









本文为笔者原创,转载请注明出处http://blog.csdn.net/xinghongduo
mylex & xparser
mylex & xparser是笔者实现的类似于Lex和Yacc的词法语法分析器生成器,它接受正则表达式定义的词法规则和BNF定义的语法规则,自动构造对应的以C为宿主语言的词法分析器源程序mylex.h, mylex.c和语法分析器源程序xparser.h, xparser.c。
mylex & xparser特点如下:
轻量无依赖:构造器的主要代码仅2000行左右,并且生成的词法分析器mylex.c和语法分析器xparser.c包含的代码简单易懂,读懂后可以根据需要任意修改。
可重入:mylex & xparser生成的词法分析器和语法分析器只有词法DFA和LR分析表是公共的,并且分析过程中对于词法DFA和分析表都是只读的。语法分析的状态栈和语义值栈都保存在xparser_t结构内,每个线程的语法分析在自己的xparser_t中完成,互不影响。
支持二义性文法:编写文法时可以指定每个token的优先级和结合性,xparser会尝试利用定义的优先级与结合性解决项目集中的冲突,如果冲突不能根据优先级和结合性解决,则xparser会给出警告并输出冲突项目集的具体信息,对于移进--归约冲突,xparser将默认进行移进动作,对于归约--归约冲突则默认由先定义的产生式归约。
支持语法制导翻译:每个产生式后可以编写一段语义子程序,xparser在以此产生式归约时会执行这段子程序,xparser以$符号操纵语义值栈,$$表示归约后的语义值栈栈顶,$k表示对第k个待归约符号的引用,与Yacc相似,语义值栈可以为自定义类型,在初始化xparser时需要传递两个函数指针malloc_func和free_func,这两个函数用于对语义值栈元素的申请和释放,如果语义值栈元素不需要动态申请和释放则传两个空函数指针即可。
较高的构造速度:在i5-3.2G处理器,VS2005 Release模式下可以在1秒内构造出分析C99标准C的词法分析器和语法分析器。
构造较高性能的分析器:笔者使用该工具和mysql文法构造出了SQL分析器,对该分析器进行性能测试,在相同环境下单线程对select * from (s inner join c on s.a > c.b) where d.a > (select s.b from s where s.a = 10);每秒可以进行100w次词法分析,30w次词法和语法分析。
mylex & xparser用法示例:
示例一:构造表达式计算器
表达式计算是数据结构的经典题目之一,计算机相关专业的同学肯定都搞过,标准的做法是先转化为后缀表达式,然后利用栈计算后缀表达式的值。笔者曾经为了快速实现直接用了一遍扫描+递归,也就是递归下降法,写完各种debug,编程加调试花了几个小时才搞定。现在利用mylex & xparser,我们可以异常简单的实现它。
以下是笔者编写的表达式计算的词法和文法,该文法是二义性文法,文法中定义的优先级和结合性消除了二义性。词法和语法规则需要定义在同一个文件中。
%TOKEN{
"num" KW_NUMBER "[0-9]+"
"+" KW_PLUS "\+"
"-" KW_SUB "\-"
"*" KW_MUL "\*"
"/" KW_DIV "/"
"^" KW_POW "\^"
"(" KW_LEFT "\("
")" KW_RIGHT "\)"
}%
%GRAMMAR{
%left '+' '-'
%left '*' '/'
%token SIGN
%left '^'
S : E { $$ = $1; }
;
E : E '+' E { $$ = $1 + $3; }
| E '-' E { $$ = $1 - $3; }
| E '*' E { $$ = $1 * $3; }
| E '/' E { $$ = $1 / $3; }
| E '^' E { $$ = pow($1, $3); }
| '(' E ')' { $$ = $2; }
| '-' E %prec SIGN { $$ = -$2; }
| '+' E %prec SIGN { $$ = $2; }
| num { $$ = $1; }
;
}%
