







前文:
数字媒体技术揭秘
四、压缩技术
4.1 理论基础
廿世纪中叶,为了从理论上证明对信息系统进行优化的可行性,Shannon引入了熵的概念,用来表示信息的不确定性,熵越大,信息的不确定性就越大[4],而信息的不确定性越大,其对应的传输和存储成本就越高。换句话说,如果某种信息的熵不是那么大,则人们应该有信心使用有限的资源去承载它。举一个简单的例子,假设气象台负责预报明天是否天晴,而地震局负责预报明天是否地震,那么显然,来自气象台的信息要比来自地震局的信息具有更大的不确定性,也就是说气象信息的熵更大,如若使用喇叭来传递信息,对于气象台而言,以鸣喇叭来表示天晴或者表示天阴,对喇叭的使用寿命影响并不大,地震局则不然,如果以鸣喇叭来表示地震,那这喇叭的使用寿命远大于气象台的那一只。这说明,信息传输的成本是有下限的,这个下限由信源的熵决定,而如何达到或接近这个下限成为通信领域的主要研究内容,数据压缩便是其中的主题之一,在Shannon的通信模型中属于信源编码的范畴。
通过建立一个简化的信源模型可以算出熵的最大值,这是非常有意义的,基于这个最大熵可以得到传递信息的极限成本。离散平稳无记忆信源就是这样的一个简化模型,源自这种信源的信息统计特性相同,但相互独立,于是可以用一个概率空间[M, P]来抽象这些信息,其中M={M1, M2, …, Mk}是概率分布为P={P1, P2, …, Pk}的一个随机变量,那么M的熵由下面公式给出:
公式中 −log₂Pi 表示Mi的信息量:概率越大信息量越小。于是不难发现, H(M)不过是信息量的一个概率平均。对于离散平稳无记忆信源,H(M)也可以看作信源的熵,针对某种特定的分布,这个熵存在最大值,对应的分布叫做最大熵分布。离散无记忆信源的最大熵分布是均匀分布,此时其熵值为log₂(k),k是其可能值的个数。
如果信源是有记忆的,也就是说信源产生的信息相互并不独立,则需要引入联合熵的概念。以两个相关的随机变量表示信源产生的两个信息来构造一个最简单的模型,以下三个公式成立:
H(X,Y) = H(X)+H(Y)-I(X,Y) (4-1)
I(X,Y) = H(X)-H(X|Y) = H(Y)-H(Y|X) (4-2)
H(X|Y) = H(X,Y)-H(Y) (4-3)
其中,H(X,Y)为联合熵,表示这两个信息整体上的不确定性;I(X,Y)为互信息量,表示两个信息的相关性,不相关的信息互信息量为0;H(X|Y)叫做相对熵,表示在Y已知的情况下X的不确定性。第一个公式说明,对于相关的信息,其各自熵的和会大于描述其整体不确定性的联合熵。第二个公式定义两个信息的互信息量为其中一个的熵减去其相对熵。第三个公式表示,X在Y已知的情况下的相对熵等于两个信息的联合熵减去Y的熵。
对于有记忆信源,其熵值不再等于其产生的某一个的信息的熵,这种情况下要使用熵率来描述信源的不确定性,这是一个极限值,假设Hn是信源产生的n个信息的联合熵,则熵率就是n趋于无穷大时的Hn/n。
