







 本文详细介绍了Ceph分布式存储系统的工作原理,包括MON监视器、OSD对象存储设备、PG放置组和MDS元数据设备的角色。此外,还探讨了Ceph在OpenStack中的应用,以及Ceph的快照、克隆功能和块设备的使用。同时,文章提到了Ceph的源代码结构和benchmark测试,以及监控工具如Inkscope和Calamari的使用。
本文详细介绍了Ceph分布式存储系统的工作原理,包括MON监视器、OSD对象存储设备、PG放置组和MDS元数据设备的角色。此外,还探讨了Ceph在OpenStack中的应用,以及Ceph的快照、克隆功能和块设备的使用。同时,文章提到了Ceph的源代码结构和benchmark测试,以及监控工具如Inkscope和Calamari的使用。
ceph系统原理 细节 benchmark 不完全说明
转载请说明出处:
http://blog.csdn.net/XingKong_678/article/details/51473988
1 流程说明
1.1 应用
1) RADOS GW是一个提供与Amazon S3和Swift兼容的RESTful API的gateway,以供相应的对象存储应用开发使用。RADOS GW提供的API抽象层次更高,但功能则不如librados强大。因此,开发者应针对自己的需求选择使用.
2) RBD则提供了一个标准的块设备接口,常用于在虚拟化的场景下为虚拟机创建volume。目前,Red Hat已经将RBD驱动集成在KVM/QEMU中,以提高虚拟机访问性能。
3) Ceph FS是一个POSIX兼容的分布式文件系统。由于还处在开发状态,因而Ceph官网并不推荐将其用于生产环境中。
1.1.1 问题说明
RADOS自身既然已经是一个对象存储系统,并且也可以提供librados API,为何还要再单独开发一个RADOS GW?
理解这个问题,事实上有助于理解RADOS的本质,因此有必要在此加以分析。粗看起来,librados和RADOS GW的区别在于,librados提供的是本地API,而RADOS GW提供的则是RESTful API,二者的编程模型和实际性能不同。而更进一步说,则和这两个不同抽象层次的目标应用场景差异有关。换言之,虽然RADOS和S3、Swift同属分 布式对象存储系统,但RADOS提供的功能更为基础、也更为丰富。这一点可以通过对比看出。由于Swift和S3支持的API功能近似,这里以Swift举例说明。Swift提供的API功能主要包括:
用户管理操作:用户认证、获取账户信息、列出容器列表等;
容器管理操作:创建/删除容器、读取容器信息、列出容器内对象列表等;
对象管理操作:对象的写入、读取、复制、更新、删除、访问许可设置、元数据读取或更新等。
由 此可见,Swift(以及S3)提供的API所操作的“对象”只有三个:用户账户、用户存储数据对象的容器、数据对象。并且,所有的操作均不涉及存储系统 的底层硬件或系统信息。不难看出,这样的API设计完全是针对对象存储应用开发者和对象存储应用用户的,并且假定其开发者和用户关心的内容更偏重于账户和 数据的管理,而对底层存储系统细节不感兴趣,更不关心效率、性能等方面的深入优化。而 librados API的设计思想则与此完全不同。一方面,librados中没有账户、容器这样的高层概念;另一方面,librados API向开发者开放了大量的RADOS状态信息与配置参数,允许开发者对RADOS系统以及其中存储的对象的状态进行观察,并强有力地对系统存储策略进行 控制。换言之,通过调用librados API,应用不仅能够实现对数据对象的操作,还能够实现对RADOS系统的管理和配置。这对于S3和Swift的RESTful API设计是不可想像的,也是没有必要的。
1.2 ceph说明:
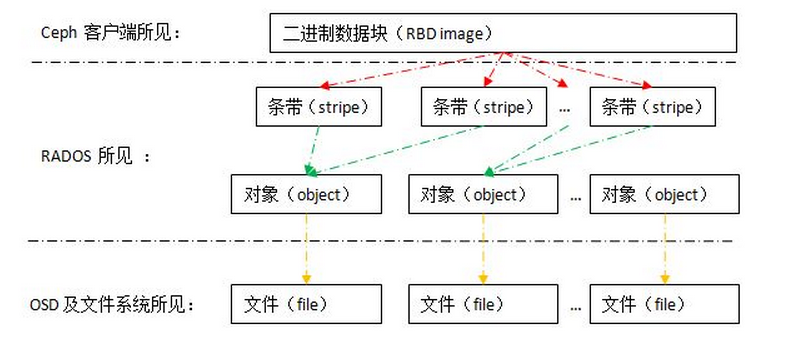
ceph Image 一般4M分成一块.作为对象存储在OSD上.
