









转载: http://blog.csdn.net/a417930422/article/details/52585862
为何要懂零拷贝原理?因为rocketmq存储核心使用的就是零拷贝原理。
- io读写的方式
- 中断
- DMA
- 中断方式
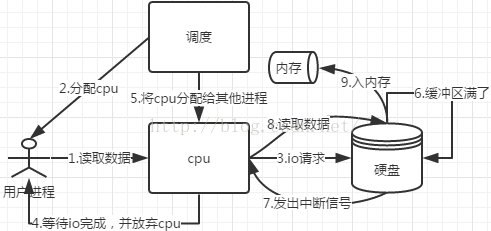
- 中断方式的流程图如下:
- 用户进程发起数据读取请求
- 系统调度为该进程分配cpu
- cpu向io控制器(ide,scsi)发送io请求
- 用户进程等待io完成,让出cpu
- 系统调度cpu执行其他任务
- 数据写入至io控制器的缓冲寄存器
- 缓冲寄存器满了向cpu发出中断信号
- cpu读取数据至内存
- 缺点:中断次数取决于缓冲寄存器的大小
- 中断方式的流程图如下:
- DMA : 直接内存存取
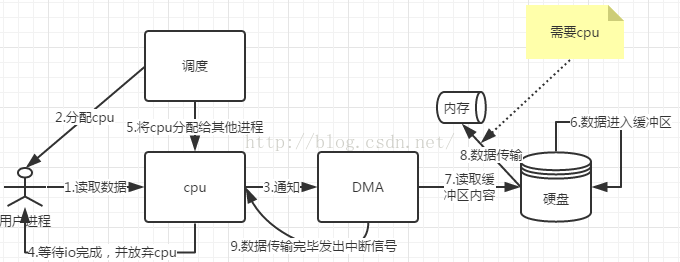
- DMA方式的流程图如下:
- 用户进程发起数据读取请求
- 系统调度为该进程分配cpu
- cpu向DMA发送io请求
- 用户进程等待io完成,让出cpu
- 系统调度cpu执行其他任务
- 数据写入至io控制器的缓冲寄存器
- DMA不断获取缓冲寄存器中的数据(需要cpu时钟)
- 传输至内存(需要cpu时钟)
- 所需的全部数据获取完毕后向cpu发出中断信号
- 优点:减少cpu中断次数,不用cpu拷贝数据
- DMA方式的流程图如下:
- 数据拷贝
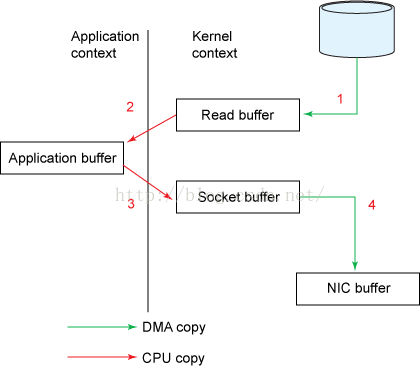
- 下面展示了 传统方式读取数据后并通过网络发送 所发生的数据拷贝:
- 一个read系统调用后,DMA执行了一次数据拷贝,从磁盘到内核空间
- read结束后,发生第二次数据拷贝,由cpu将数据从内核空间拷贝至用户空间
- send系统调用,cpu发生第三次数据拷贝,由cpu将数据从用户空间拷贝至内核空间(socket缓冲区)
- send系统调用结束后,DMA执行第四次数据拷贝,将数据从内核拷贝至协议引擎
- 另外,这四个过程中,每个过程都发生一次上下文切换
- 内存缓冲数据,主要是为了提高性能,内核可以预读部分数据,当所需数据小于内存缓冲区大小时,将极大的提高性能。
- 零拷贝是为了消除这个过程中冗余的拷贝
- 下面展示了 传统方式读取数据后并通过网络发送 所发生的数据拷贝:
- 零拷贝-sendfile 对应到java中
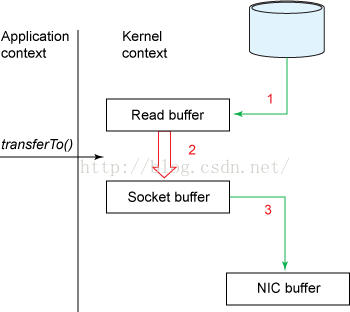
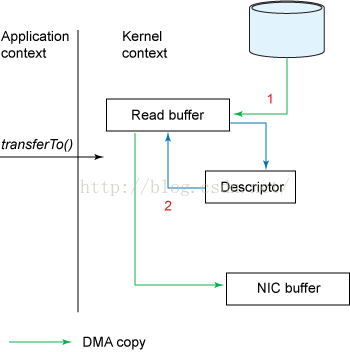
为FileChannel.transferTo(long position, long count, WritableByteChannel target)//将数据从文件通道传输到了给定的可写字节通道- 避免了第2,3步的数据拷贝,参考下图:
- DMA从拷贝至内核缓冲区
- cpu将数据从内核缓冲区拷贝至内核空间(socket缓冲区)
- DMA将数据从内核拷贝至协议引擎
- 这三个过程中共发生2次上下文切换,分别为发起读取文件和发送数据
- 以上过程发生了三次数据拷贝,其中有一次为cpu完成
- linux内核2.4以后,socket缓冲区做了调整,DMA带收集功能,如下图:
- DMA从拷贝至内核缓冲区
- 将数据的位置和长度的信息的描述符增加至内核空间(socket缓冲区)
- DMA将数据从内核拷贝至协议引擎
- 避免了第2,3步的数据拷贝,参考下图:
- 零拷贝-mmap 对应到java中
为MappedByteBuffer//文件内存映射- 数据不会复制到用户空间,只在内核空间,与sendfile类似,但是应用程序可以直接操作该内存。