数据压缩就是对信源产生的信息进行编码的一个过程,即使用某个符号表,如0和1来表示要传输的信息。这里涉及到两种情形:无损编码和有损编码。对于无损编码来说,要求解码之后的信息和编码之前的信息完全相同,即编码过程不引入任何失真,在这种情况下,如果使用二进制符号来表示信源产生的某个信息,其平均长度不能小于信息的熵或信源的熵率。有损编码则会在编码过程中引入失真,因此,从根本上讲是一个信息率-失真最优化的问题。
假设编码过程引入的均方失真为D,则存在一个函数R(D),表示不超过给定失真D的前提下对该信源编码所需要的最小的信息率,即所谓的率失真函数。如果信源的概率分布给定,平均失真D仅由信源编码前后的转移概率——亦即编码方式决定,则率失真函数给出的其实是一个信源编码的极限信息率,也就是说,对于既定信源,总可以找到一种编码方式,能够保证在既定失真的前提下达到率失真函数给出的最小信息率。率失真函数取决于信源的统计特性,一般不存在显式的表达式,但是对于某些特定分布的信源,率失真函数能够以明了的形式给出,比如高斯分布的连续无记忆信源的率失真函数为:
再举一个二值的离散无记忆信源X的例子:概率P分别为0.1、0.2、0.3和0.5的情况下其率失真函数如下图示:
可以发现,当P=0.5,即均匀分布的情况下,信息率失真函数最靠上,也就是说给定最小失真对应的极限信息率越大。当失真为零时,信息率的极限为1,亦即信源的熵。也就是说,有这样一个信源,它以50%的概率在产生符号0和符号1,则无失真地编码该信源产生的一个符号最少也需要1个比特,注意,这是传输成本最高的一种信源。此时,我们便不难理解气象台的喇叭为什么更容易损坏了。
4.1.1 变换编码
从理论上讲,变换的主要目的是去相关。由公式4-1可知,对于相关性很强的两个随机变量,其互信息非常大,导致两个信源的熵的和远大于其联合熵。如果将这两个随机变量看做为一个二维的随机向量,通过一个变换矩阵,可以将{X, Y}变换为 {X’, Y’},在这一过程中,H(X,Y)=H(X’,Y’),如果变换矩阵选择适当,令I(X’,Y’)=0,则H(X’)和H(Y’)将远小于H(X)和H(Y),从而对X’和Y’编码需要的比特数将大大减少。能够使X’和Y’相互独立的变换叫做KL变换,这是一种理论上的最佳变换,但由于相应的变换矩阵需要通过X和Y的统计特性来计算,在工程上很难应用起来。
可以从更直观的角度来理解这种说法:以图像数据为例,假设每个像素点的亮度范围为0~255,则在空间域独立地来看某个像素点的话,其统计特性是近似均匀的,也就是说,各阶像素值发生的概率大致都差不多,因此,至少需要8个比特编码一个像素值,而不能够给某些像素值多些的比特,而给某些值少一些。但实际上,对于一个来自某幅图像的像素矩阵采样,如果其中某个像素点为值0的话,其它点为255的概率也不会太大。如下图所示,左图是典型的图像数据(采样自Lenna),而右图则极为罕见,在编码的时候,左图数据应该给以多于右图数据的比特数,要达到这样的目标,在缺少完美的矢量量化方法之前,变换不失为一种很好的工具。


