






1
lucene
索引文件结构分析在分析lucene的索引文件结构之前,我们先要理解反向索引(invertedindex)这个概念,反向索引是一种以索引项为中心来组织文档的方式,每个索引项指向一个文档序列,
lucene
索引文件结构分析
在分析 lucene 的索引文件结构之前,我们先要理解反向索引(inverted index)这个概念,反向索引是一种以索引项为中心来组织文档的方式,每个索引项指向一个文档序列,这个序列中的文档都包含该索引项。相反,在正向索引中,文档占据了中心的位置,每个文档指向了一个它所包含的索引项的序列。你可以利用反向索引轻松的找到那些文档包含了特定的索引项。lucene正是使用了反向索引作为其基本的索引结构。
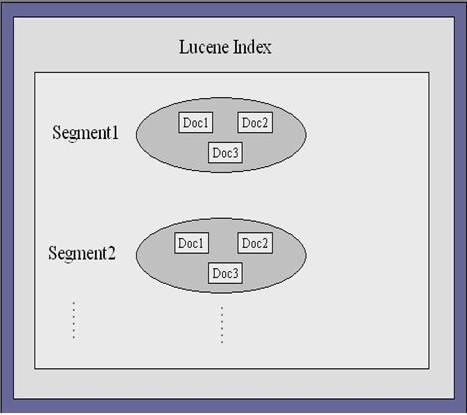
索引文件的逻辑视图
在lucene 中有索引块的概念,每个索引块包含了一定数目的文档。我们能够对单独的索引块进行检索。图 2 显示了 lucene 索引结构的逻辑视图。索引块的个数由索引的文档的总数以及每个索引块所能包含的最大文档数来决定。
图2:索引文件的逻辑视图
lucene
中的关键索引文件
下面的部分将会分析lucene中的主要的索引文件,可能分析有些索引文件的时候没有包含文件的所有的字段,但不会影响到对索引文件的理解。
1
.索引块文件
这个文件包含了索引中的索引块信息,这个文件包含了每个索引块的名字以及大小等信息。表 2 显示了这个文件的结构信息。
表2:索引块文件结构

2
.域信息文件
我们知道,索引中的文档由一个或者多个域组成,这个文件包含了每个索引块中的域的信息。表 3 显示了这个文件的结构。
表3:域信息文件结构

3
.索引项信息文件
这是索引文件里面最核心的一个文件,它存储了所有的索引项的值以及相关信息,并且以索引项来排序。表 4 显示了这个文件的结构。
表4:索引项信息文件结构

4
.频率文件
这个文件包含了包含索引项的文档的列表,以及索引项在每个文档中出现的频率信息。如果lucene在索引项信息文件中发现有索引项和搜索词相匹配。那么 lucene 就会在频率文件中找有哪些文件包含了该索引项。表5显示了这个文件的一个大致的结构,并没有包含这个文件的所有字段。
表5:频率文件的结构

5
.位置文件
这个文件包含了索引项在每个文档中出现的位置信息,你可以利用这些信息来参与对索引结果的排序。表 6 显示了这个文件的结构
表6:位置文件的结构

到目前为止我们介绍了 lucene 中的主要的索引文件结构,希望能对你理解 lucene 的物理的存储结构有所帮助。
Lucene
是一个基于
Java
的全文检索工具包,你可以利用它来为你的应用程序加入索引和检索功能。
Lucene
目前是著名的
Apache Jakarta
家族中的一个开源项目,下面我们即将学习
Lucene
的索引机制以及它的索引文件的结构。
在这篇文章中,我们首先演示如何使用
Lucene
来索引文档,接着讨论如何提高索引的性能。最后我们来分析
Lucene
的索引文件结构。需要记住的是,
Lucene
不是一个完整的应用程序,而是一个信息检索包,它方便你为你的应用程序添加索引和搜索功能。
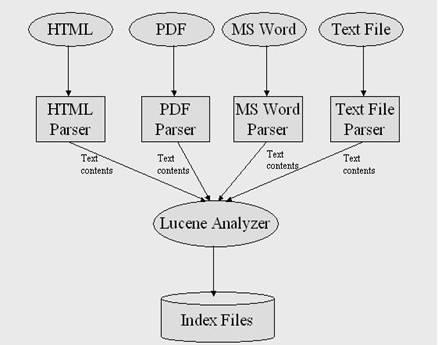
图一显示了
Lucene
的索引机制的架构。
Lucene
使用各种解析器对各种不同类型的文档进行解析。比如对于
HTML
文档,
HTML
解析器会做一些预处理的工作,比如过滤文档中的
HTML
标签等等。
HTML
解析器的输出的是文本内容,接着
Lucene
的分词器
(Analyzer)
从文本内容中提取出索引项以及相关信息,比如索引项的出现频率。接着
Lucene
的分词器把这些信息写到索引文件中。
 
