









参考了这个http://www.cppblog.com/zxb/archive/2010/10/06/128782.aspx?opt=admin
他用的是hash的思想
题目大意是:给一个字符串,在给个子串,求子串是否在是整个字符串的子串,字符串之间的匹配遵循相对位置
例如给定:5 6 2 10 10 7 3 2 9
然后子串: 1 4 4 3 2 1它与 2 10 10 7 3 2对应,相对位置一样
考虑两个字符串A,B
A[1],A[2],…,A[k]与B[1],B[2],…,B[k]匹配条件:
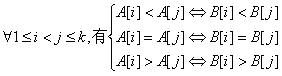
若A[1],A[2],…,A[k-1]与B[1],B[2],…,B[k-1]匹配,则加上A[k]与B[k]仍然匹配的条件是:
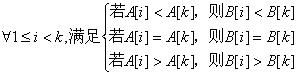
所以可以通过匹配子串的相对位置来判断模式串的相对位置是否跟其对应
考虑到字符集很小(不超过25),我们可以定义以下几个变量:
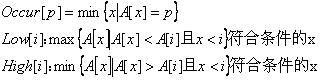
Occur[p],Low[i],High[i]可能不存在,若存在则取最小的符合条件的x
则A[1],A[2],…,A[k-1]与B[1],B[2],…,B[k-1]匹配,加上A[k]与B[k]仍然匹配的条件可简化为:
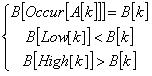
上面的Occur就是相当于一个hash把匹配串的值与其坐标位置对应,只不过相同值得数取最小下标
然后low[i]表示第i个数左边最靠近i且比A[i]小的数的值
high[i]表示第i个数右边最靠经i且比A[i]大的数
那么前面的等式就是转换成下面的那个B的等式
这里注意A是匹配串是从1~n的,B是模式串A[i]与B[j]想比较的时候,B[j]是个相当位置,是从 j - i + 1 ~~~i与上面等式的B[1], B[2]~~对应的
下面是实现代码:
#include <iostream>
#include <cstdio>
#include <cstring>
using namespace std;
int hash[300],low[250100],high[250100],next[250100];
int a[250100],b[1000100];
int ans[1000100];
int n, k, s;
bool cmp(int *a, int *b, int k);
int main()
{
int i, j;
scanf("%d %d %d", &n, &k, &s);
for(i = 0; i < n; i++)
scanf("%d", &a[i]);
memset(hash, -1, sizeof(hash));
hash[0] = hash[s + 1] = -2;
for(i = 0; i < k; i++)
{
scanf("%d", &b[i]);
if(hash[b[i]] == -1)
hash[b[i]]= i;
for(j = b[i] - 1; hash[j] == -1; j--);
low[i] = hash[j];
for(j = b[i] + 1; hash[j] == -1; j++);
high[i] = hash[j];
}
i = 0, j = -1;
next[0] = -1;
while(i < k)
{
if(j == -1 || cmp(b, b + i - j, j))
{
i++; j++;
next[i] = j;
}
else
j = next[j];
}
int t = 0;
i = 0, j = 0;
while(i < n)
{
if(j == -1 || cmp(b, a + i - j, j))
{
i++;
j++;
}
else
j = next[j];
if(j == k)
{
ans[t++] = i - k + 1;
j = next[j];
}
}
printf("%d\n", t);
for(i = 0; i < t; i++)
printf("%d\n", ans[i]);
return 0;
}
bool cmp(int *a, int *b, int k)
{
if(b[hash[a[k]]] != b[k])
return false;
if(low[k] >= 0 && b[low[k]] >= b[k])
return false;
if(high[k] >= 0 && b[high[k]] <= b[k])
return false;
return true;
}















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