%TOKEN段中定义了词法规则,每行的词法规则通常分为三部分,每个部分以空格或制表符分隔,第一部分作为该token在BNF中的标识,第二部分为预定义宏,词法分析器在确认匹配了某个token后会将该token的预定义宏和匹配串传递给语法分析器,第三部分是token的正则表达式,如果只定义词法的正则表达式则mylex会将其作为格式过滤正则,匹配后不会传递给语法分析器,正则表达式部分也可以定义为NULL。后定义的token匹配优先级高于先定义的token,如果需要设置匹配大小写不敏感,则可以在%TOKEN段首定义%ignore_case。
%GRAMMAR段中定义了文法规则,该段开始是对于token优先级和结合性的声明,声明结合性的关键字与Yacc相同,如果没有优先级或结合性则此部分可以忽略,同行声明的token优先级相等,后面行的优先级高于之前的行。接下来是每个产生式的定义,产生式的定义形式与Yacc类似,如果产生式右部没有符号则表示该产生式推导为空。每个产生式后是归约时执行的语义子程序,也可以为空,如果子程序中出现语义错误则直接返回1即可。需要注意的是xparser会将第一个定义的产生式作为起始产生式,为使接受状态唯一,起始产生式左部符号不能与其他产生式相同,并且右部只有一个符号,本例中产生式S : E;就是基于此目的增加的。
将%TOKEN段和%GRAMMAR段保存在文件cal.g中,相对位置随意,mylex会首先定位到%TOKEN段并分析词法定义,然后定位到%GRAMMAR段读取每个产生式。运行程序并输入文件所在路径。

mylex & xparser已经成功生成了分析cal.g中定义规则的词法分析器和语法分析器的C源程序,分别对应文件mylex.h mylex.c和xparser.h xparser.c。
在使用生成的词法分析器和语法分析器前,需要调用词法分析器的初始化函数my_lex_build()和语法分析器的初始化函数xparser_build()。my_lex_build()函数内将根据数组dfa_node_info和dfa_graph重建识别所有token的DFA,xparser_build()函数内会根据数组lalr_action_list和lalr_goto_list重建LR分析表,程序生存周期内这两个函数只需要调用一次即可,并且DFA和LR分析表建立后都是只读的。
语法分析器xparser是由词法分析器mylex驱动的,mylex确认匹配一个token后会立即调用xparser进行语法分析。词法分析的函数是my_lex_match(my_lex_run_t *run, my_lex_input_t *input, xparser*),该函数参数作用如下:
my_lex_run_t:保存词法分析器匹配的串和状态。
my_lex_input_t:词法分析器为实现最长匹配原则会频繁回退输入流字符,因此笔者将输入流进行了简单的封装,并加入了简单的缓存机制来减少文件指针的移动,该结构通过my_lex_input_init(my_lex_input_t*,short,void*)函数初始化,第二个参数用于指定输入类型,可以是文件输入MY_LEX_FILE_INPUT或字符串输入MY_LEX_STR_INPUT,第三个参数是文件指针FILE*或字符指针char*,具体由输入类型决定。
xparser_t:语法分析器结构,由mylex驱动以进行语法分析,该结构中包含了状态栈和语义值栈,多线程下每个线程在自己的xparser_t中进行语法分析,因此是线程安全的。xparser_t由xparser_init(xparser*, XPARSER_MALLOC, XPARSER_FREE)函数初始化,后两个参数是函数指针,分别用于申请和释放一个语义值栈元素,如果语义值栈元素不需要动态申请释放则都传NULL即可。xparser.h中宏XPARSER_STACK_TYPE用于指定语义值栈元素类型,默认为int型,如需要自定义类型则需要修改该宏。
//mylex & xparser使用示例
#include “mylex.h”
#include “xparser.h”
int main(int argc, char *argv[])
{
char *exp = "2--2*((2^3-2)/+2)^2";
my_lex_run_t run;
my_lex_input_t in;
