




 本文详细介绍了Hadoop YARN的基本原理和运行流程,包括ResourceManager、NodeManager、ApplicationMaster和Container的角色,阐述了YARN的扩展性和容错性,以及MapReduce 2.0与YARN的关系,揭示了YARN如何支持多计算框架在Hadoop集群中资源共享和互不干扰的运行。
本文详细介绍了Hadoop YARN的基本原理和运行流程,包括ResourceManager、NodeManager、ApplicationMaster和Container的角色,阐述了YARN的扩展性和容错性,以及MapReduce 2.0与YARN的关系,揭示了YARN如何支持多计算框架在Hadoop集群中资源共享和互不干扰的运行。
一、概述
Yarn是Hadoop集群的资源管理系统。Hadoop2.0对MapReduce框架做了彻底的设计重构,我们称Hadoop2.0中的MapReduce为MRv2或者Yarn。我们先回头看一下Hadoop1.x的MapReduce模型。
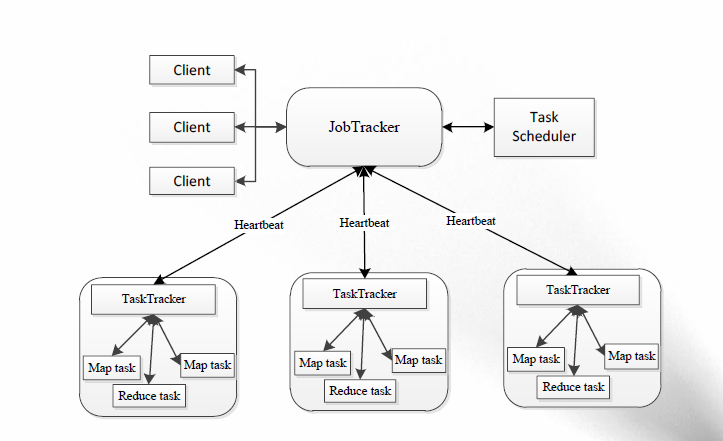
Yarn的产生直接源于MRv1在几个方面的缺陷
- 扩展性受限
- 单点故障
- 难以支持MR之外的计算
- 多计算框架各自为战,数据共享困难
MR:离线计算框架
Storm:实时计算框架
Spark:内存计算框架
到了Hadoop2.x也就是Yarn,它的目标是将功能分开,也就是分别用两个进程来管理这两个任务:
- ResourceManger
- ApplicationMaster
需要注意的是,在Yarn中我们把job的概念换成了application,因为在新的Hadoop2.x中,运行的应用不只是MapReduce了,还有可能是其它应用如一个DAG(有向无环图Directed Acyclic Graph,例如storm应用)。Yarn的另一个目标就是拓展hadoop,使得它不仅仅可以支持MapReduce计算,还能很方便的管理诸如Hive、Hbase、Pig、Spark/Shark等应用。这种新的架构设计能够使得各种类型的应用运行在Hadoop上面,并通过Yarn从系统层面进行统一的管理,也就是说,有了Yarn,各种应用就可以互不干扰的运行在同一个Hadoop系统中,共享整个集群资源,如下图所示:
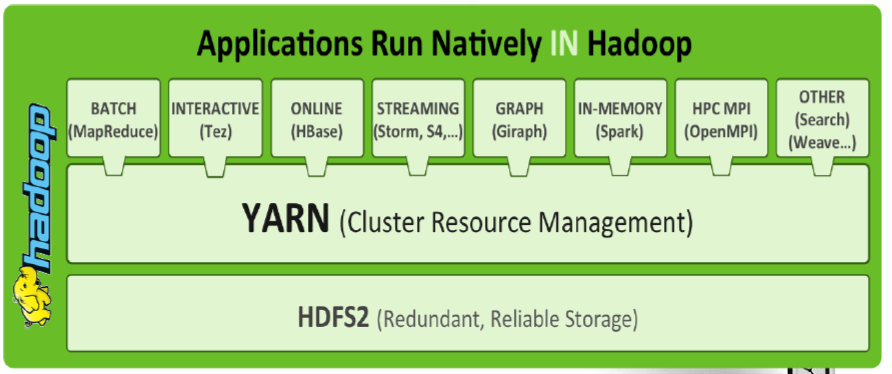
二、Yarn的基本架构
YARN总体上仍然是Master/Slav
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









