







Catalina有2个主要的模块,连接器和容器。 一个符合servlet2.3和2.4规范必须HttpServletRequest和HttpServletResponse并传递给servlet的service方法。在第二章中,servlet容器只可以运行实现了Servlet` 的servlet,并传递ServletRequest 和ServletResponse实例给 service 方法。因为连接器并不知道servlet的类型(例如它是否实现了 Servlet,继承了GenericServlet,或者继承了 HttpServlet)。所以连接器必须始终提供 HttpServletRequest 和 HttpServletResponse 的实例。在本节的应用程序中,连接器解析HTTP请求头部并让servlet可以获取头部、cookies、参数名/值
StringManager 类
在看是应用程序之前,我们先讨论一下org.apache.catalina.util 包中的StringManager 类。
一个Tomcat这样的大型的应用,需要仔细的处理错误信息,在Tomcat中,错误信息对于系统管理员和servlet程序员都是有用的。Tomcat所采用的方法是在一个属性文件中存储错误信息。它为每个包分配了一个属性文件LocalStrings.properties。当包里面的一个类需要查找放在包属性文件夹中的错误信息时,他会首先获得StringManager的实例,不过相同包中许多其他的类也可能要获取错误信息。而为每一个类创建一个StringManager显然是一种浪费。所以StringManager被设计成单例模式。你通过传递一个包名来调用它的公共静态方法 getManager 来获得一个实例。每个实例存储在一个以包名为键(key)的 Hashtable 中。
private static Hashtable managers = new Hashtable();
public synchronized static StringManager
getManager(String packageName) {
StringManager mgr = (StringManager)managers.get(packageName);
if (mgr == null) {
mgr = new StringManager(packageName);
managers.put(packageName, mgr);
}
return mgr;
}获取包对象后,可以通过public String getString(String key)方法获取属性文件中key对应的值。
应用程序
本次程序分为三个模块:connector、startup、core
- startup模块只有一个类,BootStrap,用来启动应用的。
- connector 模块的类可以分为五组:
- 连接器和他的支撑类(HttpConnector和HttpProcessor)
- 指代Http请求的类(HttpRequest)和他的辅助类
- 指代Http响应的类(HttpRequest)和他的辅助类
- Facade 类(HttpRequestFacade 和 HttpResponseFacade)。
- Constant 类
- core模块由两个类组成:ServletProcessor和StaticResourceProcessor
类结构图如下:
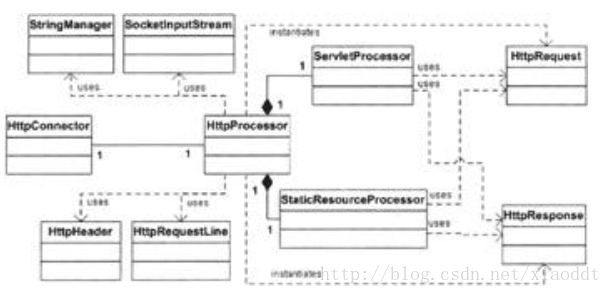
- HttpServer被分离成了两个类: HttpConnector和 HttpProcessor。Request 被 HttpRequest 所取代,而 Response 被 HttpResponse 所取代
- HttpConnector负责等待HTTP请求,HttpProcessor负责创建请求和响应对象
- HTTP 请求对象由实现了 javax.servlet.http.HttpServletRequest 的 HttpRequest类来代表。由于HttpRequest对象将会被转换为HttpServletRequest对象并传递给Servlet的service方法,因此每个HttpRequest需要增加某些字段,如:URI,查询字符串,cookie,参数和其他的一些头部信息等等。
- 因为连接器并不知道被调用的 servlet 需要哪个值,所以连接器必须从 HTTP 请求中解析所有可获得的值。不过,解析一个HTTP请求牵涉到安贵的字符串和其他操作,假如只是需要解析servlet需要的值的话,连接器就能节省许多CPU周期。
- Tomcat的默认连接器和我们的连接器使用 SocketInputStream 类来从套接字的 InputStream中读取字节流。一个 SocketInputStream 实例对从套接字的 getInputStream 方法中返回的java.io.InputStream 实 例 进行 包 装。SocketInputStream 类 提 供 了两 个 重要 的 方法 :readRequestLine 和 readHeader。
- readRequestLine 返回HTTP请求的第一行(方法-URI-协议/版本)
- 因为从套接字的输入流中处理字节流意味着只读取一次,从第一个字节到最后一个字节(并且不回退),因此 readHeader 被调用之前,readRequestLine 必须只被调用一次。
- readHeader 每次被调用来获得一个头部的名/值对,并且应该被重复的调用直到所有的头部被读取到。
- readRequestLine 的返回值是一个 HttpRequestLine 的实例,而readHeader 的返回值是一个 HttpHeader 对象
启动类:
public final class Bootstrap {
public static void main(String[] args) {
HttpConnector connector = new HttpConnector();
