







基于Map-Reduce的相似度计算
转载请注明:http://blog.csdn.net/xinzhangyanxiang/article/details/9288589
不久前(6.29),参加了ChinaHadoop的夏季沙龙,听了人人的大牛讲了基于Map-Reduce的相似度计算的优化,感觉对Map-Reduce编程模型的理解又进一步加深了,在这里把该算法总结成博文,以期能够更加透彻的理解该算法。
相似度的计算在文本的分类、聚类、推荐系统、反作弊中应用广泛。本文以文本的相似度计算为例,讲述如何基于MR计算相似度。文本相似度的计算一般先使用VSM(向量空间模型)将文本表示成向量,向量的每个分量都代表某个词语在文档中的权重,权重的计算可以用词频或者TF-IDF等算法得到。
本文中,我们使用向量的内积来表示文本的相似度:
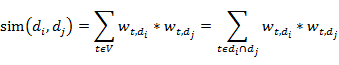
从而,我们知道,对文本相似度计算有贡献的是在两个文本中同时出现过的词语。
而一个数据集的文本相似度计算问题是计算该数据集中每个文本对的相似度。同许多问题一样,在文本数目比较小的时候,内存可以完全载入这些向量,可以很快的计算;但是当文本数目变大到一定程度,程序就会运行的很慢,一是因为内存不能装载下,不停的内存换入换出十分耗时,二是因为该问题的时间复杂度是O(N3),N变大会导致程序的时间成立方级增长。
那么如何使用Map-Reduce框架解决这个问题呢?
首先,问题的输入可以看成一个矩阵,如图1[1]所示:
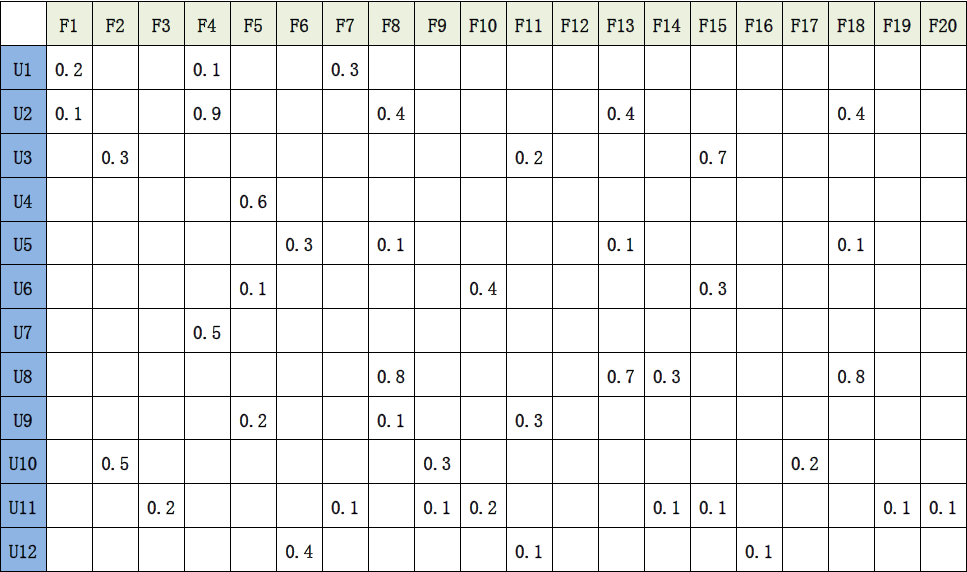
图 1 文本-词语矩阵或者用户-特征矩阵
其中,U代表文本,F代表词语。如果直接以U为键进行Map-Reduce,那么会遇到一个问题,因为要计算数据集中所有的二元文本对的相似度,所以不得不将所有的数据发往每一个节点,或者只有一个Reduce任务工作,以计算每个二元文本对的相似度。
所以,为了解决这个问题,我们将矩阵转置,以F为键。这样,解决该问题就由两个Map-Reduce过程完成。第一个MR过程称为倒排索引,对每个文档,对其中的每个词语,以词语为键,文档标号与词语在该文档中的权重为值输出,这样,我们就得到如(F4,[(U1,0.1),(U2,0.9),(U7,0.5)])格式的输出。第二个MR过程计算文本相似度,以上一个MR过程的输出为输入,在Map过程中以文本对为键,以权重值的乘积为输出,比如上面的F4输出,map后变为[((U1,U2),0.09),((U1,U7),0.05),((U2,U7),0.45)],这样,就得到了在所有的在两个文本中共同出现的词语针对该两个文本的权重乘积;然后在reduce过程中将相同键的值相加,就得到了所有的二元文本对的文本相似度。完整的Map-Reduce样例如图2[2]所示:
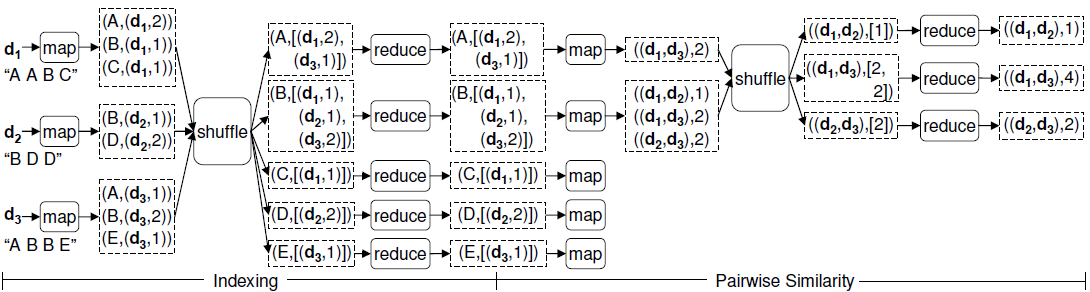
图 2 矩阵转置后的Map-Reduce过程
经过这种设计之后,我们就可以使用Map-Reduce过程处理文本相似度问题了。
我们还可以通过Stripe算法[3]来优化IO,Stripe算法的详细可以参考引申链接3,它与上图方法的不同之处的根本在于输出的表示形式,文本相似度问题的输出是一个对称矩阵,而上图中的输出的表示方法是以二元对为键,以相似度为值,在Stripe算法中,输出的表示则是以单个文档为键,以一个关联数组为值,关联数组中的键为文档,值为关联数组中的键与输出键对应的两个文档的相似度,上图的输出使用Stripe算法的输出表示为(d1,[(d2,1),(d3,4)]) ,(d2,[(d3,2)]),当然,根据输出的形式,上图中的Pairwise Similarity部分的map与shuffle的输出都做出相应变化,据说,该算法可以节省1/3的空间。
还能做的优化就是负载均衡方面的考虑了。利用贪婪算法切分负载,对于任务队列中的每一个任务,将其放到负载最小的机器上面去。这种方法对数据实时切分,作为Map的输入。
还有一种优化是热点消除,使用Mirror Mark算法对比较大的任务进行切分,MirrorMark算法的基本思想是将所有的数据复制成多份到多台机器上,每台机器上只对一部分数据进行计算,Mirror是指数据存储多份,Mark是指数据分配到机器前对要在该机器上计算的数据做标记,在机器上只计算标记的数据;Mirror Mark算法能够使运行时间最长的任务运行时间变短,从而降低整个Map-Reduce的时间。
实际上,对于文本-词语矩阵或者用户-特征矩阵,计算相似度的问题其实可以看做是矩阵乘以矩阵的转置的问题。图2所示的MR过程实际上对矩阵的乘法做了两个方面的优化,一是按照用户对或者文本对进行分布式划分,二是利用了矩阵的稀疏性,不计算特征值为0的部分。














 2111
2111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









