







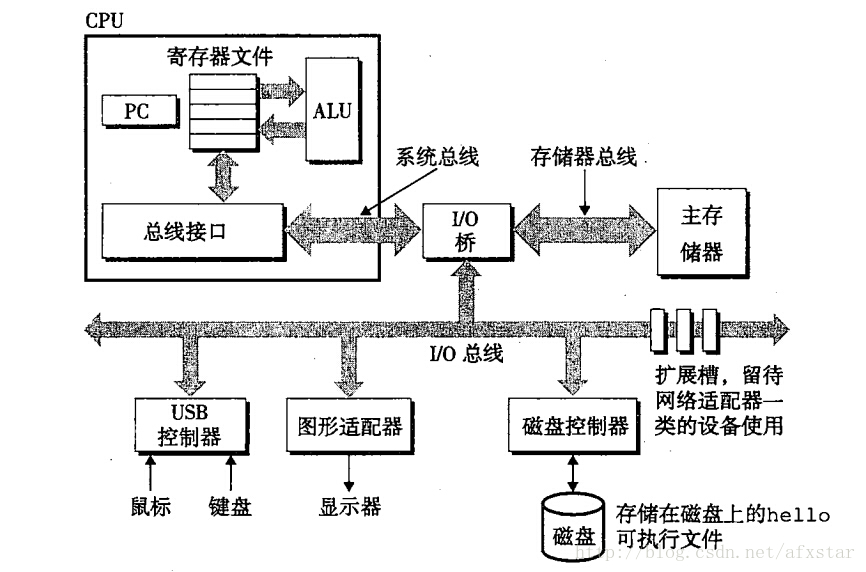
前言:现代计算机仍然使用图灵机模型,被分为CPU、存储器、I/O设备三部分,这三部分主要用于计算、存储、通信。这幅图是文章研究的重点。
在计算机内部,信息被表示成位序列,根据不同的上下文有不同的解释。
本章主要研究计算机中最重要的的三种的表示:
无符号-表示大于或等于0的整数,基于传统的二进制编码。
补码-表示有符号整数的编码,也成为负权编码。
浮点数-数学的科学计数法,以二进制位基数的版本。
通过研究数据的实际表示,能够理解位序列的值范围和不同运算属性。使编写的程序可以再在表示范围内正常工作,并且具有可以跨越不同机器、平台、和编译器的可移植性。同时大量的安全漏洞都是由于计算机算数运算的微妙细节引起的,对数据的实际表示有利于避免安全漏洞。
大多数计算机使用8个块(byte)作为最小的可寻址的存储单元,最小的可寻址单元不是位。程序将存储器看做一个很大的地址数字,成为虚拟存储器。存储器的每一个字节都由一个唯一的地址来标识,所有的地址的集合叫做虚拟地址空间。
一个字节8位,每一个位都用2进制的表示。然而2进制表示太冗长,不方便理解记忆,因而采用16进制来书写记忆。16进制以0x或0X开头,每一个16进制位表示4个二进制位,也就是说一个十六进制0代表四个个二进制0。
一般32位机器和64位机器的数据的大小如图2-3:
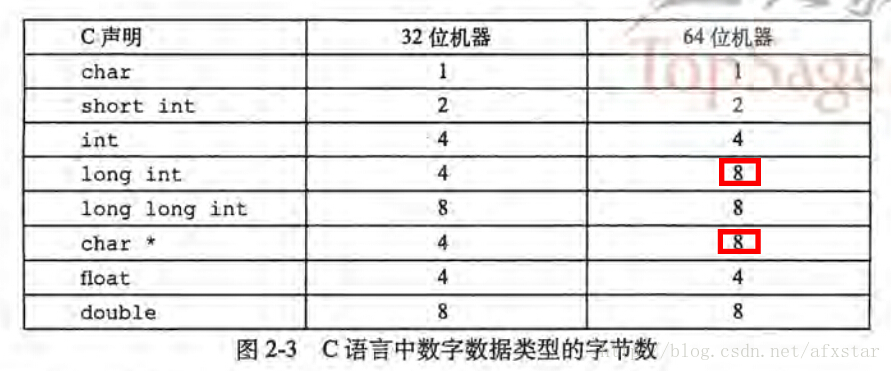
随着64位机器的普及,在将一些新程序移植到新机器上时,许多隐藏的对数据长度依赖就会显现出来。例如许多程序员将一个int变量用来存储指针,这个程序在32位机器上可以正常工作,但是在64位机器上就会导致问题。
在几乎所有机器上,多个字节的对象被存储为连续字节序列,对象的地址为采用低地址(字节中的最小地址),也就是说寻址寻的是最小地址,这个很重要。对于小端模式,低位放在低地址;对于大端模式,高位放在低地址。例如int a = 0x0124567,小端模式&a对应的地址为67的地址,而大端模式a的地址为01对应的地址。了解大端小端模式,在网络通信的数据传输方面、阅读整型的字节序列时十分重要!在查看字节序列时,可以通过usigned char *指针来访问每一个字节。
无符号数假设有w位,二进制模型为[Xw-1, Xw-2, ..., X1, X0],转化为十进制大小范围为:[0, 2^w - 1]。补码是最高位为负权的编码,例如10011 = -2^4 + 2^1 + 2^0,最高位的权重为-2^(w-1), 能表示的最大数为 [0111...111] = 2^(w-1) - 1, 能表示的最小数为[1000...000] = -2^(w-1).