|

|
接下来我将一步一步的来演示如何利用
Lucene
为你的文档创建索引。只要你能将要索引的文件转化成文本格式,
Lucene
就能为你的文档建立索引。比如,如果你想为
HTML
文档或者
PDF
文档建立索引,那么首先你就需要从这些文档中提取出文本信息,然后把文本信息交给
Lucene
建立索引。我们接下来的例子用来演示如何利用
Lucene
为后缀名为
txt
的文件建立索引。
1
.
准备文本文件
首先把一些以
txt
为后缀名的文本文件放到一个目录中,比如在
Windows
平台上,你可以放到
C://files_to_index
下面。
2
.
创建索引
清单
1
是为我们所准备的文档创建索引的代码。
package lucene.index; import java.io.File; import java.io.FileReader; import java.io.Reader; import java.util.Date; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import org.apache.lucene.index.IndexWriter; /** * This class demonstrates the process of creating an index with Lucene * for text files in a directory. */ public class TextFileIndexer { public static void main(String[] args) throws Exception{ //fileDir is the directory that contains the text files to be indexed File fileDir = new File("C://files_to_index "); //indexDir is the directory that hosts Lucene's index files File indexDir = new File("C://luceneIndex"); Analyzer luceneAnalyzer = new StandardAnalyzer(); IndexWriter indexWriter = new IndexWriter(indexDir,luceneAnalyzer,true); File[] textFiles = fileDir.listFiles(); long startTime = new Date().getTime(); //Add documents to the index for(int i = 0; i < textFiles.length; i++){ if(textFiles[i].isFile() >> textFiles[i].getName().endsWith(".txt")){ System.out.println("File " + textFiles[i].getCanonicalPath() + " is being indexed"); Reader textReader = new FileReader(textFiles[i]); Document document = new Document(); document.add(Field.Text("content",textReader)); document.add(Field.Text("path",textFiles[i].getPath())); indexWriter.addDocument(document); } } indexWriter.optimize(); indexWriter.close(); long endTime = new Date().getTime(); System.out.println("It took " + (endTime - startTime) + " milliseconds to create an index for the files in the directory " + fileDir.getPath()); } } |
正如清单
1
所示,你可以利用
Lucene
非常方便的为文档创建索引。接下来我们分析一下清单
1
中的比较关键的代码,我们先从下面的一条语句开始看起。
Analyzer luceneAnalyzer = new StandardAnalyzer(); |
这条语句创建了类
StandardAnalyzer
的一个实例,这个类是用来从文本中提取出索引项的。它只是抽象类
Analyzer
的其中一个实现。
Analyzer
也有一些其它的子类,比如
SimpleAnalyzer
等。
我们接着看另外一条语句:
IndexWriter indexWriter = new IndexWriter(indexDir,luceneAnalyzer,true); |
这条语句创建了类
IndexWriter
的一个实例,该类也是
Lucene
索引机制里面的一个关键类。这个类能创建一个新的索引或者打开一个已存在的索引并为该所引添加文档。我们注意到该类的构造函数接受三个参数,第一个参数指定了存储索引文件的路径。第二个参数指定了在索引过程中使用什么样的分词器。最后一个参数是个布尔变量,如果值为真,那么就表示要创建一个新的索引,如果值为假,就表示打开一个已经存在的索引。
接下来的代码演示了如何添加一个文档到索引文件中。
Document document = new Document(); document.add(Field.Text("content",textReader)); document.add(Field.Text("path",textFiles[i].getPath())); indexWriter.addDocument(document); |
首先第一行创建了类
Document
的一个实例,它由一个或者多个的域
(Field)
组成。你可以把这个类想象成代表了一个实际的文档,比如一个
HTML
页面,一个
PDF
文档,或者一个文本文件。而类
Document
中的域一般就是实际文档的一些属性。比如对于一个
HTML
页面,它的域可能包括标题,内容,
URL
等。我们可以用不同类型的
Field
来控制文档的哪些内容应该索引,哪些内容应该存储。如果想获取更多的关于
Lucene
的域的信息,可以参考
Lucene
的帮助文档。代码的第二行和第三行为文档添加了两个域,每个域包含两个属性,分别是域的名字和域的内容。在我们的例子中两个域的名字分别是
"content"
和
"path"
。分别存储了我们需要索引的文本文件的内容和路径。最后一行把准备好的文档添加到了索引当中。
当我们把文档添加到索引中后,不要忘记关闭索引,这样才保证
Lucene
把添加的文档写回到硬盘上。下面的一句代码演示了如何关闭索引。
indexWriter.close(); |
利用清单
1
中的代码,你就可以成功的将文本文档添加到索引中去。接下来我们看看对索引进行的另外一种重要的操作,从索引中删除文档。
 