xparser par;
my_lex_build(); //词法分析器建立DFA
xparser_build(); //语法分析器建立分析表
my_lex_run_init(&run);
xparser_init(&par, NULL, NULL);
my_lex_input_init(&in, MY_LEX_STR_INPUT, exp);
my_lex_match(&run, &in, &par);
return 0;
}如果使用语法制导翻译,则还需要修改xparser.c中的xparser_shift_value_set(xparser *parser, XPARSER_STACK_TYPE *value, token_t *tok)函数,xparser执行移进动作时会调用该函数设置移进符号的语义值,所以需要根据tok_id结合token的预定义宏设置不同的语义值即可。笔者已经在cal.g中对每个产生式编写了语义动作,该示例中只有KW_NUMBER需要语义值,因此函数修改如下:
void xparser_shift_value_set(xparser *parser, XPARSER_STACK_TYPE *value, token_t *tok)
{
if(KW_NUMBER == tok->tok_id) {
*value = atoi(tok->tok_str);
}
}
xparser在语法分析最终完成后会调用xparser.c中的xparser_parse_finish(xparser *parser, XPARSER_STACK_TYPE value)函数传递最终的语义值,该示例的最终语义值是表达式的值,我们直接输出就好了,而对于其他较为复杂的分析,经过语法制导翻译后最终返回的语义值可能是一颗抽象语法树,因此需要在该函数内进行后续的语义分析。
void xparser_parse_finish(xparser *parser, XPARSER_STACK_TYPE value)
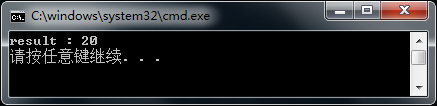
{
printf("result : %d\n", value);
}
注意语义动作中计算幂值使用了数学库的pow函数,因此需要手动在xparser.c中包含math.h,笔者在VS2005下不包含该头文件也可以编译通过,但pow有时返回的结果是错误的,可能是链接的pow不是C标准库的实现,所以为得到正确的结果必须包含math.h。完成上述所有修改后即可编译,运行得到表达式2--2*((2^3-2)/+2)^2的值。
本示例中的文法只是基本的表达式文法,你可以在其基础上增加文法规则来增强计算器的功能,例如支持各种函数变量等也是非常容易的。表达式计算的文法还是太简单了,下面我们尝试构造一个JSON解析器。
示例二:构造JSON解析器
JSON是一种轻量的数据传输格式,它具有传输效率高,语法简单易懂的优点,它也是当前应用最广的数据传输格式之一。实际项目中我们往往是通过第三方库来进行JSON的序列化和反序列化。实现序列化为JSON的过程比较容易,其原理就是深度优先遍历数据结构拼接字符串,而对于实现反序列化,由于JSON的语法规则很少,递归下降写起来也是很容易的,很多第三方库就是基于递归下降的方法。下面我们来使用mylex & xparser构造一个JSON解析器,为脱离语言限制,该工具将解析的JSON串转化为中间语法树,根据语法树可以很容易的转化为目标语言的结构,语法树结点定义如下。
typedef struct tree_node_t {
enum {
MAP_NODE,
ARRAY_NODE,
VALUE_NODE_NULL,
VALUE_NODE_TRUE,
VALUE_NODE_FALSE,
VALUE_NODE_STRING,
VALUE_NODE_INT,
VALUE_NODE_DOUBLE,
VALUE_NODE_KEYVALUE
}ntype;
void *key;
void *value;
struct tree_node_t *data_head;
struct tree_node_t *data_rear;
struct tree_node_t *next;
}tree_node;