写入8M的数据产生了两个对象(对象的大小可以自己定义.)
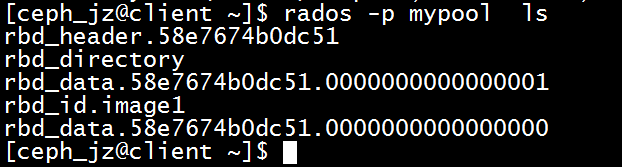
在存储中都是以对象4M形式存储在OSD上的。不论Image,卷还是其他的形式在OSD上只存储4M一个的对象.
块设备就像是相当于磁盘的存在.
在OSD上存储如下图所示.

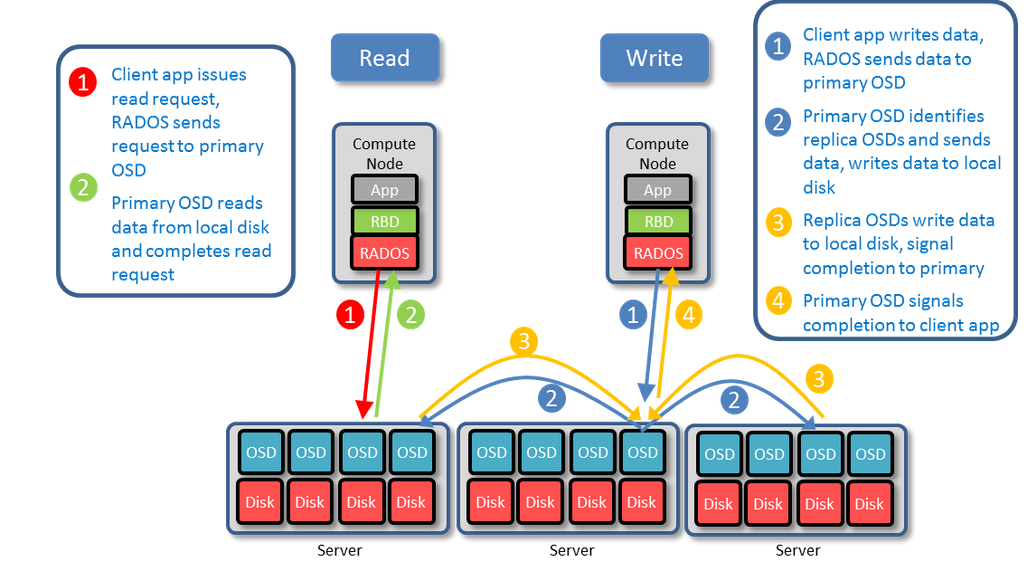
1.3 系统结构读写运行过程
1.3.1 MON(Montior)监视器
责通过维护 Ceph Cluster map 的一个主拷贝(master copy of Cluster map)来维护整 Ceph 集群的全局状态。理论上来讲,一个 MON 就可以完成这个任务,之所以需要一个多个守护进程组成的集群的原因是保证高可靠性。每个 Ceph node 上最多只能有一个 Monitor Daemon。
1.3.2 OSD对象存储设备
