







最近要有一个任务,要爬取https://xueqiu.com/#/cn 网页上的文章,作为后续自然语言处理的源数据。
爬取目标:下图中红色方框部分的文章内容。(需要点击每篇文章的链接才能获得文章内容)
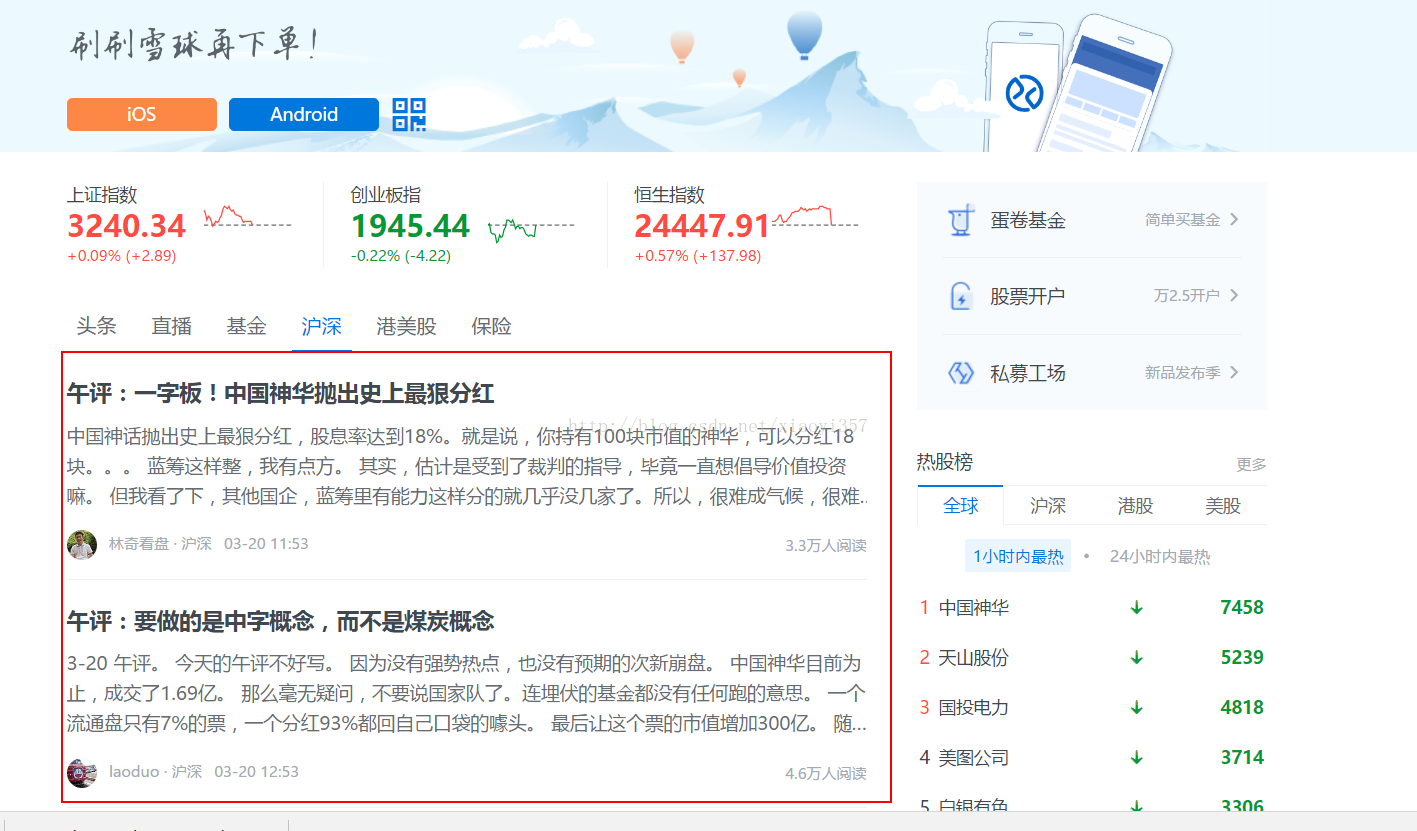
注:该文章仅介绍爬虫爬取新闻这一部分,爬虫语言为Python。
乍一看,爬虫的实现思路很简单:
(1)从原始页面https://xueqiu.com/#/cn上爬取各篇文章的URL
(2)通过第一步所获得的各篇文章的URL,抓取文章内容。
但是发现简单使用urllib2.urlopen()并不能获得红框部分的数据,原因是该部分数据是通过JS动态加载的。
最终发现可以采用Selenium框架来抓取动态数据。Selenium原本是Web测试工具,在Python爬虫中,可以使用它来模拟真实浏览器对URL进行访问,Selenium支持的浏览器包括Firefox、Chrome、Opera、Edge、IE 等。在此我使用的是Firefox浏览器。
Python爬虫脚本如下,可以参考注释来理解代码:
# coding=utf-8
import time
import Queue
import pymongo
import urllib2
import threading
from bs4 import BeautifulSoup
from BeautifulSoup import *
from selenium import webdriver
from selenium.webdriver.common.by import By
# 连接本地MongoDB数据库
client = pymongo.MongoClient()
# 数据库名为shsz_news
db = client.shsz_news
# collection名为news
collection = db.news
# 文章存储数据结构为:标题 作者 文章发布时间 阅读量 文章内容
# title author timestamp read content
class Article:
title = ""
url = ""
author = ""
timestamp = ""
read = 0
content = ""
def __init__(self, title, url, author, timestamp, read, content):
self.title = title
self.url = url
self.author = author
self.timestamp = timestamp
self.read = read
self.content = content
# 参数为:点击多少次"加载更多"
# 返回值为文章的url列表,数据总条数为:50 + 15 * num
def get_article_url(num):
browser = webdriver.Firefox()
browser.maximize_window()
browser.get('http://xueqiu.com/#/cn')
time.sleep(1)
# 将屏幕上滑4次,之后会出现“加载更多”按钮——此时有50篇文章
for i in range(1, 5):
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1)
# 点击num次“加载更多”——每次点击会加载15篇新闻
for i in range(num):
# 找到加载更多按钮,点击
browser.find_element(By.LINK_TEXT, "加载更多").click()
time.sleep(1)
soup = BeautifulSoup(browser.page_source)
# 解析html,获取文章列表
article_queue = parse_html(soup)
browser.close()
return article_queue
# 解析html,返回Article的队列
def parse_html(soup):
article_queue = Queue.Queue()
article_divs = soup.findAll('div', {'class': 'home__timeline__item'})
if article_divs is not None:
for article_div in article_divs:
# 获取文章url
url = dict(article_div.h3.a.attrs)['href']
article_url = 'https://xueqiu.com' + url
# 获取文章标题
article_title = article_div.h3.a.string
# 获取文章作者
article_author = article_div.find('a', {'class': 'user-name'}).string