关于有符号数与无符号数的转化,数的位级表示不便,即存储在存储器中的位是不变的。但是表示的数值是有变化的,可能会超出能表示的范围。例如32位有符号数[111...1111] = -1, 若将其转化为无符号数则表示INT_MAX = 2147483647, 这里很小的有符号负数转化为无符号整数可能会得到一个大数。而在运算过程中,如果一个数为有符号、另一个为无符号,计算之前有符号数会被转化为无符号数,并且要假设两个都是正数来进行计算(实际是非负,便于记忆)。
关于数据宽度的转化,从一个较小的宽度化为一个较大的宽度,对于无符号数采用0扩展,对于有符号数采用符号扩展,可以统称为符号扩展(便于记忆)。而当同时进行有符号、无符号‘和 数据宽度转化时,先考虑大小后考虑符号,例如signed short a转化为 unsigned int a,a = unsigned (int) a. 而将大宽度转化为小宽度,则采用截断的方式。在做算术运算时,有必要考虑溢出问题,因为绝大多数的系统漏洞都和算术运算溢出有关,一个航天项目中出现一个算术运算溢出而没处理,会导致火箭脱离系统的控制,早晨巨大的损失,慎之!!
对于浮点数,先了解二进制小数,二进制小数可以表示为:Bm-1 Bm-2 ...B0 . B-1 B-2 ... B-n。小数点向左移一位表示除以二,例如10.111表示2 + 0 + 1/2 + 1/4 +1/8。定点数无法表示很大的数,浮点数解决了这个问题。浮点数以[符号,阶码,尾数]形式来表示,并且以2为基数。根据这个表示,浮点数倍分为以下几种情况:规格化数、非规格化数、无穷大、NaN。当 0<阶码<255时为规格化数、当阶码=0时表示非规格化数、当阶码=255而尾数为0时表示无穷大,当阶码=255而尾数!=0时表示不是一个数。
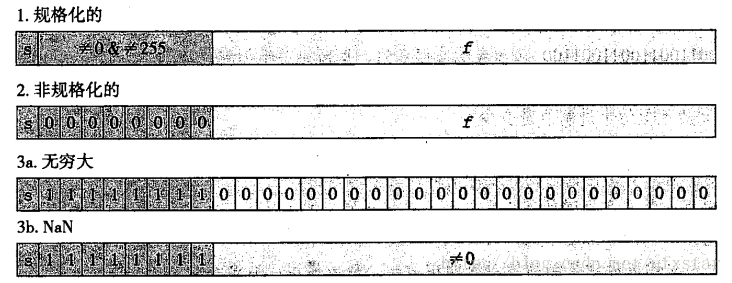
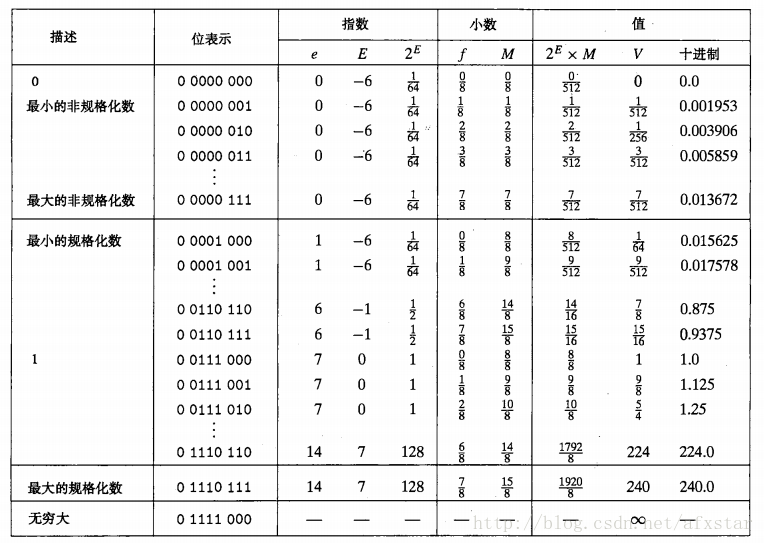
若浮点数表示为(-1)^S * 2^E * M,那么阶码的表示为:E = e - bias, 尾数表示为:M = 1.f0f1f2...,其中e为正数包括0。例如12345 = 1.1000000111001 * 2^13,那么M为1000000111001,E为13,e = bias + E = [10001100],于是得到浮点表示0 10001100 10000001110010000000000。对于非规格化数,之所以存在是因为规格化数的M >= 1,因此呼号表示零,同时非规格化数的E = 1 - bias,M = 0.f0f1f2...。对于1位符号位为0,4位阶码、3位符号位这样的浮点数,其表示如下表:
对于浮点数的舍入有四种方法:向偶舍入、向最零舍入、向上舍入、向下舍入。其中向偶舍入有点难理解,就是向最近舍入和当小数位0.5时 向偶舍入。四舍五入不好的地方在于遇到0.5就入,在迭代计算中容易造成结果偏差,而向偶舍入相当于50%向上舍入+50%向下舍入能保持结果均衡。参考IEEE 754四种舍入方向。由于浮点数在运算后保存舍入结果,因此浮点数不具备交换律和分配律,因此计算过程中需要谨慎!C语言支持float和double,机器一般也采用向偶舍入来保存结构。而当float或者double转化为int时,一般采用向零舍入,但是C语言并没有这么规定,也就是说有例外。
结论:计算机的数据表示基础为二进制表示,采用原码、补码来表示整数、浮点数,在进行数据转化时尤其要注意溢出问题。而浮点数的舍入问题是客观存在的,浮点数迭代运算过程中,也尤其要注意结果的偏差与溢出问题。
计算机是由软件和硬件组成,它们共同协作来运行程序。程序被其它编译系统翻译成不同形式的位序列,从ASCII码到汇编代码最后到二进制可执行的机器代码。
其中机器代码用字节序列编码低级操作,如处理数据、存储数据、读写I/O设备上的数据、网络通信;汇编代码是对机器码的抽象,是机器码的文本表示便于阅读;而C语言等高级语言是对汇编代码的进一步抽象,它屏蔽掉了机器操作的实现的细节,这种抽象让开发效率更高更可靠。
这里主要学习汇编代码,原因如下:1.通过阅读汇编代码,能理解编译器的优化能力,并分析其中隐含的效率问题;2.当利用线程写并发程序时,知道存储器保存不同的程序变量区域是很重要的;3.具备汇编知识,可以聊些安全漏洞的产生原因,以及如何防御它们。
以Intel X86处理器模型为基础来了解汇编代码。8086是第一代单芯片、16位微处理器之一;80286增加了更多的寻址能力;i386将体系结构扩展到了32位,增加了平坦寻址模式,Linux和最近的windows都是使用的这种寻址方式。8086提供的存储模型,以及它在80286中的扩展已经过时。
机器级程序需要了解两种抽象机制,第一种是指令集系统是对计算机行为和状态的抽象,第二种抽象是寻址采用了虚拟存储器。
在学习机器级程序时,常用的一些工具命令如下:gcc -O1 -S code.c产生汇编代码;objdump -d code.o反汇编器查看汇编代码;gcc -O1 -o program code.o main.c














 1416
1416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