OSD (Object Storage Device)集群:OSD 集群由一定数目的(从几十个到几万个) OSD Daemon 组成,负责数据存储和复制,向 Ceph client 提供存储资源。每个 OSD 守护进程监视它自己的状态,以及别的 OSD 的状态,并且报告给 Monitor;而且,OSD 进程负责在数据盘上的文件读写操作;它还负责数据拷贝和恢复。在一个服务器上,一个数据盘有一个 OSD Daemon
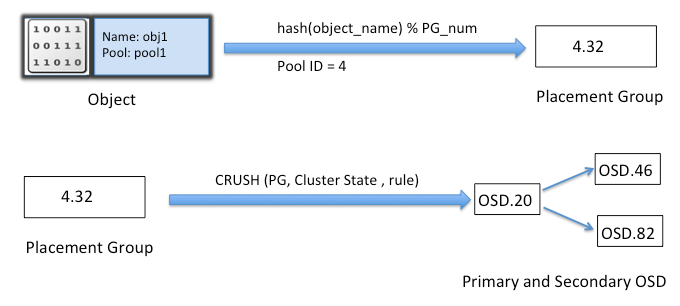
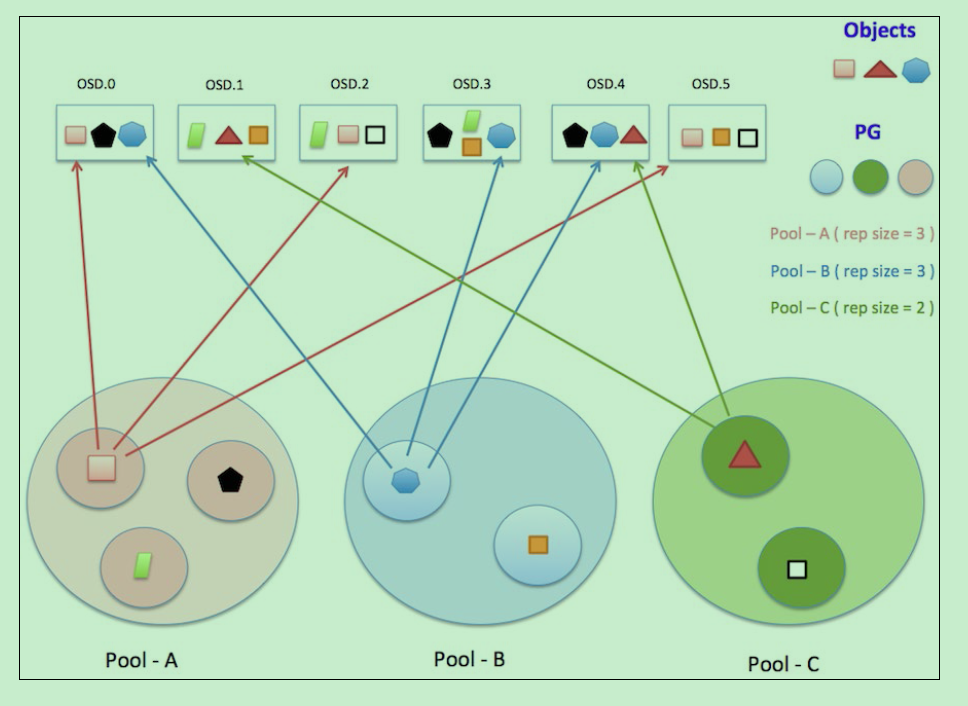
1.3.3 (Placement Group)PG 放置组
PG 也是对象的逻辑集合。同一个PG 中的所有对象在相同的 OSD 上被复制。
PG 聚合一部分对象成为一个组(group),这个组被放在某些OSD上(place),合起来就是 Placemeng Group (放置组)了。
放置组是对象存储的最小单位,对象不是每个对象自己映射到OSD,而是以放置组为单位.这样减小了集群的管理负担.
1.3.4 MDS元数据设备
MDS只有在使用cephfs时才使用,维护了集群的元数据信息.