# 获取文章发布时间
article_timestamp = article_div.find('span', {'class': 'timestamp'}).string
# 获取文章阅读量
article_read = article_div.find('div', {'class': 'read'}).string
# 构造article对象,添加到article_queue队列中
article = Article(url=article_url, title=article_title, author=article_author,
timestamp=article_timestamp, read=article_read, content='')
article_queue.put(article)
return article_queue
# 获取文章内容的线程
class GetContentThread(threading.Thread):
def __init__(self, article_queue):
threading.Thread.__init__(self)
self.url_queue = article_queue
def run(self):
count = 0;
while 1:
try:
count += 1
# 打印每个线程的处理进度...
if count % 100 == 0:
print count
article = self.url_queue.get()
# 获取文章url
article_url = article.url
request = urllib2.Request(article_url)
request.add_header('User-Agent', 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6')
response = urllib2.urlopen(request, timeout=10)
chunk = response.read()
soup = BeautifulSoup(chunk)
# 将文章内容解析出来
content = soup.find('div', {'class': 'detail'})
# 需要使用str()函数,否则无法保存到mongoDB中
article.content = str(content)
try:
# 将article信息写入mongoDB数据库
collection.save(article.__dict__)
except Exception, e:
# 该方法提示q.join()是否停止阻塞
self.url_queue.task_done()
# 将该文章重新放入队列
self.url_queue.put(article)
print "Save into MongoDB error!Let's make a comeback "
# 该方法提示q.join()是否停止阻塞
self.url_queue.task_done()
except Exception, e:
# 该方法提示q.join()是否停止阻塞
self.url_queue.task_done()
print 'get content wrong! ', e, '\n'
# 出现异常,将异常信息写入文件
file1 = open('get_content_wrong.txt', 'a')
file1.write(str(article.title) + '\n')
file1.write(str(article.url) + '\n')
file1.write(str(e) + '\n')
file1.close()
if '404' in str(e):
print 'URL 404 Not Found:', article.url
# 如果错误信息中包含 'HTTP' or 'URL' or 'url' ,将该地址重新加入队列,以便稍后重新尝试访问
elif 'HTTP' or 'URL' or 'url' in str(e):
self.url_queue.put(article)
print "Let's make a comeback "
continue
def main():
# 获得所有的文章,并将它们放入队列中
article_queue = get_article_url(150)
# 创建10个线程,获取所有文章的具体内容,并写入mongoDB数据库
for i in range(10):
gct = GetContentThread(article_queue)
gct.setDaemon(True)
gct.start()
# 等待队列中的所有任务完成
article_queue.join()
main()














 579
579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









