







注:由于人个技术水平有限,文中的技术及原理也都只是点到为止,文中的难免会有很多疏漏甚至错误,请大家指正(本文会陆续更新),同时有一些理论是参考各个牛人的研究成果,这里只是做以引用。
步骤1. 候选集的召回
步骤2. 粗排
步骤3. 精排
步骤3. 业务场景下的规则过滤与重排序
召回
一 Content-based
二、Item-Based
即:共同喜欢同一物品用户的比例 同时购买i和j物品的用户数除以购买i用户数和购买用户j的用户的并集
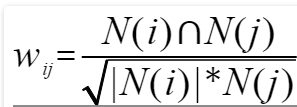
这里只是考虑了购买或者发生行为的用户数量的比,但实际上还需要:
2.1 考虑用户对物品的评分喜好程度
2.2 对热门物品的惩罚
三、User-Based
基于用户的推荐是,寻找和用户U相似的几个用户V,把V喜欢的物品推荐给U
总的来说,当用户的数据远大于item的时候,可以使用item based 多用于早期的电商网站,而user based的,由于用户的关系相对比较稳定,所以这里多为新闻网站使用User based
注:当然这些都是很老的用法了,现在无论是电商还是信息类网站都早已不只是这些简单的召回方法了,后面会一一补充
- i2i:计算item-item相似度,用于相似推荐、相关推荐、关联推荐;
- u2i:基于矩阵分解、协同过滤的结果,直接给u推荐i;
- u2u2i:基于用户的协同过滤,先找相似用户,再推荐相似用户喜欢的item;
- u2i2i:基于物品的协同过滤,先统计用户喜爱的物品,再推荐他喜欢的物品;
