:成功返回True;
* 失败:失败返回False;
* 作者:xiaok
* 时间:2019-10-11
*
* 修改内容:无;
* 时间:无;
* 修改者:无;
* */
Bool delete_front(SeqList *seq)
{
int i = 0;
if (NULL == seq || NULL == seq->base)
{
return False;
}
if (IsEmpty(*seq))
{
printf("empty\n");
return False;
}
for (i = 0; i < seq->size - 1; ++i)
{
seq->base[i] = seq->base[i + 1];
}
seq->size--;
return True;
}2.2.4.12、尾删:Bool delete_back(SeqList *seq)
顺序表的尾删,就比较方便了,我们继续看图6,尾删的结果就是我们访问不到100这个元素,我们不需要专门去覆盖该空间,只需要让size--,就可以达到目的,size记录着实际存储数据的数量,size--后,不会访问到100,也就达到了删除的目的。
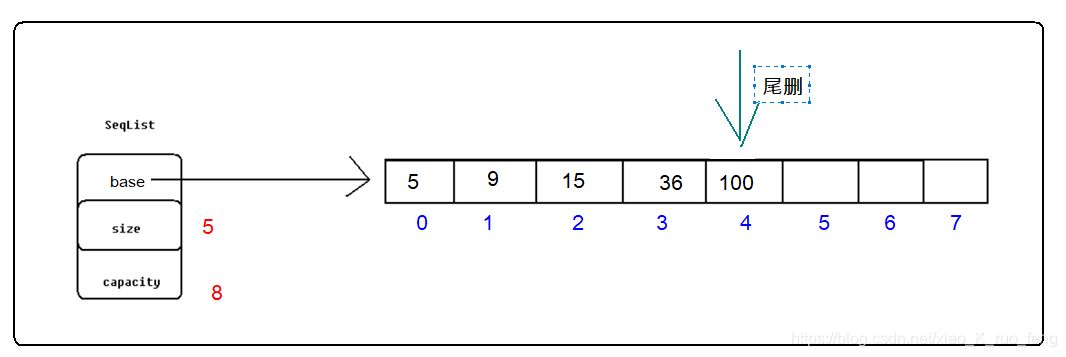
C语言代码实现:
/*
* 函数名称:Bool delete_back(SeqList *seq);
* 函数作用:尾删;
* 函数参数说明:
* *seq:顺序表;
* 函数返回值说明:
* 成功:成功返回True;
* 失败:失败返回False;
* 作者:xiaok
* 时间:2019-10-11
*
* 修改内容:无;
* 时间:无;
* 修改者:无;
* */
Bool delete_back(SeqList *seq)
{
if (NULL == seq || NULL == seq->base)
{
return False;
}
if (IsEmpty(*seq))
{
printf("empty\n");
return False;
}
seq->size--;
return False;
}2.2.4.12、按值删除:Bool delete_value(SeqList *seq, ElemType val)
按值删除,通过遍历整个顺序表,将顺序表中与需要删除的元素相同的元素删除掉,对应的size-1;这里说的删除和头删尾删等采取的策略一样,当找到相等的元素时,将后边的元素依次覆盖前一个元素。需要补充说明一下:我实现的版本是约定元素不能重复的,所有当删除完成后,就可以直接返回,如果需要删除所有元素,那么就可以继续遍历完所有的元素。
/*
* 函数名称:Bool delete_value(SeqList *seq, ElemType val);
* 函数作用:按值删除,该方法只会删除从头到尾遇到的第一个元素;
* 函数参数说明:
* *seq:顺序表;
* val:需要删除的元素值;
* 函数返回值说明:
* 成功:成功返回True;
* 失败:失败返回False;
* 作者:xiaok
* 时间:2019-10-11
*
* 修改内容:无;
* 时间:无;
* 修改者:无;
* */
Bool delete_value(SeqList *seq, ElemType val)
{
int i = 0;
int j = 0;
if (NULL == seq || NULL == seq->base)
{
return False;
}
if (IsEmpty(*seq))
{
printf("empty\n");
return False;
}
for (i = 0; i < seq->size; ++i)
{
if (seq->base[i] == val)
{
for (j = i; j < seq->size; ++j)
{
seq->base[j] = seq->base[j + 1];
}
printf("%d have delete\n", val);
seq->size--;
break;
}
}
return True;
}2.2.4.13、按位置删除:Bool delete_value_by_pos(SeqList *seq, int pos)
按位置删除,只要位置合法,我们要做的就是从需要删除的位置依次将后一个元素拷贝到前一个元素,最后size-1,就可以达到删除的目的。对于顺序表空、删除位置不合法需要判断。
/*
* 函数名称:Bool delete_value_by_pos(SeqList *seq, int pos);
* 函数作用:按照位置删除;
* 函数参数说明:
* *seq:顺序表;
* pos:下标;
* 函数返回值说明:
* 成功:成功返回True;
* 失败:失败返回False;
* 作者:xiaok
* 时间:2019-10-11
*
* 修改内容:无;
* 时间:无;
* 修改者:无;
* */
Bool delete_value_by_pos(SeqList *seq, int pos)
{
int i = 0;
if (NULL == seq || NULL == seq->base)
{
return False;
}
if (IsEmpty(*seq))
{
printf("empty\n");
return False;
}
if (pos < 0 || pos >= seq->size)
{
printf("out of range\n");
return False;
}
for (i = pos; i < seq->size; ++i)
{
seq->base[i] = seq->base[i + 1];
}
seq->size--;
return False;
}2.2.4.13、排序:Bool sort_seqlist(SeqList *seq):
排序有很多种方法,这里先给出一个最常见的排序方法,冒泡排序,更多的排序将在后续章节总结;冒泡排序思想就是让数组当中相邻的两个数据进行比较,数组当中比较小的数值向下沉,数值比较大的向上浮,通过一趟比较后最大的数据最到了正确位置,那么有n个数据,比较一趟就需要比较n-1次,则最差情况下需要比较(n-1)^n次,事实上不是,上边提到每趟比较至少有一个数据到了正确位置,那么最后一个数据是不需要比较的,所以比较到最后一趟就只比较1次,我们看图7:第一趟12先与3比较,12大则12与3交换位置,接着12继续与7比较,交换,继续比较直到最后一个数比较完成,该趟比较完成,12就到了正确的位置,接着进行第二趟比较,第二大数据就到了倒数第二个位置,通过n-1趟比较所有数据就到了正确位置,排序完成
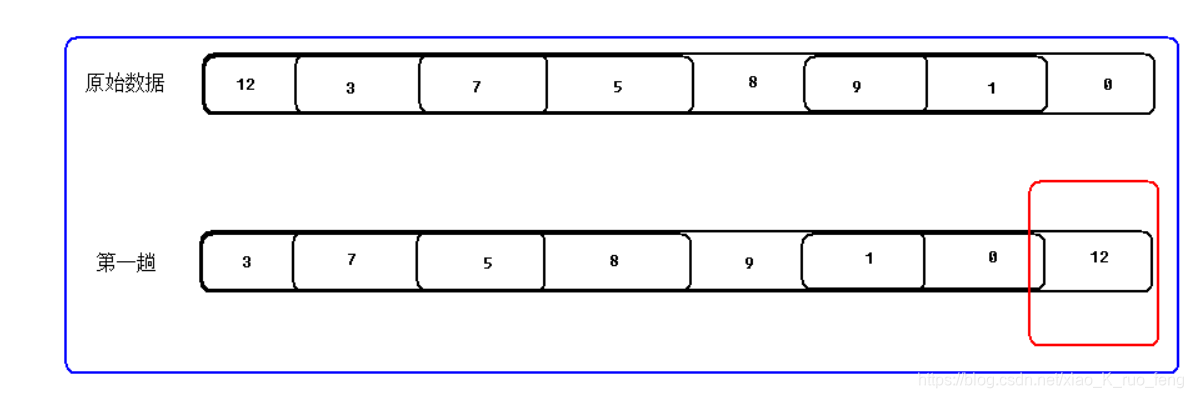
映射到代码中就是通过外层循环控制比较的趟数,通过内层循环控制比较的次数,内层循环将一个数据移动到正确位置,内层循环的条件很重要,上边提到通过一趟比较一个数据已经到了正确的位置,也就没执行一趟,内层循环就可以少执行一次比较。
/*
* 函数名称:Bool sort_seqlist(SeqList *seq);
* 函数作用:排序,采用冒泡排序;
* 函数参数说明:
* *seq:顺序表;
* 函数返回值说明:
* 成功:成功返回True;
* 失败:失败返回False;
* 作者:xiaok
* 时间:2019-10-11
*
* 修改内容:无;
* 时间:无;
* 修改者:无;
* */
Bool sort_seqlist(SeqList *seq)
{
int i = 0;
int j = 0;
if (NULL == seq || NULL == seq->base)
{
return False;
}
if (IsEmpty(*seq))
{
printf("empty\n");
return False;
}
for (i = 0; i < seq->size - 1; ++i)
{
for (j = 0; j < seq->size - i - 1; ++j)
{
if (seq->base[j] > seq->bas[j + 1])
{
ElemType tmp = seq->base[j];
seq->base[j] = seq->base[j + 1];
seq->base[j + 1] = tmp;
}
}
}
return True;
}2.2.4.14、查找方法:Bool find(SeqList *seq, ElemType item)
查找方法也有多种实现,最基本的就是通过遍历整个顺序表去一一比较查找数据,当数据很大时,显然效率是不高的,这就需要其它更高效的排序方法,这里先给出最基本的实现方式,更多查找方法后续章节总结。
/*
* 函数名称:Bool find(SeqList *seq, ElemType item);
* 函数作用:查找指定元素;顺序查找,更多查找方法,专题整理;
* 函数参数说明:
* *seq:顺序表;
* 函数返回值说明:
* 成功:成功返回True;
* 失败:失败返回False;
* 作者:xiaok
* 时间:2019-10-11
*
* 修改内容:无;
* 时间:无;
* 修改者:无;
* */
Bool find(SeqList *seq, ElemType item)
{
int i = 0;
if (NULL == seq || NULL == seq->base)
{
return False;
}
