




 HDFS(Hadoop Distributed File System)是Hadoop的核心组件,提供高容错、高可靠性的大数据存储。本文详细介绍了HDFS的优点,如高容错性、适合批处理和大数据处理,以及缺点,如低延迟访问和小文件存储效率低。文章探讨了HDFS的基本架构,包括NameNode、Secondary NameNode和DataNode的角色,以及数据块、副本策略和可靠性机制。此外,还详细阐述了HDFS的读写流程、Shell命令的使用以及HDFS API的应用。
HDFS(Hadoop Distributed File System)是Hadoop的核心组件,提供高容错、高可靠性的大数据存储。本文详细介绍了HDFS的优点,如高容错性、适合批处理和大数据处理,以及缺点,如低延迟访问和小文件存储效率低。文章探讨了HDFS的基本架构,包括NameNode、Secondary NameNode和DataNode的角色,以及数据块、副本策略和可靠性机制。此外,还详细阐述了HDFS的读写流程、Shell命令的使用以及HDFS API的应用。
一、概要
作为Hadoop的核心技术之一,HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)是分布式计算中数据存储管理的基础。它所具有的高容错、高可靠、高可扩展性、高吞吐率等特性为海量数据提供了不怕故障的存储,也为超大规模数据集(Large Data Set)的应用处理带来了很多便利。
1、HDFS优点
- 高容错性
1、数据自动保存多个副本
2、副本丢失后,自动恢复 - 适合批处理
1、移动计算而非数据
2、数据位置暴露给计算框架 - 适合大数据处理
1、GB、TB、甚至PB级数据
2、百万规模以上的文件数量
3、10K+节点规模 - 流式文件访问
1、一次性写入,多次读取
2、保证数据一致性 - 可构建在廉价机器上
1、通过多副本提高可靠性
2、提供了容错和恢复机制
2、HDFS缺点
- 低延迟数据访问
1、比如毫秒级
2、低延迟与高吞吐率 - 不利于大量小文件存取
1、占用NameNode大量内存
2、寻道时间超过读取时间 - 不支持并发写入和文件随机修改
1、一个文件只能有一个写者
2、仅支持append(追加模式)
二、HDFS基本架构和原理
HDFS设计思想可以用下图展示:
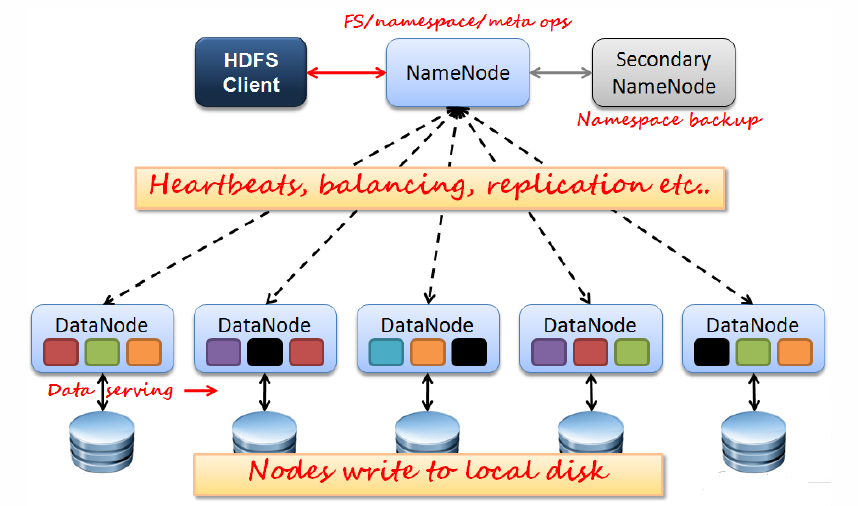
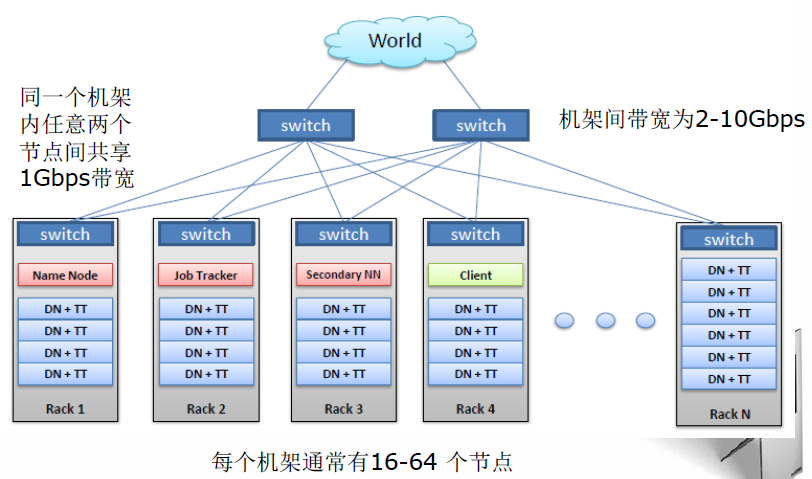
HDFS拥有一个NameNode和若干DataNodes。NameNode管理文件系统的元数据,DataNode存储实际的数据。客户端通过同NameNode和DataNode的交互访问文件系统→客户端联系NameNode以获取文件的元数据,而真正的I/O操作是直接和DataNode进行交互的。其典型物理拓扑如下图:
1、HDFS Client
是HDFS的访问客户端,主要职责有:
- 文件切分
- 与NameNode交互,获取文件位置信息;
- 与DataNode交互,读取或者写入数据;
- 管理HDFS;
- 访问HDFS
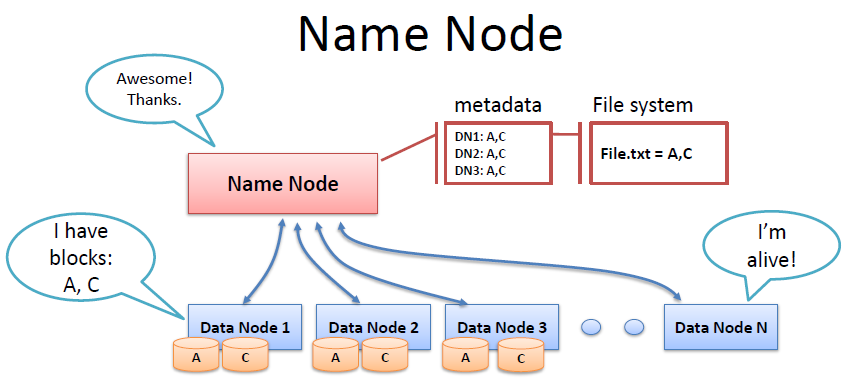
2、Namenode
Namenode使整个HDFS系统的主Master,一般情况在整个集群中只有一个。主要职责有:
- 管理HDFS中文件目录与数据块之间的关系,是静态的,是存放在磁盘上的,通过fsimage和edits文件来维护。
- 管理HDFS中数据块与节点间的关系,是动态的,不持久化到磁盘,每当集群启动的时候,会自动建立这些信息。
- 配置副本策略
- 处理客户端读写请求
3、 Secondary NameNode
从它的名字上看,它给人的感觉就像是NameNode的备份。但它实际上却不是。它的职责是合并NameNode的edit logs到fsimage文件中。
SecondaryNameNode有两个作用,一是镜像备份,二是日志与镜像的定期合并。两个过程同时进行,称为checkpoint。
- 镜像备份的作用
备份fsimage(fsimage是元数据发送检查点时写入文件); - 日志与镜像的定期合并的作用
将Namenode中edits日志和fsimage合并,减小重恢复的代价。因为如果Namenode节点故障,namenode下次启动的时候,会把fsimage加载到内存中,应用edit log,而edit log往往很大,导致操作往往很耗时。
4、Datanode
DataNode是HDFS中真正存储数据的,需要注意的是DataNode存储的是Block(数据块)。假设原文件大小是100GB,那么从字节位置0开始,每64MB字节划分为一个Block,以此类推,可以划分出很多的Block。然后把这些Block存储到HDFS集群上。
5、HDFS数据块(block)
HDFS存储时把文件切分成固定大小的数据块,默认数据块大小为64MB,可自行配置。若文件大小不到64MB,则单独存成一个block。之所以设计数据块为64MB或者更大的原因是为了减少寻道时间,从而保证高吞吐率。文件按大小被切分成若干个block后,会存储到不同节点上,默认情况下每个block有三个副本。
6、HDFS可靠性策略
HDFS具备了较为完善的冗余备份和故障恢复机制,可以实现在集群中可靠地存储海量文件。
冗余备份
HDFS将每个文件存储成一系列的数据块(Block),默认块大小为64MB(可以自定义配置)。为了容错,文件的所有数据块都可以有副本(默认为3个,可以自定义配置)。当DataNode启动的时候,它会遍历本地文件系统,产生一份HDFS数据块和本地文件对应关系的列表,并把这个报告发送给NameNode,这就是报告块(BlockReport),报告块上包含了DataNode上所有块的列表。HDFS副本放置策略
一个文件划分成多个block,每个block存多份,如何为每个block选择节点存储这几份数据?