JSON串{“key1”:[“value1”,{“key2”:1}],“key3”:3.14}将被转化为如下中间语法树结构:
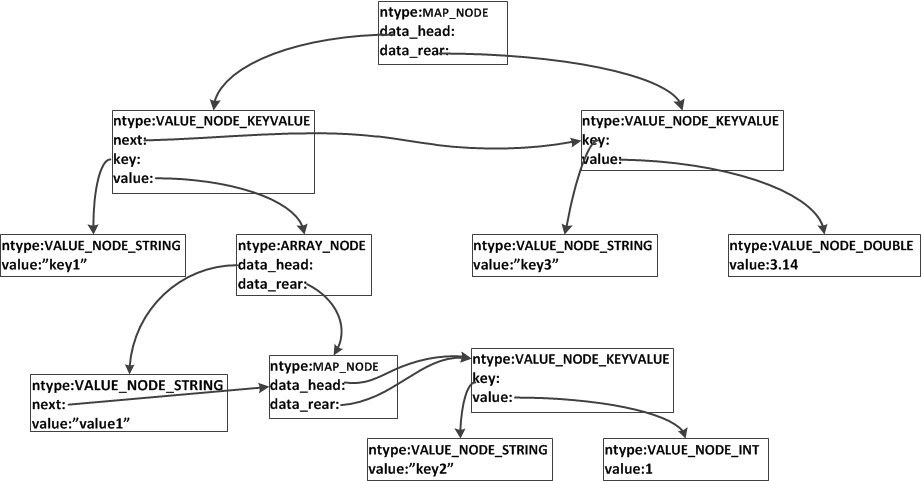
JSON标准Lex & Yacc词法文法
http://codereview.stackexchange.com/questions/7536/yet-another-c-json-parser
将该Lex & Yacc文法转化为mylex & xparser输入保存为文件json.g,运行程序输入文件路径,生成mylex.h,mylex.c和xparser.h,xparser.c。
笔者在json.g中已经对每个产生式编写了语义动作,为使语法制导翻译正常工作,我们还需要设置移进符号的语义值,生成的xparser.c中xparser_shift_value_set函数修改如下。
void xparser_shift_value_set(xparser *parser, XPARSER_STACK_TYPE *value, token_t *tok)
{
switch(tok->tok_id) {
case KW_TRUE:
*value = (tree_node*)mem_alloc(sizeof(tree_node));
(*value)->ntype = VALUE_NODE_TRUE;
break;
case KW_FALSE:
*value = (tree_node*)mem_alloc(sizeof(tree_node));
(*value)->ntype = VALUE_NODE_FALSE;
break;
case KW_NULL:
*value = (tree_node*)mem_alloc(sizeof(tree_node));
(*value)->ntype = VALUE_NODE_NULL;
break;
case KW_STRING:
*value = (tree_node*)mem_alloc(sizeof(tree_node));
(*value)->ntype = VALUE_NODE_STRING;
(*value)->value = mem_alloc(tok->tok_len+1);
memcpy((*value)->value, tok->tok_str, tok->tok_len+1);
break;
case KW_NUMBER:
*value = (tree_node*)mem_alloc(sizeof(tree_node));
(*value)->ntype = VALUE_NODE_INT;
(*value)->value = mem_alloc(4);
*(int*)((*value)->value) = atoi(tok->tok_str);
break;
}
}xparser.h中需要声明tree_node_t或引用声明文件,并且修改语义值栈元素类型宏XPARSER_STACK_TYPE为#define XPARSER_STACK_TYPE tree_node*,完成上述修改后JSON反序列化工具就构造完毕了。
如果想构造指定语言的JSON反序列化工具,可以使map和array分别继承于相应的数组类和字典类并重写函数将中间语法树结构转化到目标结构。例如对于ObjC我们可以使array和map结构分别继承于NSArray和NSDictionary,我们只要重写这两个类的一些操作函数将中间语法树转化为NSArray或NSDictionary就能实现一个基本的ObjC的JSON反序列化工具。
为避免频繁动态申请内存影响性能,笔者实现了一个简易的内存池,所有内存申请都调用mem_alloc函数在内存池内分配内存。笔者对该工具进行性能测试,并与目前iOS平台性能最高的两个JSON解析库JSONKit和NSJSONSerialization比较,对4个JSON文本循环解析100次的耗时如下,单位ms。
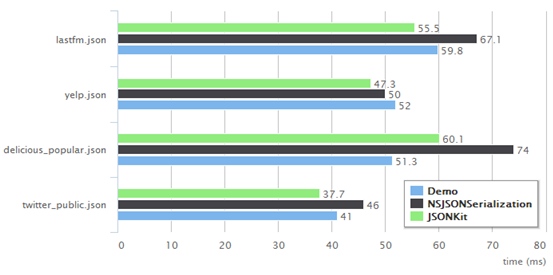