|

|
类
IndexReader
负责从一个已经存在的索引中删除文档,如清单
2
所示。
File indexDir = new File("C://luceneIndex"); IndexReader ir = IndexReader.open(indexDir); ir.delete(1); ir.delete(new Term("path","C://file_to_index/lucene.txt")); ir.close(); |
在清单
2
中,第二行用静态方法
IndexReader.open(indexDir)
初始化了类
IndexReader
的一个实例,这个方法的参数指定了索引的存储路径。类
IndexReader
提供了两种方法去删除一个文档,如程序中的第三行和第四行所示。第三行利用文档的编号来删除文档。每个文档都有一个系统自动生成的编号。第四行删除了路径为
"C://file_to_index/lucene.txt"
的文档。你可以通过指定文件路径来方便的删除一个文档。值得注意的是虽然利用上述代码删除文档使得该文档不能被检索到,但是并没有物理上删除该文档。
Lucene
只是通过一个后缀名为
.delete
的文件来标记哪些文档已经被删除。既然没有物理上删除,我们可以方便的把这些标记为删除的文档恢复过来,如清单
3
所示,首先打开一个索引,然后调用方法
ir.undeleteAll()
来完成恢复工作。
File indexDir = new File("C://luceneIndex"); IndexReader ir = IndexReader.open(indexDir); ir.undeleteAll(); ir.close(); |
你现在也许想知道如何物理上删除索引中的文档,方法也非常简单。清单
4
演示了这个过程。
File indexDir = new File("C://luceneIndex"); Analyzer luceneAnalyzer = new StandardAnalyzer(); IndexWriter indexWriter = new IndexWriter(indexDir,luceneAnalyzer,false); indexWriter.optimize(); indexWriter.close(); |
在清单
4
中,第三行创建了类
IndexWriter
的一个实例,并且打开了一个已经存在的索引。第
4
行对索引进行清理,清理过程中将把所有标记为删除的文档物理删除。
Lucene
没有直接提供方法对文档进行更新,如果你需要更新一个文档,那么你首先需要把这个文档从索引中删除,然后把新版本的文档加入到索引中去。
 