- u2tag2i:基于标签的泛化推荐,先统计用户偏好的tag向量,然后匹配所有的Item,这个tag一般是item的标签、分类、关键词等tag;
四、基于矩阵分解推荐算法
前序,矩阵的特征值分解
特征值分解 Ax=λx
其中,A是一个n * n的矩阵,x是一个n维向量,λ是矩阵A的一个特征值,而x是λ对应的一个特征向量。
特征向量的含义是:特征向量x通过方阵A变换,只进行缩放,并不改变方向
其中Q是这个矩阵甲的特征向量组成的矩阵,Σ是一个对角阵,每一个对角线上的元素就是一个特征值。一个矩阵的一组特征向量是一组正交向量。
如A不是方阵,那么矩阵也是可以分解的,最常用的方法是SVD,下面进行介绍。
特征值分解必须是可对角化矩阵(所以必须是方阵。n阶方阵可对角化的定义是相似于一个对角矩阵,充要条件是A有n个线性无关的特征向量[11]),奇异值分解则适用于任意矩阵。
4.1 SVD


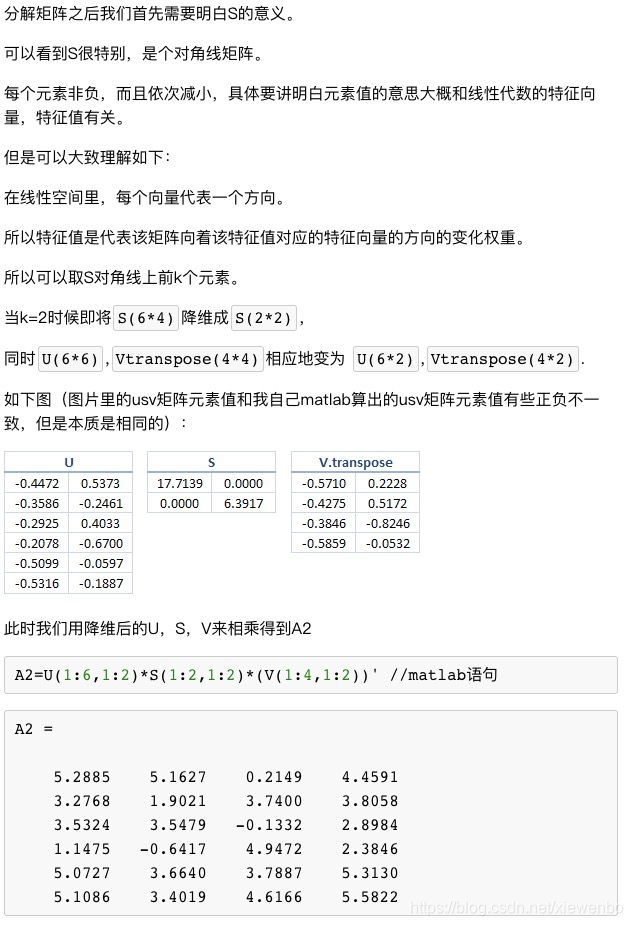
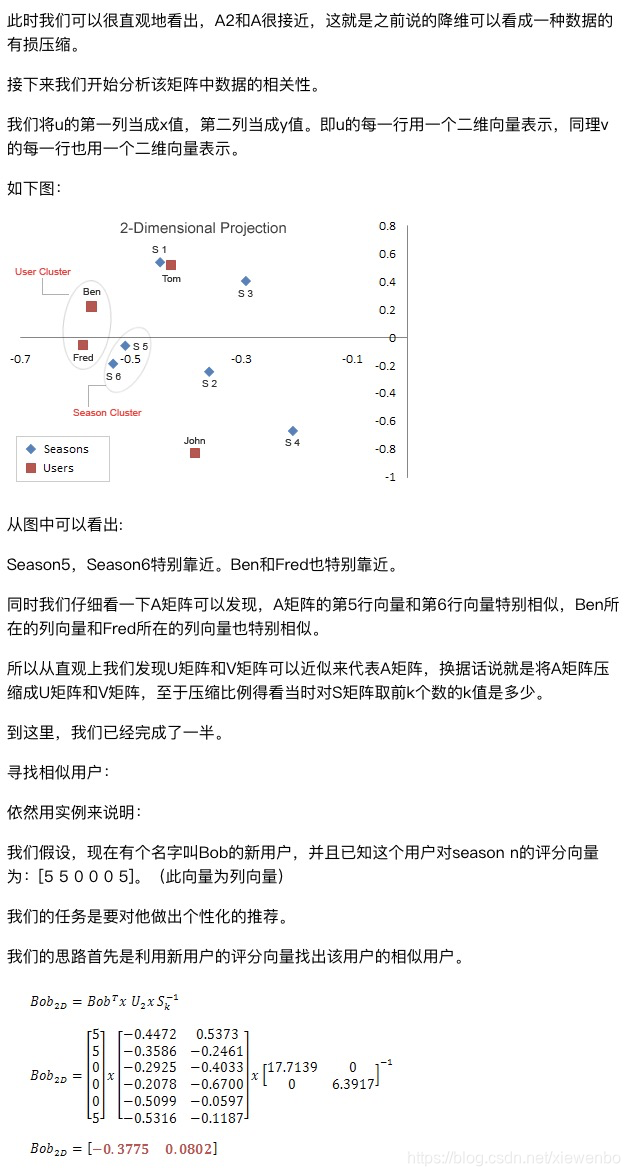
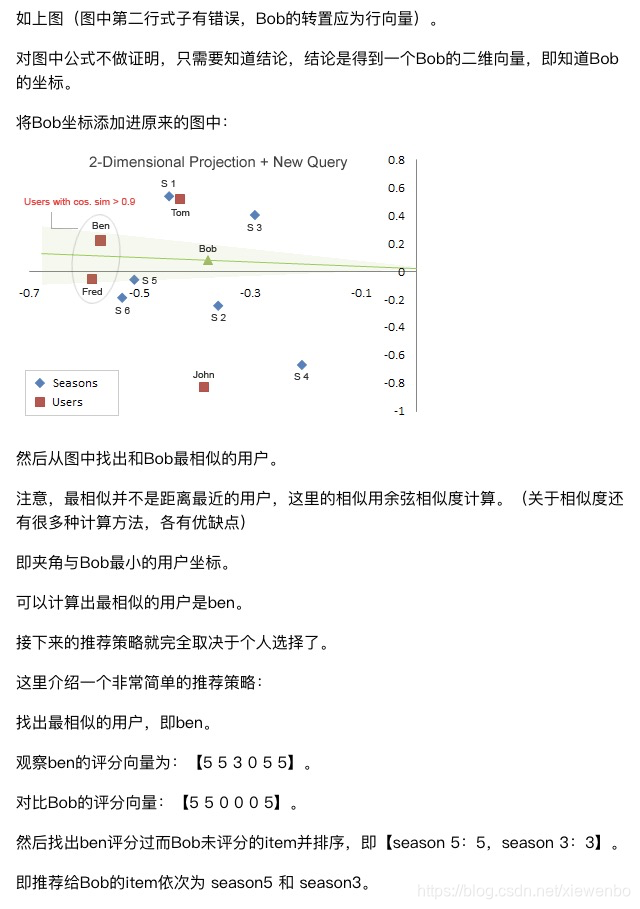

上面截图来处:http://yanyiwu.com/work/2012/09/10/SVD-application-in-recsys.html
4.2 SVD++
4.3 LFM
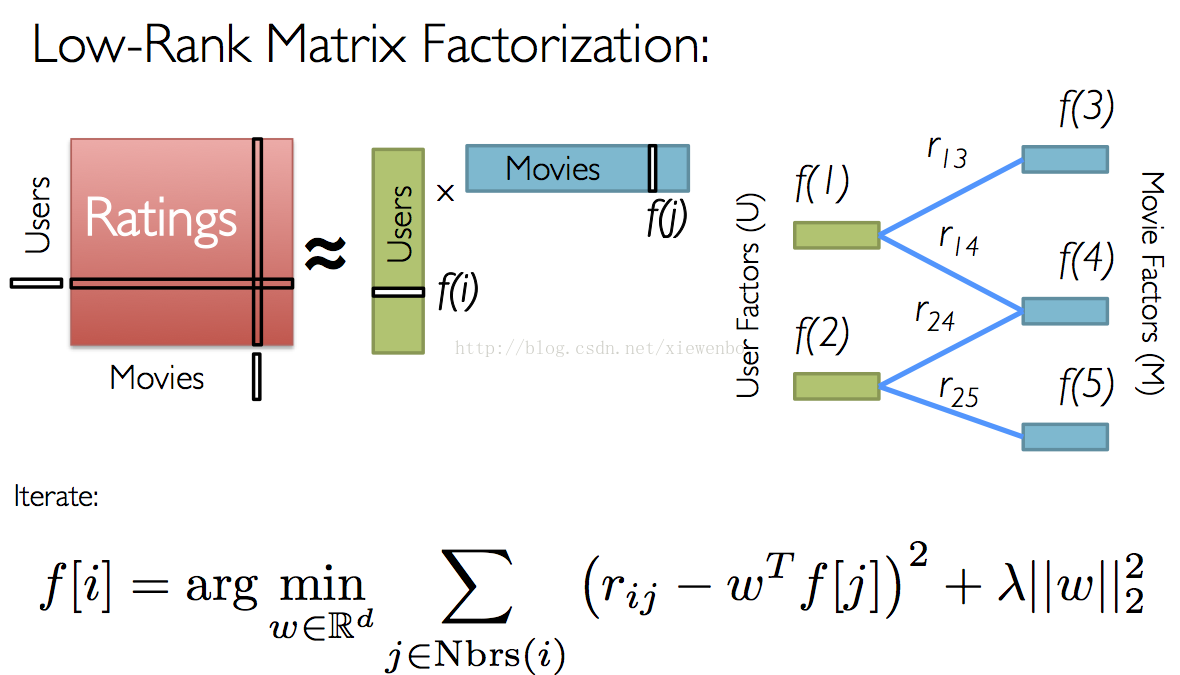
一般情况下,user-item的评分矩阵A,是一个M * N 且纬度很高,但是很稀疏的矩阵,这里我们需要通过矩阵分解,将A分解成U*V的乘积来表示,并尽可能保证A'=U*V,这样Aij =ΣUi*Vj 由于A是由U V 乘积的逼近,所以可以和U V 中的user class vec 和 item class vec 的点积来表示。

求解矩阵比U和V比较方便的一种方法是:ALS (交替最小二乘法),大体的思想是:先随机给Ui赋值,然后固定Ui求得Vi,然后利用Vi再去求Ui,如果交替下去直到误差平方和小于指定的阈值,或者迭代次数到达预期的次数,取得最新的UV矩阵,则原本的稀疏矩阵R就可以用R=U(V)T来表示了
五、Restricted Boltzmann Machines for Collaborative Filtering & Learning Deep Generative Models
5.1 BM
5.2 RBM
Most of the existing approaches to collaborative filtering cannot handle very large data sets. In this paper we show how a class of two-layer undirected graphical models, called Restricted Boltzmann Machines(RBM's), can be used to model tabular data,such as user's ratings of movies.