从测试结果来看,我们构造的解析器Demo与速度最快的JSONKit性能是比较接近的,JSONKit使用递归下降法实现对JSON的解析,并且解析过程中加入了各种优化策略。我们的Demo和JSONKit都是将JSON转化为中间结构,而NSJSONSerialization是直接转化为目标结构的,由于不了解NSAarray和NSDictionary的内存布局,因此如果我们要直接生成目标结构只能通过官方提供的函数,性能比较低,而NSJSONSerialization是苹果官方自己实现的库,其内部应该会有一套快速构造NSArray和NSDictionary的方法,才保证了直接生成目标结构的前提下还能保持着很高的性能,如果你了解NSArray或NSDictionary的内部实现,还请做一个技术分享,非常感谢。
JSON的文法还是比较简单,前两个例子只是作为入门示例,设计这个工具目的是为构造各种语言编译器的前端,下面的示例中我们将尝试构造C编译器前端。
示例三:构造C编译器前端
C语言是上世纪70年代初诞生于贝尔实验室的一门面向过程的程序设计语言,其设计者是丹尼斯里奇(Dennis Ritchie)和肯汤普森(Ken Thompson),它最初被用来编写Unix操作系统。
C语言灵活高效,既具备高级语言的特点又提供了直接操作硬件的能力,并且具有良好的可移植性。很多系统软件的核心都是用C语言实现的。
C到目前为止共制订了四个标准,分别是C89,C90,C99,C11。C89是ANSI对丹尼斯里奇和肯汤普森C的标准化版本,也是最初的C标准,目前我们写的C程序多数是基于C89标准的,同时该标准也是被各种C编译器支持最为广泛的版本。C99在C89的基础上加入了一些关键字,增加了几个基本数据类型,支持定义不定长数组,变量可以不定义在函数首部等特性,而编译器厂商对C99标准似乎不太关注,GCC仅是部分支持C99,VC则是完全不支持,完全支持C99的编译器目前还没有。C11是2011年末发布的C标准版本,该标准增加了对静态断言,边界检查,多线程等的支持,目前编译器对C11的支持更是非常有限。
构造C编译器前端前我们先需要获得C的词法和文法规则,如果要求不高只是想实现精简版的C语法那么还是可以自己写词法文法定义的,但如果想实现标准C那么就不要自己写了,一方面C中的运算符优先级规则很多自己写容易出错,另一方面也不能保证对C有完全的了解。因此我们直接用官方给出的词法文法定义即可,下面我们使用的是C99标准文法。
C99标准Lex & Yacc词法文法
http://www.quut.com/c/ANSI-C-grammar-l-1999.html
http://www.quut.com/c/ANSI-C-grammar-y-1999.html
将C99的Lex & Yacc文件改写为mylex & xparser的输入保存文件为c99c.g,笔者额外添加了一个容错产生式statement : error ‘;’,运行程序输入文件路径。

该文法是存在二义性的,xparser输出了冲突项目集的信息,编号为377项目集中待归约项目selection_statement : IF ( expression ) statement·与待移进项目selection_statement : IF ( expression ) statement·ELSE statement存在关于符号ELSE的移进-规约冲突,该冲突导致对于如下输入存在两种推导。
if(i>1) if(i>2) printf(“1”); else printf(“0”);

推导一对应语义
if(i>1) {
if(i>2) printf(“2”);
} else {
printf(“1”);
}
推导二对应语义
if(i>1) {
if(i>2) printf(“2”);
else printf(“1”);
}
C语言规定else应该与同语句块内之前最近的if匹配,显然推导二的语义才是正确的,因此对于该项目集面临符号ELSE的冲突,正确动作是移进,这也是xparser解决无优先级冲突的默认策略,如果你想强制指定某个无优先级的移进-归约冲突采用归约动作,则可以将归约产生式的优先级或该产生式内终结符的优先级定义为高于移进符号的优先级即可。本文附件的Demo中有笔者以此C99标准文法改写的无二义性文法,消除了IF-ELSE的二义性,如有需要可以使用。