|

|
利用
Lucene
,在创建索引的工程中你可以充分利用机器的硬件资源来提高索引的效率。当你需要索引大量的文件时,你会注意到索引过程的瓶颈是在往磁盘上写索引文件的过程中。为了解决这个问题
, Lucene
在内存中持有一块缓冲区。但我们如何控制
Lucene
的缓冲区呢?幸运的是,
Lucene
的类
IndexWriter
提供了三个参数用来调整缓冲区的大小以及往磁盘上写索引文件的频率。
1
.合并因子(
mergeFactor
)
这个参数决定了在
Lucene
的一个索引块中可以存放多少文档以及把磁盘上的索引块合并成一个大的索引块的频率。比如,如果合并因子的值是
10
,那么当内存中的文档数达到
10
的时候所有的文档都必须写到磁盘上的一个新的索引块中。并且,如果磁盘上的索引块的隔数达到
10
的话,这
10
个索引块会被合并成一个新的索引块。这个参数的默认值是
10
,如果需要索引的文档数非常多的话这个值将是非常不合适的。对批处理的索引来讲,为这个参数赋一个比较大的值会得到比较好的索引效果。
2
.最小合并文档数
这个参数也会影响索引的性能。它决定了内存中的文档数至少达到多少才能将它们写回磁盘。这个参数的默认值是
10
,如果你有足够的内存,那么将这个值尽量设的比较大一些将会显著的提高索引性能。
3
.最大合并文档数
这个参数决定了一个索引块中的最大的文档数。它的默认值是
Integer.MAX_VALUE
,将这个参数设置为比较大的值可以提高索引效率和检索速度,由于该参数的默认值是整型的最大值,所以我们一般不需要改动这个参数。
清单
5
列出了这个三个参数用法,清单
5
和清单
1
非常相似,除了清单
5
中会设置刚才提到的三个参数。
/** * This class demonstrates how to improve the indexing performance * by adjusting the parameters provided by IndexWriter. */ public class AdvancedTextFileIndexer { public static void main(String[] args) throws Exception{ //fileDir is the directory that contains the text files to be indexed File fileDir = new File("C://files_to_index"); //indexDir is the directory that hosts Lucene's index files File indexDir = new File("C://luceneIndex"); Analyzer luceneAnalyzer = new StandardAnalyzer(); File[] textFiles = fileDir.listFiles(); long startTime = new Date().getTime(); int mergeFactor = 10; int minMergeDocs = 10; int maxMergeDocs = Integer.MAX_VALUE; IndexWriter indexWriter = new IndexWriter(indexDir,luceneAnalyzer,true); indexWriter.mergeFactor = mergeFactor; indexWriter.minMergeDocs = minMergeDocs; indexWriter.maxMergeDocs = maxMergeDocs; //Add documents to the index for(int i = 0; i < textFiles.length; i++){ if(textFiles[i].isFile() >> textFiles[i].getName().endsWith(".txt")){ Reader textReader = new FileReader(textFiles[i]); Document document = new Document(); document.add(Field.Text("content",textReader)); document.add(Field.Keyword("path",textFiles[i].getPath())); indexWriter.addDocument(document); } } indexWriter.optimize(); indexWriter.close(); long endTime = new Date().getTime(); System.out.println("MergeFactor: " + indexWriter.mergeFactor); System.out.println("MinMergeDocs: " + indexWriter.minMergeDocs); System.out.println("MaxMergeDocs: " + indexWriter.maxMergeDocs); System.out.println("Document number: " + textFiles.length); System.out.println("Time consumed: " + (endTime - startTime) + " milliseconds"); } } |