那么,变换域中各点取值的概率分布又如何呢?首先,各点的值域将发生变化,比如DCT变换域各点的取值范围为-2048~2048;其次,各点的概率分布更加独立。 还以上面两幅图像为例,与罕见的图像采样(右图)相比,经典的图像采样(左图)变换域右下方向的值更接近0。因此,对于图像数据来说,变换域右下角出现大量0值是比较常见的,可以使用更少的比特编码这些大概率的情况。换句话说,变换是为了从全局的角度抽取一组数据的特征,并将这些特征分割开来。
DCT是音视频压缩中的一种常用变换,它虽然不能保证使变换后的随机变量相互独立,但仍能大大减少它们的相关性,而且,DCT变换还能产生能量聚集的效果,即对于变换后的随机向量,能量相对集中在索引较小的分量上,更有利于量化。
4.1.2 差分编码
差分编码基于预测来实现,即不编码原始信源数据,而去编码原始信源数据和预测数据的差分数据,主要目的是在不引入失真的前提下减小原信号序列的动态范围。假设信源产生了一个随机序列:
S(0), ..., S(n-5), S(n-4), S(n-3), S(n-2), S(n-1), S(n)设S’(n)为S(n)的预测值:
S'(n) = f(S(n-1), S(n-2), S(n-3), S(n-4), S(n-5))则预测值序列为:
S'(0), ..., S'(n-5), S'(n-4), S'(n-3), S'(n-2), S''(n-1), S(n)令d(n) = S(n)-S’(n),则差分序列为:
d(0), ..., d(n-5), d(n-4), d(n-3), d(n-2), d(n-1), d(n)预测的准则是均方误差最小,及找到一个合适的预测函数f,使d²(n)最小。 与变换编码不同之处是,即使找到了一个最优的预测函数f,差分编码也不一定会提高编码效率。如果随机序列中个分量不具备相关性甚至是负相关的,差分序列中个分量的均方差会变得很大,甚至大于原始序列中各分量的均方差,这种情况下编码效率会严重下降。
对于一个相关系数接近1的马尔可夫序列,S’(n)=S(n-1)是一个较优的预测函数,这种差分编码便是广泛使用的DPCM技术。
需要注意的是,在实际的编码过程中,由于解码端无法得到原始值,所以预测函数通常使用预测值来代替原始值,即:
S'(n) = f(S'(n-1), S'(n-2), S'(n-3), S'(n-4), S'(n-5))对于DPCM,S’(n)=S’(n-1)
4.1.3 熵编码
通过变换和预测等方法使信源的统计特性得到一定的改善之后(去相关性,降低均方差……),接下来需要进行的是熵编码,也是数据压缩的最后一步,其主要责任是将压缩视频的各种头信息、控制信息以及变换系数转换为二进制的比特流。有两种最基本的熵编码方法:
- 定长编码: 对所有的待编码信息使用相同长度的码字
- 变长编码: 使用不同长度的码字
假设某个待编码的信息元素A∈{A0, A1, …, An},如果采用定长编码,需要的比特数为log₂(n)取整,而使用变长编码,其平均码长的极限取决于该信息的熵H,除非是均匀分布,不然所需要的比特数必定小于log₂(n)。因此,如果某个信息元素在概率分布上是极度不均匀的,通常都会采用变长编码的方式,即概率小的值使用长码字,概率大的值使用短码字。
