







在map进行操作之后数据应该存在对应的文件中,一般这里涉及到MapFile和SequenceFile,后者主要是记录key/value的列表信息
同时是二进制处理之后的数据,直接看是没有办法的
利用命令 hadoop fs -text 文件的位置
sequence中有三种不同类型的结构
1 未压缩的key/value对
2 记录压缩的key/value对,(这里一般是只对value进行压缩) 前两者压缩在数据记录的格式上是相同的
3 block压缩key/value对(这里是key,value值分别被记录到块中并进行了压缩处理)
这里将一个文件写入sequenceFile中,按照,key,value格式,模仿map的数据输出,然后利用命令行进行观察验证
package com.read;
import java.io.*;
import java.net.URI;
import java.util.Comparator;
import org.apache.commons.compress.utils.IOUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
public class ReadSeqeneFile{
private static String[] myValue =
{
"hello word",
"bye word",
"hello hadoop",
"byte hadoop",
};
public static void main(String[] args) throws IOException{
String uri = "hdfs://127.0.0.1:8020/user/trunck/input/fileseq";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri),conf);
Path path = new Path(uri);
IntWritable key = new IntWritable();
Text value = new Text();
SequenceFile.Writer writer = null;
try {
writer = SequenceFile.createWriter(fs, conf, path, key.getClass(), value.getClass());
for(int i = 0; i < 5; i++)
{
key.set(500-i);
value.set(myValue[i%myValue.length]);
writer.append(key, value);
}
} catch (Exception e) {
// TODO: handle exception
}finally
{
org.apache.hadoop.io.IOUtils.closeStream(writer);
}
}
}
运行完成后可以看到我的hdfs上多了输出文件
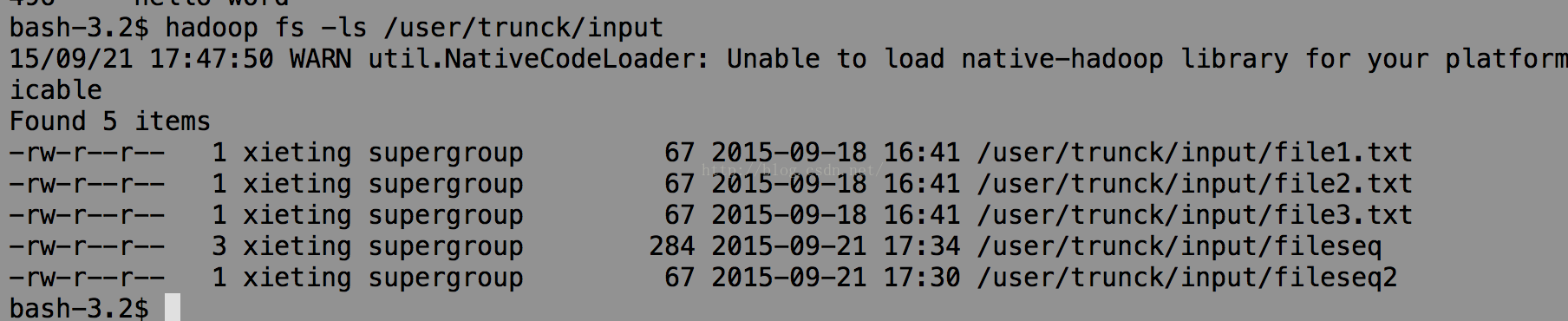

再完成一个从sequenceFile中读数据的过程
public static void read() throws IOException {
String uri = "hdfs://127.0.0.1:8020/user/trunck/input/fileseq";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri),conf);
Path path = new Path(uri);
SequenceFile.Reader reader = null;
try {
reader = new SequenceFile.Reader(fs, path, conf);
Writable key = (Writable)ReflectionUtils.newInstance(reader.getKeyClass(), conf);
Writable value = (Writable)ReflectionUtils.newInstance(reader.getValueClass(), conf);
long position = reader.getPosition();
while(reader.next(key,value)) {
String syn = reader.syncSeen()?"*":"";
System.out.printf("[%s%s]\t%s\t%s\n",position,syn,key,value);
position = reader.getPosition();//转到下一条记录的开始位置
}
} catch (Exception e) {
// TODO: handle exception
}finally
{
org.apache.hadoop.io.IOUtils.closeStream(reader);
}
}
public static void main(String[] args) throws IOException {
read();
}对应输出结果:

还有一个也是进行中间存储的类叫做MapFile
建立mapFile的过程中主要一个变化是对sequence file进行了排序,而index就是索引的值
其中索引的间隔是通过 io.map.index.interval进行设定的
其中的writer 和 reader的处理和之前的sequence中基本是相似的
public static void writeMapFile() throws IOException{
String uri = "hdfs://127.0.0.1:8020/user/trunck/input/fileMapFile";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri),conf);
IntWritable key = new IntWritable();
Text value = new Text();
MapFile.Writer writer = null; //<申请对应部分的writer类型
try {
writer = new MapFile.Writer(conf,fs,uri,key.getClass(),value.getClass());
for(int i = 0; i < 5; i++)
{
key.set(i);
value.set(myValue[i%myValue.length]);
writer.append(key, value);
}
} catch (Exception e) {
// TODO: handle exception
}finally
{
org.apache.hadoop.io.IOUtils.closeStream(writer);
}
}
@SuppressWarnings("deprecation")
public static void readMapFile() throws IOException {
String uri = "hdfs://127.0.0.1:8020/user/trunck/input/fileMapFile";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri),conf);
MapFile.Reader reader = null;
try {
reader = new MapFile.Reader(fs, uri, conf);
WritableComparable<?> key = (WritableComparable<?>)ReflectionUtils.newInstance(reader.getKeyClass(), conf);
WritableComparable<?> value = (WritableComparable<?>)ReflectionUtils.newInstance(reader.getValueClass(), conf);
while(reader.next(key,value))
{
System.out.printf("%s\t%s\n",key,value);
}
} catch (Exception e) {
// TODO: handle exception
}finally
{
org.apache.hadoop.io.IOUtils.closeStream(reader);
}
}在hdfs中运行的结果:

mapfile执行的结果是一个文件夹
里面包含两个文件
其中data和index的内容:

index中表示索引是按照128键进行建立的
其中在reader的过程中可以按照合适的key值获得对应的value值
reader.get(new IntWritable(3),value);
System.out.printf("%s\n",value);
在查找的过程中,一般的方法是
先在索引中找到小于key值对应的是索引
再进入data文件中在index之后进行相应的查找操作
注意: 一般在MapFile中的索引会占用比较大的内存,减少内存的一个方法是加大间隔,但是会影响索引的值
还有一个比较好的办法就是在读index的过程中,可以跳过几个再读一次
通过io.map.index.skip进行设置
三 ArrayFile SetFile BloomMapFile
ArrayFile:
继承MapFile ,key可以直接确定为IntWriterable
SetFile:
其实是key值对应的set集合,其中的value的值设置为nullwritable进行占位符
其中在进行插入的时候必须是key值增序进行插入
bloommapfile:
主要的函数没有变化,一般是查询key值是否在集合之中














 250
250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