通过这个例子,我们注意到在调整缓冲区的大小以及写磁盘的频率上面
Lucene
给我们提供了非常大的灵活性。现在我们来看一下代码中的关键语句。如下的代码首先创建了类
IndexWriter
的一个实例,然后对它的三个参数进行赋值。
int mergeFactor = 10; int minMergeDocs = 10; int maxMergeDocs = Integer.MAX_VALUE; IndexWriter indexWriter = new IndexWriter(indexDir,luceneAnalyzer,true); indexWriter.mergeFactor = mergeFactor; indexWriter.minMergeDocs = minMergeDocs; indexWriter.maxMergeDocs = maxMergeDocs; |
下面我们来看一下这三个参数取不同的值对索引时间的影响,注意参数值的不同和索引之间的关系。我们为这个实验准备了
10000
个测试文档。表
1
显示了测试结果。
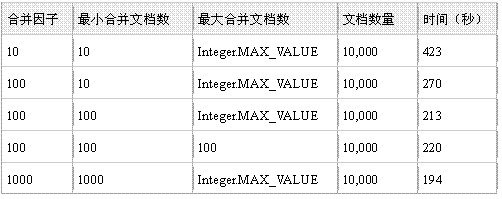
通过表
1
,你可以清楚地看到三个参数对索引时间的影响。在实践中,你会经常的改变合并因子和最小合并文档数的值来提高索引性能。只要你有足够大的内存,你可以为合并因子和最小合并文档数这两个参数赋尽量大的值以提高索引效率,另外我们一般无需更改最大合并文档数这个参数的值,因为系统已经默认将它设置成了最大。
|
|
|
本文定义了Lucene(版本1.3)用到的索引文件的格式。 Jakarta Lucene是用Java写成的,同时有很多团体正在默默的用其他的程序语言来改写它。如果这些新的版本想和Jakarta Lucene兼容,就需要一个与具体语言无关的Lucene索引文件格式。本文正是试图提供一个完整的与语言无关的Jakarta Lucene 1.3索引文件格式的规格定义。 随着Lucene不断发展,本文也应该更新。不同语言写成的Lucene实现版本应当尽力遵守文件格式,也必须产生本文的新版本。 本文同时提供兼容性批注,描述文件格式上与前一版本不同的地方。 定义 Lucene中最基础的概念是索引(index),文档(document.,域(field)和项(term)。 索引包含了一个文档的序列。 · 文档是一些域的序列。 · 域是一些项的序列。 · 项就是一个字串。 存在于不同域中的同一个字串被认为是不同的项。因此项实际是用一对字串表示的,第一个字串是域名,第二个是域中的字串。 倒排索引 为了使得基于项的搜索更有效率,索引中项是静态存储的。Lucene的索引属于索引方式中的倒排索引,因为对于一个项这种索引可以列出包含它的文档。这刚好是文档与项自然联系的倒置。
bitsCN.com
中国网管联盟
域的类型 Lucene中,域的文本可能以逐字的非倒排的方式存储在索引中。而倒排过的域称为被索引过了。域也可能同时被存储和被索引。 域的文本可能被分解许多项目而被索引,或者就被用作一个项目而被索引。大多数的域是被分解过的,但是有些时候某些标识符域被当做一个项目索引是很有用的。 段(Segment) Lucene索引可能由多个子索引组成,这些子索引成为段。每一段都是完整独立的索引,能被搜索。索引是这样作成的: 1. 为新加入的文档创建新段。 2. 合并已经存在的段。 搜索时需要涉及到多个段和/或者多个索引,每一个索引又可能由一些段组成。 文档号(document.nbspNumber) 内部的来说,Lucene用一个整形(interger)的文档号来指示文档。第一个被加入到索引中的文档就是0号,顺序加入的文档将得到一个由前一个号码递增而来的号码。 注意文档号是可能改变的,所以在Lucene外部存储这些号码时必须小心。特别的,号码的改变的情况如下: · 只有段内的号码是相同的,不同段之间不同,因而在一个比段广泛的上下文环境中使用这些号码时,就必须改变它们。标准的技术是根据每一段号码多少为每一段分配一个段号。将段内文档号转换到段外时,加上段号。将某段外的文档号转换到段内时,根据每段中可能的转换后号码范围来判断文档属于那一段,并减调这一段的段号。例如有两个含5个文档的段合并,那么第一段的段号就是0,第二段段号5。第二段中的第三个文档,在段外的号码就是8。 www.bitsCN.net网管博客等你来搏 · 文档删除后,连续的号码就出现了间断。这可以通过合并索引来解决,段合并时删除的文档相应也删掉了,新合并而成的段并没有号码间断。 绪论 索引段维护着以下的信息: · 域集合。包含了索引中用到的所有的域。 · 域值存储表。每一个文档都含有一个“属性-值”对的列表,属性即为域名。这个列表用来存储文档的一些附加信息,如标题,url或者访问数据库的一个ID。在搜索时存储域的集合可以被返回。这个表以文档号标识。 · 项字典。这个字典含有所有文档的所有域中使用过的的项,同时含有使用过它的文档的文档号,以及指向使用频数信息和位置信息的指针。 · 项频数信息。对于项字典中的每个项,这些信息包含含有这个项的文档的总数,以及每个文档中使用的次数。 · 项位置信息。对于项字典中的每个项,都存有在每个文档中出现的各个位置。 · Normalization factors. For each field in each document. a value is stored that is multiplied into the score for hits on that field. 标准化因子。对于文档中的每一个域,存有一个值,用来以后乘以这个这个域的命中数(hits)。