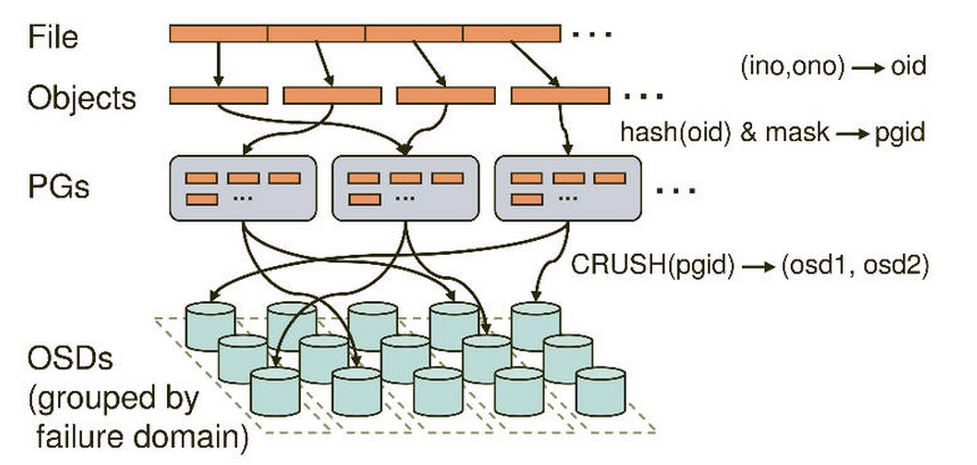
Ceph的命名空间是 (Pool, Object),每个Object都会映射到一组OSD中(由这组OSD保存这个Object):
(Pool, Object) → (Pool, PG) → OSD set → Disk
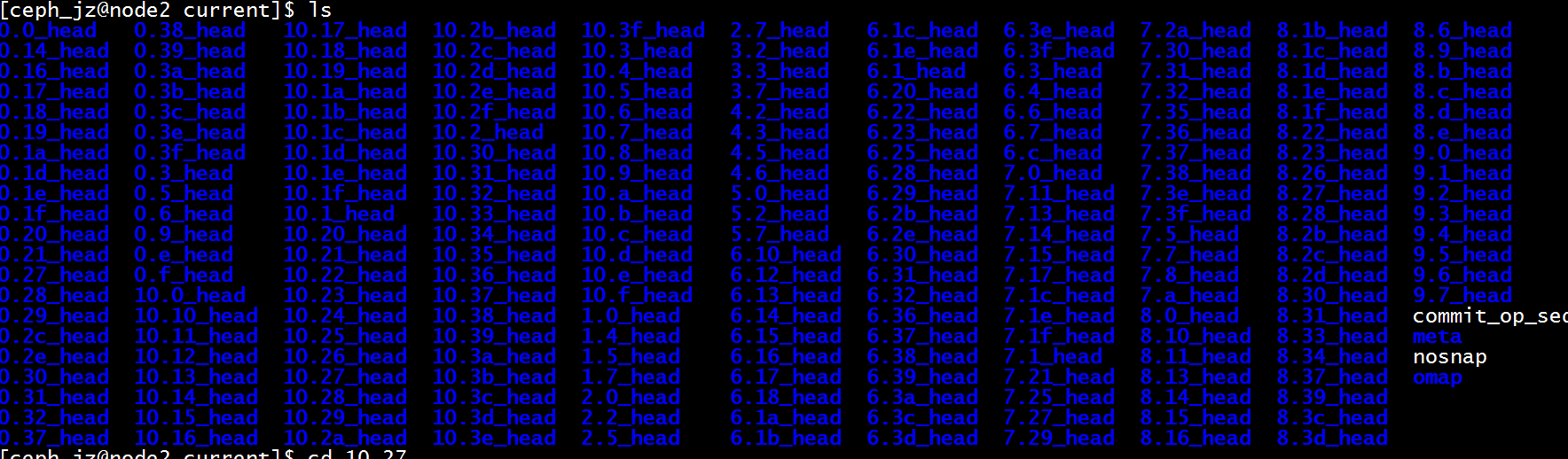
显示对象映射到放置组 pg (10.3c)在OSD 1 0 2上,共存储了3份.