Block副本放置策略:HDFS采用一种称为机架感知(Rack-aware)的策略来改进数据的可靠性、可用性和网络带宽的利用率。
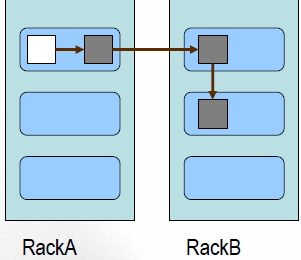
副本1: 同Client的节点上,也就是当前节点
副本2: 不同机架中的任意一个节点上
副本3: 与第二个副本在同一机架的另一个节点上
其他副本:随机挑选(假如副本配置大于3)- 心跳检测
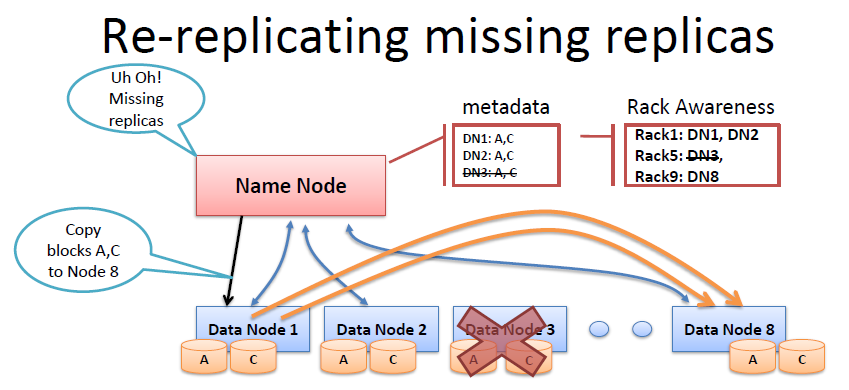
NameNode周期性地从集群中的每个DataNode接受心跳包和块报告,NameNode可以根据这个报告验证映射和其他文件系统元数据。收到心跳包,说明该DataNode工作正常。如果DataNode不能发送心跳信息,NameNode会标记最近没有心跳的DataNode为宕机,并且不会给他们发送任何I/O请求。
如果NameNode检测到一个DataNode不再发出检测信号,则假定它已经死亡,存储在该节点上的数据也消失了。基于从死亡节点接受到的报告,NameNode知道哪个副本连同节点块死亡,并可决定重新复制这些块到其他DataNode。这个过程还将参考机架感知数据,以保持在一个机架内的两个副本。 - 安全模式
处于safemode的集群是无法接收任何写操作的,包括创建目录、删除文件、修改文件、上传文件等等。hdfs集群在启动和关闭的时候一般会有一段时间处于safemode,如果集群中出现了大量的block副本数量低于配置的副本数据量(这个副本数量的配置并不一定是在hdfs的配置文件中配的,配置文件中的只是默认值,在创建文件的时候,客户端可以给文件指定一个副本数量),或者有大量的节点出现故障时,集群可能会长时间处于safemode。出现以上情况就需要去检查集群或者文件是否除了故障。有时候管理员也会强制集群退出safemode,通过hdfs dfsadmin -safemode leave退出
7、HDFS不适合存储小文件
- 在HDFS系统中,元信息存储在NameNode内存中的,而一个节点的内存是有限的,大量的小文件的元信息会消耗很多的内存资源。
- 存取大量小文件消耗大量的寻道时间,其原理类比拷贝大量小文件与拷贝同等大小的一个大文件。
- NameNode存储block数目是有限的,一个block元信息消耗大约150 byte内存。那么存储1亿个block,大约需要20GB内存。如果一个文件大小为10K,则1亿个这样的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