经过上面的操作我们得到了C99的词法语法分析器,笔者写了一段C代码来测试这个分析器,完整的测试代码保存在附件中a.c文件中,这段程序尽量涵盖了C的大部分语法,注意源程序中不能包含预编译命令,例如#include,#define,#ifdef,宏__FILE__,__LINE__等,源程序输入流到达词法分析器前会经过预处理器,预编译命令会被预处理器展开或替换,对于词法分析器来说这些符号都是不可见的,字符串的折行,拼接也是由预处理器完成。
%TOKEN段中定义了一个特殊的符号TYPE_NAME,该token表示类型名,而实际中类型名是通过查找符号表来确定的,词法分析器在匹配了标识符后需要查找符号表,如果是类型名则报告匹配了TYPE_NAME,否则报告匹配IDENTIFIER。由于我们只是实现C编译器的前端,并没有实现符号表的逻辑,因此笔者将该token的正则表达式定义为"type_name",实际构造编译器TYPE_NAME的正则需要定义为NULL,测试程序中所有自定义数据类型都用type_name声明或定义。
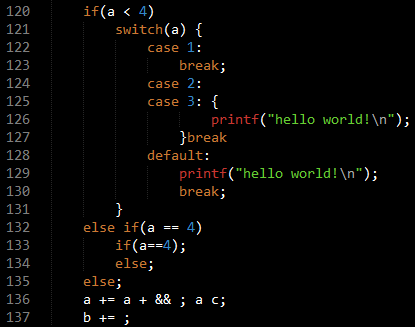
上图是测试程序a.c中的代码片段,代码中故意写了几处语法错误,127行少了;号,136和137行表达式都是错误的。由于笔者只添加了一条容错产生式statement : error ‘;’,只有是statement向下推导过程中出现的错误分析器才能从错误中恢复过来,因此这几个错误都是针对statement的子句而添加的。
我们用生成的分析器对a.c进行语法分析,分析器准确指出了所有语法错误,输出的提示如下。
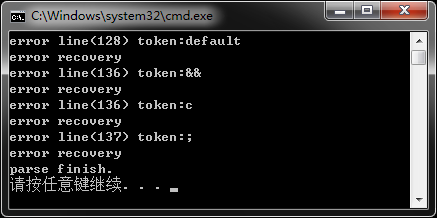
本示例只是构造了编译器前端而没有生成中间语法树,感兴趣的话也可以对标准文法的每个产生式加入语义动作来生成中间语法树,不过由于C文法规则很多这个过程会是漫长而艰辛的,一旦生成了语法树如果再对汇编有一定了解就可以写出初步可用的编译器了,写一个可用的编译器并不是很难的事,编译器的难点在于代码优化部分,写出具有强大优化能力的商业级编译器还是非常困难的。
目前绝大多数程序设计语言都可以用LALR(1)文法描述,如果想构造某个语言的分析器我们只需要找到它的标准文法,然后利用该构造工具自动生成即可,需要提一下的是C++是一个例外,它的文法是上下文有关的,LR分析只能用于上下文无关文法。
结束语
编译器前端构造理论的研究起始于上世纪60年代,经过几十年的发展如今这些理论已经非常成熟,本文就是笔者结合个人理解对这些经典理论的阐述,为深入揭示这些理论笔者还实现了一个类似Lex & Yacc的工具,文中讲解的所有理论都可以在源码中找到实现细节,如果理解了这些原理你完全可以用任何语言实现它。这个工具可以应用的领域是非常广泛的,如果你想实现一个编译器,或者设计一门语言,脚本语言解释器,复杂配置文件解析,参数检查过滤,防SQL注入等涉及词法语法分析的领域都可以派上用场。
编写这个工具的初衷是为了更好的揭示文中的相关理论,同时也是just for fun,因精力有限,笔者只是实现了Lex & Yacc的核心功能,而没有在意一些细节,例如词法分析器匹配动作的自定义,语义值栈元素类型的指定,头文件的包含等在Lex & Yacc中都可以在定义词法文法时指定而不必修改生成的文件,而xparser需要程序员手动在生成文件中引用文件和自定义类型。如果文法都以左递归的形式表示,则分析时存在一个栈最大长度,对于分析任意长的输入,栈中的状态数也不会超过这个值,Yacc中实现了该上限的计算,而xparser只是简单的指定了一个最大栈长度。笔者会在业余时间改进并完善它,最后希望这篇文章能够对你有所帮助。
分析器和示例程序下载地址:http://download.csdn.net/detail/xinghongduo/7971387
参考资料:
1. Alfred V.Aho, Ravi Sethi, Jeffrey D.Ullman, 李建中等译. Compilers Principles Techniques and Tools.机械工业出版社
2. 张素琴, 吕映芝,蒋维杜.编译原理第二版.清华大学出版社
3. John R.Levine, Tony Mason, Doug Brown, 杨作梅等译. Lex与Yacc第二版.机械工业出版社














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