一个OSD上放置组PG状态
Client从Monitors中得到CRUSH MAP、OSD MAP、CRUSH Ruleset,然后使用CRUSH算法计算出Object所在的OSD set。所以Ceph不需要Name服务器,Client直接和OSD进行通信。
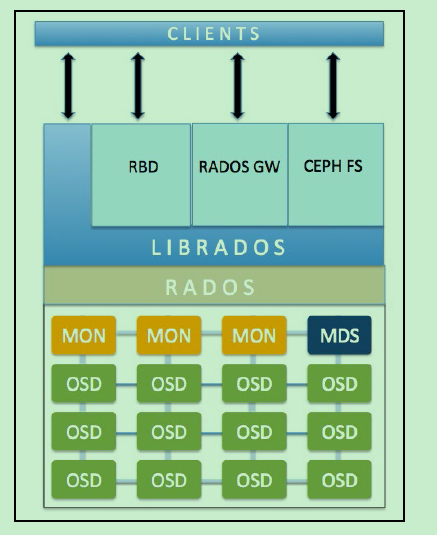
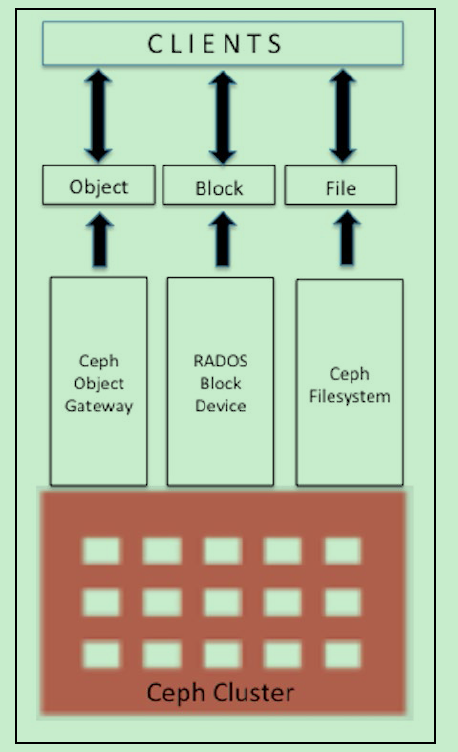
以上图说明集群从文件到OSD的过程.
从客户端来看,客户端块设备的结构.
数据读写过程读写过程
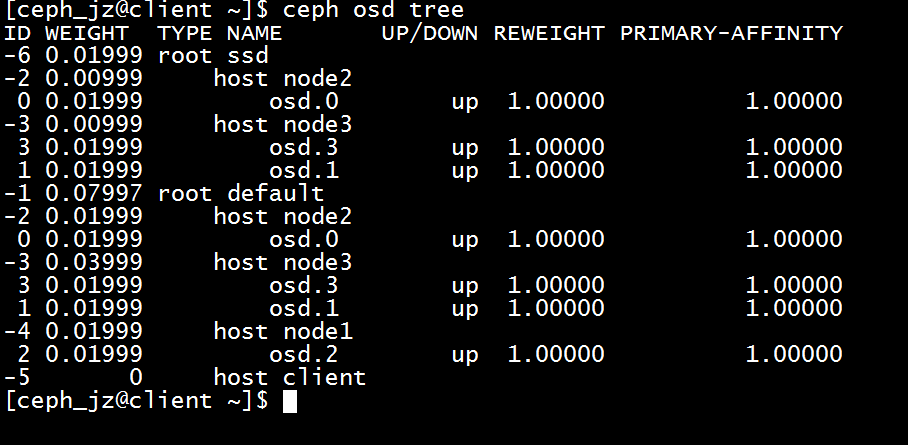
-放置组PG是集群映射对象组的单位
-给osd分层,建立SSD设备组成的快速设备pool.
理解 OpenStack + Ceph (2):Ceph 的物理和逻辑结构 [Ceph Architecture]
http://www.cnblogs.com/sammyliu/p/4836014.html
2 ceph代码
find . -name "*.c" | xargs wc -l
| 文件类型 | 行数 |
|---|---|
| *.cc | 533135 |
| *.c | 44602 |
| *.h | 258289 |
| *.sh | 24660 |
总共 860686
2.1 源代码目录
Ceph源代码目录结构详解
http://codefine.co/2603.html
从GitHub上Clone的Ceph项目,其目录下主要文件夹和文件的内容为:
1 根目录
[src]:各功能某块的源代码
[qa]:各个模块的功能测试(测试脚本和测试代码)
[wireshark]:#wireshark的ceph插件。
[admin]:管理工具,用于架设文档服务器等
[debian]:用于制作debian(Ubuntu)安装包的相关脚本和文件
[doc]:用于生成项目文档,生成结果参考http://ceph.com/docs/master/
[man]:ceph各命令行工具的man文件
configure.ac: 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