-
关于I/O内存映射:
设备通过控制总线,数据总线,状态总线与CPU相连。控制总数传送控制信号,例如,网卡的启用。数据总线控制数据传输,例如,网卡发送数据,状态总数一般都是读取设备的当前状态,例如读取网卡的MAC地址。
在传统的操作中,都是通过读写设备寄存器的值来实现。但是这样耗费了CPU时钟。而且每取一次值都要读取设备寄存器,造成了效率的低下。在现代操作系统中。引用了I/O内存映射。即把寄存器的值映身到主存。对设备寄存器的操作,转换为对主存的操作,这样极大的提高了效率。
-
关于DMA:
这是关于设备数据处理的一种方式。传统的处理方法为:当设备接收到数据,向CPU报告中断。CPU处理中断,把数据放到内存。在现代操作系统中引入的DMA是指,设备接收到数据时,把数据放至DMA内存,再向CPU产生中断。这样节省了大量的CPU时间。
-
DMA技术的出现,使得外围设备可以通过DMA控制器直接访问内存,与此同时,CPU可以继续执行程序.那么DMA控制器与CPU怎样分时使用内存呢?
通常采用以下三种方法:(1)停止CPU访内;(2)周期挪用;(3)DMA与CPU交替访内存.
1.停止CPU访问内存当外围设备要求传送一批数据时,由DMA控制器发一个停止信号给CPU,要求CPU放弃对地址总线、数据总线和有关控制总线的使用权.DMA控制器获得总线控制权以后,开始进行数据传送.在一批数据传送完毕后,DMA控制器通知CPU可以使用内存,并把总线控制权交还给CPU是这种传送方式的时间图.很显然,在这种DMA传送过程中CPU基本处于不工作状态或者说保持状态.
优点: 控制简单,它适用于数据传输率很高的设备进行成组传送.
缺点: 在DMA控制器访内阶段,内存的效能没有充分发挥,相当一部分内存工作周期是空闲的。这是因为,外围设备传送两个数据之间的间隔一般总是大于内存存储周期,即使高速I/O设备也是如此。例如,软盘读出一个8位二进制数大约需要32us,而半导体内存的存储周期小于0.5us,因此许多空闲的存储周期不能被CPU利用.
2.周期挪用:当I/O设备没有DMA请求时,CPU按程序要求访问内存;一旦I/O设备有DMA请求,则由I/O设备挪用一个或几个内存周期。I/O设备要求DMA传送时可能遇到两种情况:
(1)此时CPU不需要访内,如CPU正在执行乘法指令。由于乘法指令执行时间较长,此时I/O访内与CPU访内没有冲突,即I/O设备挪用一二个内存周期对CPU执行程序没有任何影响。
(2)I/O设备要求访内时CPU也要求访内,这就产生了访内冲突,在这种情况下I/O设备访内优先,因为I/O访内有时间要求,前一个I/O数据必须在下一个访内请求到来之前存取完毕。显然,在这种情况下I/O 设备挪用一二个内存周期,意味着CPU延缓了对指令的执行,或者更明确地说,在CPU执行访内指令的过程中插入DMA请求,挪用了一二个内存周期。与停止CPU访内的DMA方法比较,周期挪用的方法既实现了I/O传送,又较好地发挥了内存和CPU的效率,是一种广泛采用的方法。但是I/O设备每一次周期挪用都有申请总线控制权、建立线控制权和归还总线控制权的过程,所以传送一个字对内存来说要占用一个周期,但对DMA控制器来说一般要2—5个内存周期(视逻辑线路的延迟而定)。因此,周期挪用的方法适用于I/O设备读写周期大于内存存储周期的情况。
3.DMA与CPU交替访内如果CPU的工作周期比内存存取周期长很多,此时采用交替访内的方法可以使DMA传送和CPU同时发挥最高.
- 参考资料














 1129
1129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