connector.start();
}
}此类中主要是实例化了一个连接器。调用它的start()方法。
连接器类:
public class HttpConnector implements Runnable{
boolean stoped;
private String name="http";
public String getName() {
return name;
}
@Override
public void run() {
ServerSocket serverSocket = null;
int port = 8080;
try {
serverSocket = new ServerSocket(port,1,InetAddress.getByName("127.0,0.1"));
} catch (UnknownHostException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
while(!stoped){
Socket socket = null;
try {
socket = serverSocket.accept();
} catch (IOException e) {
// TODO Auto-generated catch block
continue;
}
}
}
}此连接器的任务是创建ServerSocket对象等待HTTP请求。可以看出,此连接器和上一章HttpServer类是非常相似的。除了在通过获得socket对象以后,实例化HttpProcessor对象。
而对HttpProcessor而言,对每一个来到的HTTP请求,他做了以下处理:
- 创建了一个HttpRequest对象
- 创建了一个HttpResponse对象
- 解析 HTTP 请求的第一行和头部,并放到 HttpRequest 对象中
- 解 析 HttpRequest 和 HttpResponse 对象到ServletProcessor 或 者
StaticResourceProcessor。像第 2 章里边说的, ServletProcessor 调用被请求的 servlet 的service 方 法,而 StaticResourceProcessor 发送一个静态资源的内容。
HttpProcessor 类 process 方法:
public void process(Socket socket) {
SocketInputStream input = null;
OutputStream output = null;
try {
// 获得套接字的输入流和输出流
input = new SocketInputStream(socket.getInputStream(), 2048);
output = socket.getOutputStream();
// create HttpRequest object and parse
request = new HttpRequest(input);
// create HttpResponse object
response = new HttpResponse(output);
response.setRequest(request);
response.setHeader("Server", "Pyrmont Servlet Container");
parseRequest(input, output);
parseHeaders(input);
//check if this is a request for a servlet or a static resource
//a request for a servlet begins with "/servlet/"
if (request.getRequestURI().startsWith("/servlet/")) {
ServletProcessor processor = new ServletProcessor();
processor.process(request, response);
}
else {
StaticResourceProcessor processor = new StaticResourceProcessor();
processor.process(request, response);
}
// Close the socket
socket.close();
// no shutdown for this application
}
catch (Exception e) {
e.printStackTrace();
}
}创建HttpRequest对象
HttpRequest实现了HttpServletRequest,同时创建了一个HttpRequestFacade类
许多HttpRequest的方法使用的是空实现,但是现在可以从 HTTP 请求中获得头部, cookies 和参数了,这三种类型的值被存储在下面几个引用变量中:
protected HashMap headers = new HashMap();
protected ArrayList cookies = new ArrayList();
protected ParameterMap parameters = null;程序员可以从下列方法中获取他们的值,getCookies,getDateHeader,getHeader, getHeaderNames, getHeaders,
getParameter, getPrameterMap,getParameterNames 和 getParameterValues 。本节重点是解析HTTP请求和填充HttpRequest类,因为 HTTP 请求的解析是一项相当复杂的任务,所以本节会分为几个小节。
读取套接字的输入流
在前两章其实对HTTP做了一些简单的解析
byte[] buffer = new byte [2048];
try {
// input is the InputStream from the socket.