指数哥伦布码、Huffman编码和算术编码都是常用的变长编码方法。
4.1.4 量化
量化[5]是一种多对一的映射,是引入失真的一个过程,也是限失真信源编码技术的基础。无论是对时间采样后的模拟信号进行数字化的过程,还是对数字序列进行有损压缩的过程,都需要完成一个由输入集合到输出集合的映射,这个映射是由量化来实现的。
最简单的量化方法是将单个样本的取值进行量化,因为被量化的变量是一维的,所以这种量化方法叫做标量量化。设n阶标量量化器的输入为连续随机变量x,输出为离散随机变量y,其中:
x∈(A0, An), y∈{Y1, Y2, …, Yn},A0≤ Y1 ≤ A1 ≤ Y2 ≤ …… An-1 ≤ Yn ≤ An。
则y 的取值由下式决定:
当量化阶数n一定时,选择合适的Ai 和Yi 可以使量化器的平均失真最小,这时的量化称为最佳标量量化。若输入变量x满足均匀分布,可以将(A0, An)均匀分割成n个小区间,每个小区间的中点作为量化值。这种量化方法叫做均匀量化,对于均匀分布的输入变量来说,均匀量化是最佳标量量化。当采用均方失真函数时,可以计算出其平均失真为Δ²/12,其中Δ = (An-A0)/n。
然而,从率失真的角度来考虑,最佳标量量化并不能达到最佳率失真编码的要求,通常需要对量化后的数据进行继续进行处理,如熵编码等。
为了使量化后不再进行后处理而能逼近率失真函数的界,人们开始探讨根据多个连续信源符号联合编码的方法,即矢量量化技术。
假设X = {X1, X2, …, Xn}是信源的一个n维矢量,它的取值范围是n维空间中的一个区域Rn,一个k级的矢量量化器就是X∈Rn到k个n维量化矢量Y1, Y2, …, Y的映射函数Q(X)。对于任意Yi,i = 1, 2, …, k,指定一个n维的区域Ai,对于所有X∈Ai,有Q(X) = Yi。其中Ai称为Yi的包腔,各量化矢量称为码字,它们的集合称为码书。如果选择的码书和各包腔可以使平均失真最小,这时的矢量量化称为最佳矢量量化。
4.1.5 率失真优化
率失真函数给出了信源编码的信息率极限,而率失真优化则研究如何达到该极限,即在给定信息率上限Rc的前提下,寻找一种编码方法使D最小化:
min{D(P)} s.t. R(P) ≤ Rc其中,P表示一个信源编码前后的转移概率,代表某种编码方法。
这是一个典型的有约束的非线性规划问题,可以通过拉格朗日乘子法转化为一个无约束的求极小值的问题:
min{D(P)+λ*R(P)}这里的λ与约束条件Rc息息相关,目标速率越大,则λ越小,当λ为零时,表示不限制目标速率,则只剩下min{D(P)}了。
实际的编码过程不是数学推理过程,无需对上面的方程求解,只要确定了λ(这是个关键点),通过穷举搜索即可找到最佳的编码方法。
4.2 图像
4.3 视频
4.3.1 混合编码系统
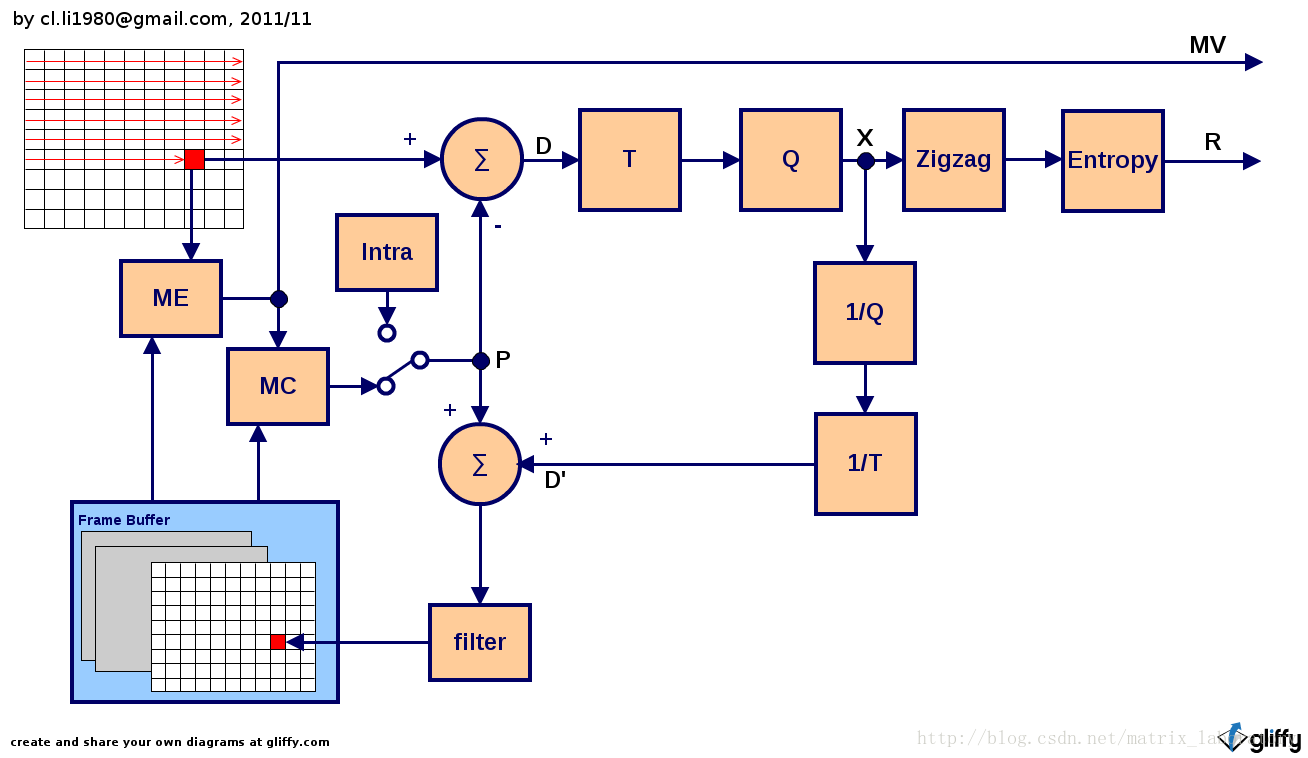
所谓混合指的是运动预测差分编码和变换编码的混合,其一般编码原理由上图给出,通常是以宏块为单位按照扫描顺序进行编码,当然也不排除基于某种大规模并行运算的编码方法改掉这一方式。整个处理过程中,涉及到的数据包括:
- P: 预测值
- D: 差分值
- D’: 本地恢复的差分值
- X: 量化后的残差变换系数
- R: 经过熵编码的残差变换系数
主要的处理模块包括:
4.3.1.1 ME:运动估计
这里的运动估计指的是为待编码宏块中的各个像素点寻找最佳预测值的搜索过程,找到的预测值位于某一帧已经编码并重建的图像中,与被预测的像素点在位置上存在偏差,这些偏差就叫作运动矢量,它们和参考帧的位置共同作为运动估计过程的最终输出物。
4.3.2.2 MC: 运动补偿
运动补偿也叫做运动补偿预测,这一过程根据运动估计给出的运动矢量和参考帧位置生成待编码宏块各像素点的预测值。由待编码图像和经运动补偿的参考图像逐点相减可生成一副差分图像,相对与自然图像,差分图像的动态范围大大减小,从而更有力于后续的压缩
4.3.2.3 T: 变换
通过对待编码像素与预测值的差值进行一个二维变换,有效地去除空间冗余。
4.3.2.4 Q: 量化
变换系数的量化通过引入失真降低比特率。
4.2.3.5 1/T: 反变换
这一过程和下一过程的主要目的是生成本地重建图像。由于解码器端无法获取原始图像,为了防止误差积累,需要在编码器端复制解码过程,使用解码后的重建图像代替原始图像进行预测。
4.2.3.6 1/Q: 反量化
4.2.3.7 Zigzag: Z扫描
Z扫描可以将二维的残差变换系数转换为一维的序列,更有利于其后的熵编码。
4.2.3.8 Entropy: 熵编码
利用数据流内部的统计特性对一维的残差变换系数进行无损压缩。
4.2.3.9 Filter: 环内滤波
环内滤波有两个目的:其一是为了去除因变换产生的块效应;其二是通过改善重建图像,使预测过程更有效。
4.2.3.10 Intra: 帧内预测
在某些情况下,无法获得参考帧,或参考帧中的预测值与实际值的差距过大(比如视频序列发生场景切换),则不采用已编码重建图像中的像素值作为预测值,而以当前图像中已编码部分的像素值作为预测值。
4.2.3.11 模式选择
此外,编码过程还隐含着一个模式选择的模块,体现在上图中就是决定帧内还是帧间的开关,而实际上除了这个的开关,其他诸如运动补偿、帧内预测都要涉及到模式选择,譬如基于多大的块进行运动补偿、使用哪一个参考帧等。
运动补偿预测可以用下图来表示
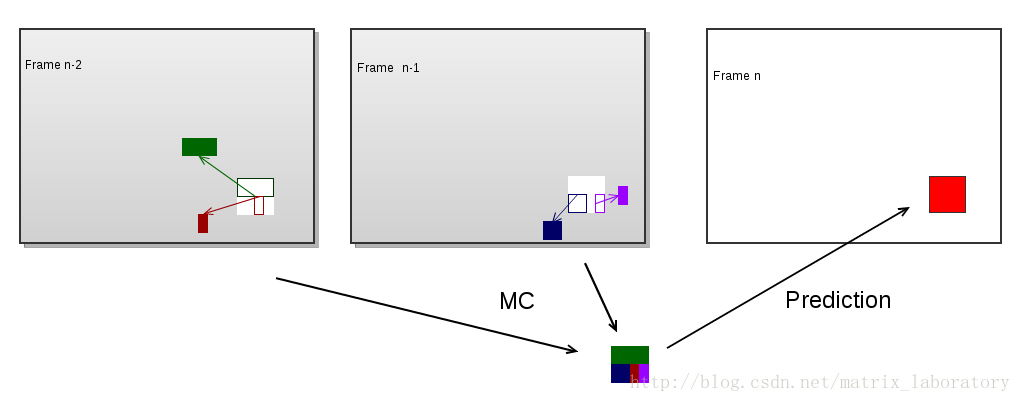
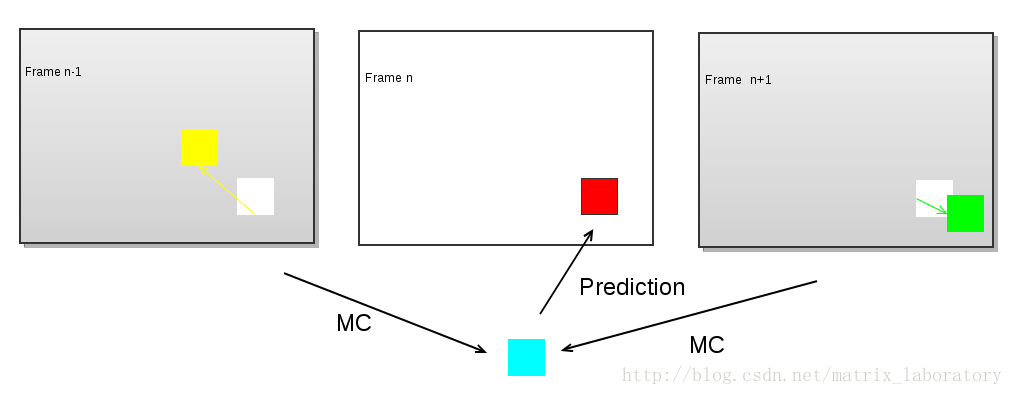
红色部分为待编码的宏块,彩色部分为利用运动补偿由本地解码的重构图像生成的预测值,而最终编码的是红色部分和彩色部分的差值。可以看出,为了完成该宏块的预测,需要四个运动矢量和两个参考帧。某些编码技术如双向预测及MPEG2中的Dual-Prime会令预测过程更加复杂,预测值需要由两个经运动补偿的预测值加权平均得到:














 379
379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