很多的CF算法,对于处理海量数据在性能上会有问题,但是RBM这个两层的无向图却能够很好的解决这个问题,比如,视频推荐打分这方面的业务 ,RBM就有不错的表现
5.2.1 RBM介绍
5.2.2 RBM应用于个性化推荐
RBM本质上是一个编码解码器,通过RBM,我们可以把原始输入数据从Visible Units 到 Hidden Units,得到原始输入数据的隐因子(latent factor)向量表示,这一过程也称为编码过程,然后利用得到的隐藏层向量重新映射回可视层,得到新的可视层数据,这个过程称为解码过程,我们的目标是让解码后的结果能和原始数据尽量接近,这样,在解码的过程中,我们不但能得到已评分物品的新的评分数据,还能对未评分的物品的得分进行预测,这些未评分物品的分数从高到低的排序形成推荐列表。
这个思想和LFM的思想很类似,对于一个user_item的M*N的评分矩阵,非常稀疏,将其分解为维度较小的P*Q的两个低维矩阵的乘积,分别代表user的隐含属性 p * i 和item的 i * q的隐含属性,这里如果要预测user_j 对item_k的评分,只需要将矩阵P的第j行与物品j的第k列相乘即可,就通过矩阵的回乘,不仅仅得到了原有的评分,对于missing score也得到了一个预测值
5.3 DBM
5.4 Deep Learning
根据用户的长期历史数据来挖掘隐特征是协同过滤常用的方法,典型的算法有基于神经网络的受限玻尔兹曼机 (RBM),基于矩阵分解的隐语义模型等。历史的数据反映了用户的长期兴趣,但在很多推荐场景下,我们发现推荐更多的是短时间内的一连串点击行为,例如在音乐的听歌场景中,用户的听歌时间往往比较分散,有可能一个月,甚至更长的时间间隔才会使用一次,但每一次使用都会产生一连串的点击序列,并且在诸如音乐等推荐领域中,受环境心情的影响因素很大,因此,在这种推荐场景下,基于用户的短期会话行为(session-based) 能够更好的捕获用户当前的情感变化。
另一方面,通过用户的反馈,我们也不难发现,用户的序列点击行为并不是孤立的,当前的点击行为往往是受到之前的结果影响,同理,当前的反馈也能够影响到今后的决策,长期历史数据的隐特征挖掘无法满足这些需求。
RNN是解决序列性相关问题的常用网络模型,通过展开操作,可以从理论上把网络模型扩展为无限维,也就是无限的序列空间。(这里说点和主题无关的东西)对于时序问题,第一次接触是做广告投展示次数预测,用到的是ARIMA-Autoregressive Integrated Moving Average Model,这是比较适合的是单因子的数值波动的预测,感觉比较适合的领域有