i = input.read(buffer);
}但是并没有进一步的解析请求。本节使用的SocketInputStream来自org.apache.catalina.connector.http.SocketInputStream这个类提供了方法不仅用来获取请求行,还有请求头部。
SocketInputStream input = null;
OutputStream output = null;
try {
input = new SocketInputStream(socket.getInputStream(), 2048);
...前面提到过,拥有一个 SocketInputStream 是为了两个重要方法: readRequestLine和 readHeader。
解析请求行
HttpProcessor 的 process 方法调用私有方法 parseRequest 用来解析请求行,例如一个 HTTP请求的第一行
GET /myApp/ModernServlet?userName=tarzan&password=pwd HTTP/1.1
其中的URI:/myApp/ModernServlet
参数:userName=tarzan&password=pwd
当 parseRequest 方法被 HttpProcessor 类的 process 方法调用的时候, request 变量指向一个 HttpRequest 实例。 parseRequest 方法解析请求行用来获得几个值并把这些值赋给HttpRequest 对象。
查询字符串也可以包含一个会话标识符,用 jsessionid 参数名来指代。因此,parseRequest 方法也检查一个会话标识符。假如在查询字符串里边找到 jessionid,方法就取得会话标识符,并通过调用setRequestedSessionId 方法把值交给 HttpRequest 实例。
解析头部
一个 HTTP 头部是用类 HttpHeader 来代表的,你可以通过使用类的无参数构造方法构造一个 HttpHeader 实例。一旦你拥有一个 HttpHeader 实例,你可以把它传递给 SocketInputStream 的 readHeader
方法。假如这里有头部需要读取, readHeader 方法将会相应的填充 HttpHeader 对象。假如再也没有头部需要读取了,HttpHeader 实例的 nameEnd 和 valueEnd 字段将会置零。为了获取头部的名称和值,使用下面的方法:
String name = new String(header.name, 0, header.nameEnd);
String value = new String(header.value, 0, header.valueEnd);
parseHeaders 方法包括一个 while 循环用于持续的从 SocketInputStream 中读取头部,直到 再 也 没 有头 部 出 现为 止 。 循环 从 构 建一 个 HttpHeader 对象 开 始 ,并 把 它 传递 给 类SocketInputStream 的 readHeader 方法:
解析 Cookies
Cookies 是作为一个 Http 请求头部通过浏览器来发送的。这样一个头部名为”cookie”并且它的值是一些 cookie 名/值对
获取参数
不 需要马上 解析查询 字符串 或 者 HTTP 请求内 容,直 到 servlet 需要通过 调用
javax.servlet.http.HttpServletRequest 的 getParameter,
getParameterMap, getParameterNames 或者 getParameterValues 方法来读取参数。因此,HttpRequest 的这四个方法开头调用了 parseParameter 方法。
创建一个 HttpResponse 对象
HttpResponse 实现了HttpServletResponse接口,同时创建的还有HttpResponseFacade。
在第二章中,HttpResponse只是实现了部分功能,例如,通过getWriter()返回的PrintWriter对象在调用print方法时并不会自动刷新。本章解决了这个问题。
第二章getWriter()的实现:
public PrintWriter getWriter() {
// if autoflush is true, println() will flush,
// but print() will not.
// the output argument is an OutputStream
//the content will show in browser after flush
writer = new PrintWriter(output, true);
return writer;
}我们通过传递OutputStream对象构造PrintWriter,通过print或者println输出的任何内容都会被转换 为OutputStream,本章使用的ResponseStream代替OutputStream作为传入的参数,注意ResponseStream也是由OutputStream的间接的衍生而来。
ResponseWriter 继承自PrintWriter类,他复写了所有的print和pringln方法。不论是print或者println都会使得其刷新。
我们可以使用ResponseStream的对象来初始化ResponseWriter,但是在此我们使用了OutputStreamWriter作为一个桥梁。通过OutputStreamWriter,写进去的字符通过一种特定的字符集被编码成字节。这种字符集可以使用名字来设定,或者明确给出,或者使用平台可接受的默认字符集 。write 方法的每次调用都会导致在给定的字符上编码转换器的调用。在写入底层的输出流之前,生成的字节都会累积到一个缓冲区中。缓冲区的大小可以自己设定,但是对大多数场景来说,默认的就足够大了。
注意的是,传递给 write 方法的字符是没有被缓冲的
public PrintWriter getWriter() throws IOException {
ResponseStream newStream = new ResponseStream(this);
newStream.setCommit(false);
OutputStreamWriter osr =
new OutputStreamWriter(newStream, getCharacterEncoding());
writer = new ResponseWriter(osr);
return writer;
}静态资源处理器和 Servlet 处理器
ServletProcessor与上一章的类似,他们都只有一个方法,只是传递的参数由Request、Response变成了HttpRequest和HttpResponse。
总结:
在本章中,你已经知道了连接器是如何工作的。建立起来的连接器是 Tomcat4 的默认连接器的简化版本。因为默认连接器并不高效,所以已经被弃用了。例如,所有的HTTP 请求头部都被解析了,即使它们没有在 servlet 中使用过。因此,默认连接器很慢,并且已经被 Coyote 所代替了。 Coyote 是一个更快的连接器,它的源代码可以在 Apache 软件基金会的网站中下载。不管怎样,默认连接器作为一个优秀的学习工具,将会在第 4 章中详细讨论。














 4942
4942











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