if (IsEmpty(*seq))
{
printf("not found\n");
return False;
}
for (i = 0; i < seq->size; ++i)
{
// 说明一下:这里我们用整形去测试,所以比较是否相等用简单的==比较,这里只是学习数据结构的思路
if (seq->base[i] == item)
{
return True;
}
}
printf("not found\n");
return False;
}2.2.4.15逆置方法:Bool Resver(SeqList *seq)
逆置方法就是将已排序后的顺序表由原来的升序换成降序或者降序编程升序。所有逆置方法有个前提就是顺序表有序,事实上,顺序表可以无序,但是无序的顺序表逆置没有意义。
实现逆置方式,我们可以申请一块和原始顺序表一样大的空间,将原先的顺序表逆序拷贝到新空间中,最后将base指针指向新空间,释放原有空间,就达到了逆置的效果;不过这样做显然是不可取的,数据量很大时,这样做显然会造成内存不足,一种更友好的方法是如图8:我们的目的是达到逆置,也就是首尾交换,那么我们就借助一个临时空间s,让1和8交换,这样做是很容易实现的,紧接着我们继续交换2和7,依次交换;需要注意,假设一共由n个数据,这样我们只需要交换n/2次,不可以交换n次,若交换n次,就会把刚才交换好的数据重新交换回去。我们便采用这种方法实现逆置顺序表。
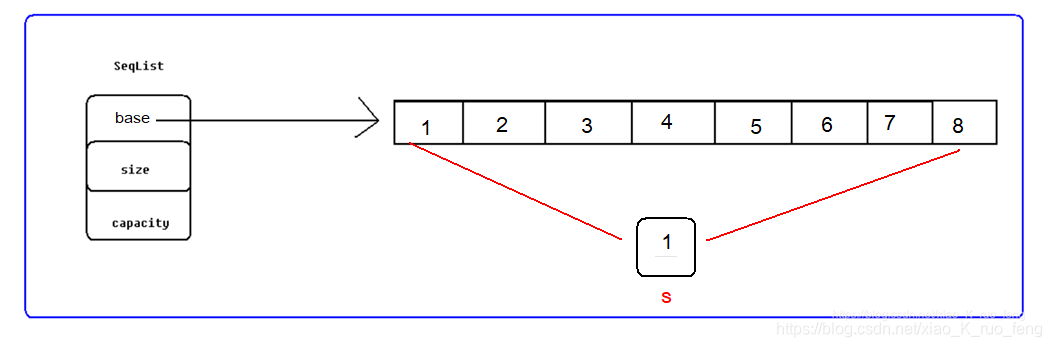
编码实现:
/*
* 函数名称:Bool Resver(SeqList *seq);
* 函数作用:逆置顺序表
* 函数参数说明:
* *seq:顺序表;
* 函数返回值说明:
* 成功:成功返回True;
* 失败:失败返回False;
* 作者:xiaok
* 时间:2019-10-11
*
* 修改内容:无;
* 时间:无;
* 修改者:无;
* */
Bool Resver(SeqList *seq)
{
int low = 0;
int high = 0;
if (NULL == seq || NULL == seq->base)
{
return False;
}
if (0 == seq->size)
{
return True;
}
ElemType tmp;
high = seq->size - 1;
while (low < high)
{
tmp = seq->base[low];
seq->base[low++] = seq->base[high];
seq->base[high--] = tmp;
}
return True;
}2.2.4.16、打印输出:Bool show_seqlist(SeqList seq)
打印输出就是要遍历整个顺序表,size记录了顺序表的实际存储数据的数量,那么我们只需要循环size次,打印输出整个顺序表就可以。
/*
* 函数名称:Bool show_seqlist(SeqList seq);
* 函数作用:打印顺序表;
* 函数参数说明:
* seq:顺序表,不需要修改,以值传递;
* 函数返回值说明:
* 成功:成功返回True;
* 失败:失败返回False;
* 作者:xiaok
* 时间:2019-10-11
*
* 修改内容:无;
* 时间:无;
* 修改者:无;
* */
Bool show_seqlist(SeqList seq)
{
int i = 0;
if (NULL == seq.base)
{
return False;
}
for (i = 0; i < seq.size; ++i)
{
printf("%d ",seq.base[i]);
}
printf("nal\n");
return True;
}3、顺序表优缺点
上边我们就顺序表的基本方法,给出了我自己的理解,每个方法就我认为需要注意的地方,也给出了相应的提示,实现过程中就该方法的优缺点做了简单陈述,这里我们总结归纳一下。
优点:
可以快速获取到表中任意数据元素
缺点:
插入和删除操作需要移动大量元素,当线性表的长度变化较大时,很难确定存储空间的大小,造成存储空间“碎片”当顺序表比较长时,插入、删除时比较浪费时间。
以上就是关于顺序表方法的总结,完整C语言实现版本代码见Github,同时我也给出了C++语言实现版本;下一篇就开篇提到的能否让顺序表的空间自增起来给出自己的理解,其间可能存在差错,若读者发现问题,请联系作者,谢谢。














 9002
9002











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