排序
六、候选融合与重排序
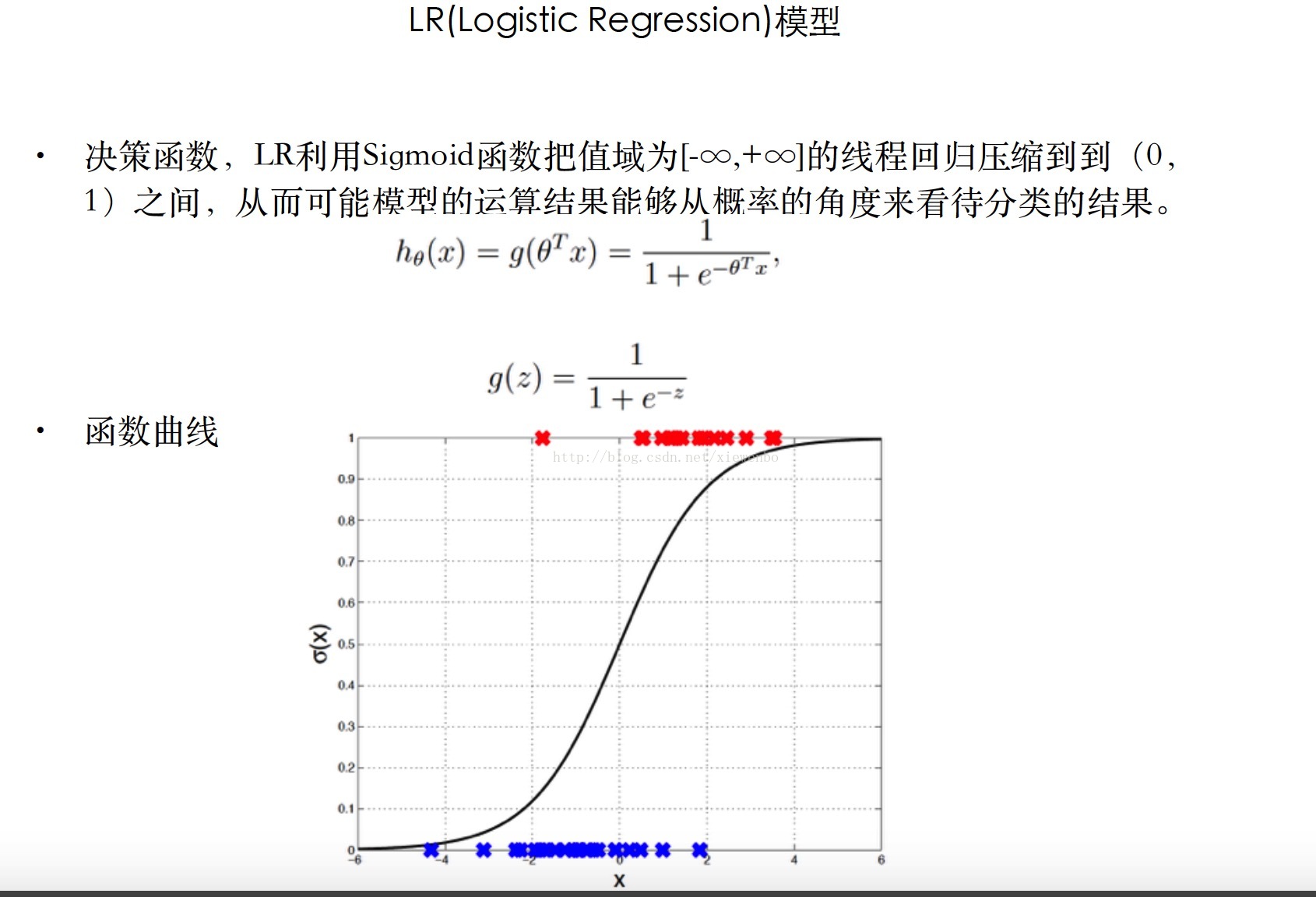
6.1 LR
最早接触LR是在做广告CTR prediction (点击率预测)的时候,那个时候每天都在关注算法的调整对整个收入的影响,生怕出现什么线上事故,呵呵,走偏了。


6.2 GBDT+LR
6.3 wide&deep with FTRL
6.4 DeepFM & xDeepFM
6.4 DNN/DIN
八、反作弊相关
参考资料:
1 http://mp.weixin.qq.com/s?__biz=MzA3MDQ4MzQzMg==&mid=2665690422&idx=1&sn=9bd671983a85286149b51c908b686899&chksm=842bb9b1b35c30a7eedb8d03e173aa8f43465db90e11075ac0c73b1784582f21eb93dcbd3e65&scene=0#wechat_redirect
2. Restricted Boltzmann Machines for Collaborative Filtering University of Toronto, 6 King's College Rd., Toronto, Ontario M5S 3G4, Canada
3. http://yanyiwu.com/work/2012/09/10/SVD-application-in-recsys.html
其它:1. 《Neural Input Search for Large Scale Recommendation Models》笔记 https://blog.csdn.net/xiewenbo/article/details/103724316
后记,
第一次接触推荐系统这个领域还是在学校的时候,在一家公司实习的时候,当时的企业导师Larry Luo ,是Netflix百万美金挑战赛的团体第二,the Ensemble ,印象中好像是,和第一名推荐算法准确度相同,只是提交时间差了20分钟














 646
646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









