







 本文详细介绍了Ceph中的OSDMap更新规则和OSD的加入、下线过程,以及PGMap的维护和恢复。重点讨论了CRUSH算法在数据分布中的作用,包括其稳定性、放置组计算和不同类型的bucket。此外,还探讨了OSD数量、集群结构变化的影响,以及Ceph对象存储的优势。文章提供了相关论文和参考资料,帮助读者深入理解Ceph的内部机制。
本文详细介绍了Ceph中的OSDMap更新规则和OSD的加入、下线过程,以及PGMap的维护和恢复。重点讨论了CRUSH算法在数据分布中的作用,包括其稳定性、放置组计算和不同类型的bucket。此外,还探讨了OSD数量、集群结构变化的影响,以及Ceph对象存储的优势。文章提供了相关论文和参考资料,帮助读者深入理解Ceph的内部机制。
1 maps 更新
1.1 更新规则

Because cluster map changes may be frequent, as in a very large system where OSDs failures and recoveries are the norm, updates are distributed as incremental maps(增量更新): small messages describing the differences between two successive epochs. In most cases, such updates simply state that one or more OSDs have failed or recovered, although in general they may include status changes for many devices, and multiple updates may be bundled together to describe the difference between distant map epochs.
由于RADOS集群坑内包含成千上万的设备,简单的广播Map更新消息到每个节点是不实际的.
- map增量更新,只描述变化信息,通常是一个或多个节点错误或恢复
- 间隔比较长的map,将多个跟新捆绑.一次更新
- 将压力转移到OSD间通信,OSD和client通讯,OSD自己相互更新map
一个OSD与其他Peer联系时都会共享和更新Map
心跳消息会周期的交换以检测异常保证更新快速扩散,对于一个有n个OSD的集群,用到的时间为O(logn)。
所有的RADOS消息(包括从客户端发起的消息,以及从其他OSD发起的消息)都携带了发送端的map epoch,以保证所有更新操作都能够在最新的版本上保持一致。如果一个客户端因为使用了一个过期的map,发送一个IO到一个错误的OSD,OSD会回复一个适当的增量,客户端再重新发送这个请求到正确的OSD。这就避免了主动共享map到客户端,客户端会在与Cluster联系的时候更新。大部分时候,他们都会在不影响当前操作的时候学到更新,让接下来的IO能够准确的定位。
解析 Ceph : OSD , OSDMap 和 PG, PGMap
http://www.wzxue.com/ceph-osd-and-pg/
Monitor 作为Ceph的 Metada Server 维护了集群的信息,它包括了6个 Map,分别是 MONMap,OSDMap,PGMap,LogMap,AuthMap,MDSMap。其中 PGMap 和 OSDMap 是最重要的两张Map.
这时它们的通信就会附带上 OSDMap 的 epoch
Ceph 通过管理多个版本的 OSDMap 来避免集群状态的同步,这使得 Ceph 丝毫不会畏惧在数千个 OSD 规模的节点变更导致集群可能出现的状态同步。
1.2 OSDmap过程
- 新osd启动
因此该 OSD 会向 Monitor 申请加入,Monitor 再验证其信息后会将其加入 OSDMap 并标记为IN,并且将其放在 Pending Proposal 中会在下一次 Monitor “讨论”中提出,OSD 在得到 Monitor 的回复信息后发现自己仍然没在 OSDMap 中会继续尝试申请加入,接下来 Monitor 会发起一个 Proposal ,申请将这个 OSD 加入 OSDMap 并且标记为 UP 。然后按照 Paxos 的流程,从 proposal->accept->commit 到最后达成一致,OSD 最后成功加入 OSDMap 。当新的 OSD 获得最新 OSDMap 发现它已经在其中时。这时,OSD 才真正开始建立与其他OSD的连接,Monitor 接下来会开始给他分配PG。 - osd down
这个 OSD 所有的 PG 都会处于 Degraded 状态。然后等待管理员的当一个 OSD 因为意外 crash 时,其他与该 OSD 保持 Heartbeat 的 OSD 都会发现该 OSD 无法连接,在汇报给 Monitor 后,该 OSD 会被临时性标记为 OUT,所有位于该 OSD 上的 Primary PG 都会将 Primary 角色交给其他 OSD(Monitor 维护了每个Pool中的所有 PG 信息.下一步决策
2 Ceph OSDMap 机制浅析
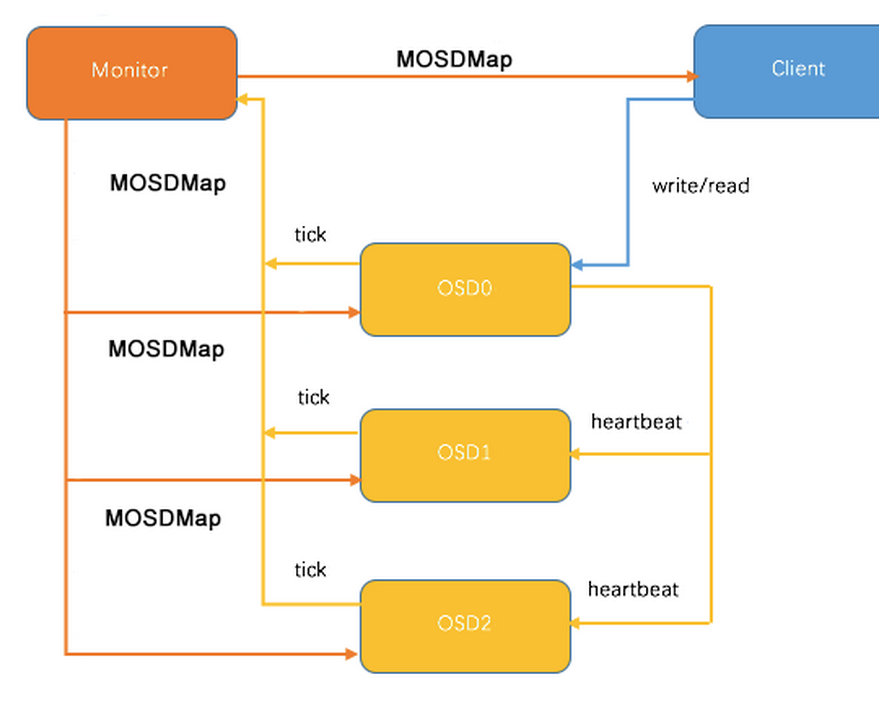
SDMap 机制主要包括如下3个方面:
- Monitor 监控 OSDMap 数据,包括 Pool 集合,副本数,PG 数量,OSD 集合和 OSD 状态。<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1184
1184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









