







转载请注明出处:http://blog.csdn.net/xiaojimanman/article/details/44851419
http://www.llwjy.com/blogdetail/1b5ae17c513d127838c2e02102b5bb87.html
个人博客站已经上线了,网址 www.llwjy.com ~欢迎各位吐槽~
-------------------------------------------------------------------------------------------------
在上一篇博客中,我们已经对纵横中文小说的更新列表页做了简单的采集,获得了小说简介页的URL,因此这篇博客我们就介绍纵横中文小说简介页信息的采集,事例地址:http://book.zongheng.com/book/362857.html
页面分析
在开始之前,建议个人先看一下简介页的样子,下图只是我们要采集的信息所在的区域。
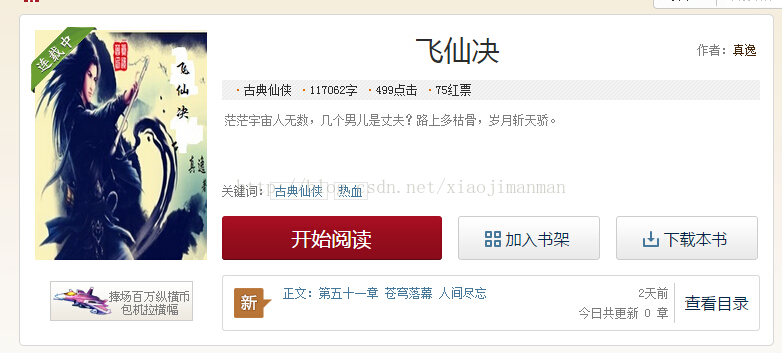
在这一部分,我们需要获取书名、作者名、分类、字数、简介、最新章节名、章节页URL和标签等信息。在页面上,我们通过鼠标右键--查看网页源代码 发现下面一个现象

纵横小说为了做360的seo,把小说的一些关键信息放到head中,这样就大大减少我们下正则的复杂度,由于这几个正则大同小异,所以就只用书名做简单的介绍,其余的正则可以参照后面的源代码。 这里的书名在上述截图中的33行,我们需要提取中间的 飞仙诀 信息,因此我们提取该信息的正则表达式为” <meta name="og:novel:book_name" content="(.*?)"/> “ ,其他信息和此正则类似。通过上图这部分源代码我们可以轻易的获取书
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 436
436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