dl.bitsCN.com
网管软件下载
· 被删除的文档信息。这是一个可选文件,用来表明那些文档已经删除了。 接下来的各部分部分详细描述这些信息。 文件的命名(File Naming) 同属于一个段的文件拥有相同的文件名,不同的扩展名。扩展名由以下讨论的各种文件格式确定。 一般来说,一个索引存放一个目录,其所有段都存放在这个目录里,尽管我们不要求您这样做。 基本数据类型(Primitive Types) Byte 最基本的数据类型就是字节(byte,8位)。文件就是按字节顺序访问的。其它的一些数据类型也定义为字节的序列,文件的格式具有字节意义上的独立性。 UInt32 32位无符号整数,由四个字节组成,高位优先。 UInt32 --> 4 Uint64 64位无符号整数,由八字节组成,高位优先。 UInt64 --> 8 VInt 可变长的正整数类型,每字节的最高位表明还剩多少字节。每字节的低七位表明整数的值。因此单字节的值从0到127,两字节值从128到16,383,等等。 VInt 编码示例
feedom.net
国内最早的网管网站
value First byte Second byte Third byte 0 00000000 1 00000001 2 00000010 ... 127 01111111 128 10000000 00000001 129 10000001 00000001 130 10000010 00000001 ... 16,383 11111111 01111111 16,384 10000000 10000000 00000001 16,385 10000001 10000000 00000001 ... 这种编码提供了一种在高效率解码时压缩数据的方法。 Chars Lucene输出UNICODE字符序列,使用标准UTF-8编码。 String Lucene输出由VINT和字符串组成的字串,VINT表示字串长,字符串紧接其后。 String --> VInt, Chars 索引包含的文件(Per-Index Files) 这部分介绍每个索引包含的文件。
bitsCN_com
Segments文件 索引中活动的段存储在Segments文件中。每个索引只能含有一个这样的文件,名为"segments".这个文件依次列出每个段的名字和每个段的大小。 Segments --> SegCount, SegCount SegCount, SegSize --> UInt32 SegName --> String SegName表示该segment的名字,同时作为索引其他文件的前缀。 SegSize是段索引中含有的文档数。 Lock文件 有一些文件用来表示另一个进程在使用索引。 · 如果存在"commit.lock"文件,表示有进程在写"segments"文件和删除无用的段索引文件,或者表示有进程在读"segments"文件和打开某些段的文件。在一个进程在读取"segments"文件段信息后,还没来得及打开所有该段的文件前,这个Lock文件可以防止另一个进程删除这些文件。 · 如果存在"index.lock"文件,表示有进程在向索引中加入文档,或者是从索引中删除文档。这个文件防止很多文件同时修改一个索引。 Deleteable文件 名为"deletetable"的文件包含了索引不再使用的文件的名字,这些文件可能并没有被实际的删除。这种情况只存在与Win32平台下,因为Win32下文件仍打开时并不能删除。 bitsCN_net中国网管博客 Deleteable --> DelableCount, DelableCount DelableCount --> UInt32 DelableName --> String 段包含的文件(Per-Segment Files) 剩下的文件是每段中包含的文件,因此由后缀来区分。 域(Field) 域集合信息(Field Info) 所有域名都存储在这个文件的域集合信息中,这个文件以后缀.fnm结尾。 FieldInfos (.fnm) --> FieldsCount, FieldsCount FieldsCount --> VInt FieldName --> String FieldBits --> Byte 目前情况下,FieldBits只有使用低位,对于已索引的域值为1,对未索引的域值为0。 文件中的域根据它们的次序编号。因此域0是文件中的第一个域,域1是接下来的,等等。这个和文档号的编号方式相同。 域值存储表(Stored Fields) 域值存储表使用两个文件表示: 1. 域索引(.fdx文件)。 如下,对于每个文档这个文件包含指向域值的指针: FieldIndex (.fdx) --> SegSize
play.bitsCN.com
累了吗玩一下吧
FieldvaluesPosition --> Uint64 FieldvaluesPosition指示的是某一文档的某域的域值在域值文件中的位置。因为域值文件含有定 |














 2933
2933











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









