







原创作品,出自 “晓风残月xj” 博客,欢迎转载,转载时请务必注明出处(http://blog.csdn.net/xiaofengcanyuexj)。
由于各种原因,可能存在诸多不足,欢迎斧正!
一、研究背景
推箱子游戏中的路径查找问题—给定一方格,求两点最短距离。
传统求两点最短路径的算法有:
1.通用的搜索算法
2.解决无负权边的带权有向图的单源最短路问题的Dijkstra算法
3.求解含负权边的带权有向图的单源最短路径问题的Bellman-Ford算法
4.Bellman-ford算法改进版快速求解单源最短路经的Shortest Path Faster Algorithm
…
以上算法虽能百分之百找到最短路径,但是随着问题规模的扩大,随之而来的是组合爆炸问题,在有限的时间范围内难以求解问题。于是人们开始探索在有限时间内可以求得最优解的近似解。遗传算法求解两点最短路经就是在这样的背景下诞生的。
遗传算法是基于生物进化原理的一种全局性优化算法,是借鉴生物的自然选择和遗传进化机制而开发出的一种全局优化自适应概率搜索算法,是生物遗传技术和计算机技术结合的产物。它采用的是启发性知识的智能搜索算法,在高空问复杂问题上比以往有更好的结果。
本题大致就是求两点的最短路径,所不同的是我们没有给定问题的解空间,即在没有给定两点可达路径的基础上求两点的最短路径。可达路径基本可以经过遗传算法演化而来。
二、组内分工
| 成员名 |
身份 |
分工 |
| 徐进 |
组长 |
程序实现 |
| 熊凯平 |
组员 |
论文撰写 |
| 黄江 |
组员 |
算法设计 |
三、问题分析
给出n*m的二维方格,给定障碍物(数目及坐标),起点和终点,问绕过障碍物从起点到终点的最短路径。
基于题目,构建符合题意的模型。用户选择二维方格的行和列,即n和m。然后随机生成障碍物,为求合理真实,障碍物数目应控制在一定范围内,位置既不能太稀也不能太密,起点终点随机分布。我们的设计目标是尽可能不认为干预,让箱子自己跑。
在此说明,题目虽说是推箱子,但更我们玩的推箱子游戏是有所区别的。有图为证:
此图是实例给出的。不考虑推的方向,在此推箱子转化为路径查找问题。
四、算法设计
本题核心是求两点(绕过障碍的前提下)最短的哈夫曼距离。
一个很好地解决方案是BFS,时间复杂度为(n*m),空间复杂度接近常数。下面是BFS跑出的结果
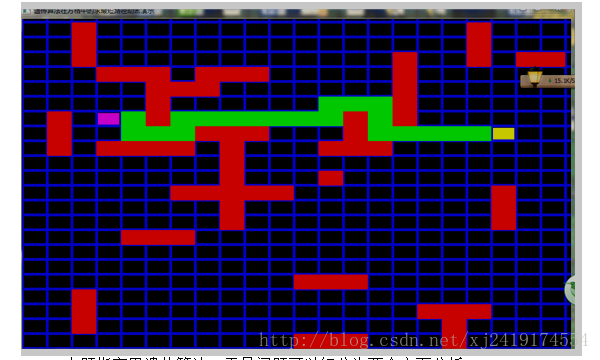
本题指定用遗传算法。于是问题可以细分为两个方面分析:
1.找到从起点到终点的路径
2.在所有的路径中找到尽可能短的。
在遗传算法中二者必须得到权衡。
本题没有用到高级的数据结构,用到了STL中的顺序容器Vector来存储每条染色体。然后开了些数组。
遗传算法 ( GA , Genetic Algorithm ) ,也称进化算法 。 遗传算法是受达尔文的进化论的启发,借鉴生物进化过程而提出的一种启发式搜索算法。
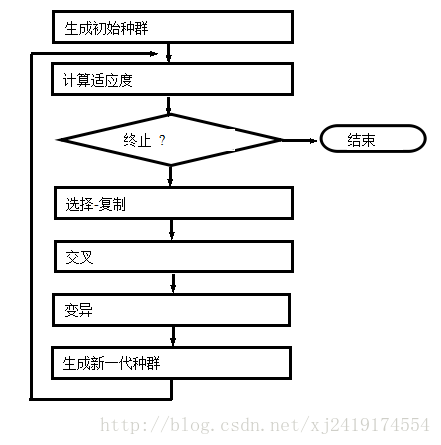
我们的遗传算法通用流程框图
种群(Population):生物的进化以群体的形式进行,这样的一个群体称为种群。
个体:组成种群的单个生物。
基因 ( Gene ):一个遗传因子。
染色体 ( Chromosome ) :包含一组的基因。
生存竞争,适者生存:对环境适应度高的、牛B的个体参与繁殖的机会比较多,后代就会越来越多。适应度低的个体参与繁殖的机会比较少,后代就会越来越少。
遗传与变异:新个体会遗传父母双方各一部分的基因,同时有一定的概率发生基因变异。
五、算法实现
编码:需要将问题的解编码成字符串的形式才能使用遗传算法。最简单的一种编码方式是二进制编码,即将问题的解编码成二进制位数组的形式。
§ 00 = up
§ 01 = right
§ 10 = down
§ 11 = left
每条染色体由只含0、1的偶数字符串组成,以上是4个基本基因片段。本题染色体是变长的(需考虑到具体题目),在不人为干预的情况下染色体所代表的运动方向是不确定的,这给问题的求解带来难度,如果染色体都过短则可能得不到路径;反之,如果染色体都过长,则可能得不到最短路径。我的方案是将染色体长度控制在[minlen,maxlen]之间,其中minlen为横坐标之差与纵坐标之差的和,maxlen为n*m-number(number为障碍物数目)。这样基本可以保证有染色体可以进化成最短路径。所有的遗传操作的基本单位都是2位0、1串。
适应度函数 ( Fitness Function ):用于评价种群中某个染色体的适应度,用Fitness(x)表示。本题及要找路径,还要找到最短的路径,即在从起点到目标点的可达路径都不知道的情况下的要筛选出最短的路径。这是本题面临的主要挑战。课件上给出的适应度函数如下:
Fitness[i] = 1 – (distance[i] / max possible distance)
其中distance[i]为染色体表示运动的终点与目标点的哈夫曼距离(在不可以障碍物的情况下)。这样的适应度函数如果不做修改时很可能陷入局部最优的。如图:
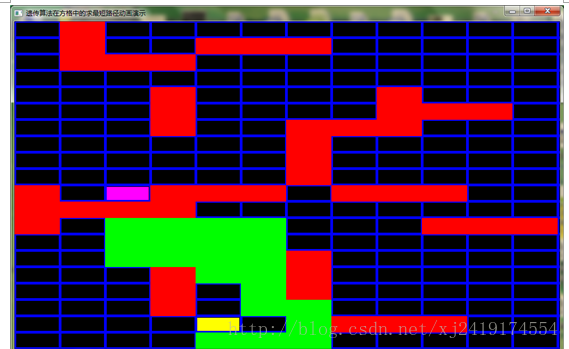
上图种群很可能找不到最优解。因为要找到最短的可达路径必须绕过去,而在绕的过程中经过上述适应度函数计算出来的适应值是很大程度上减小的。
我的解决方案是将distance[i]修改为BetDis[x][y],BetDis[x][y]表示(x,y)与目标点的考虑障碍物的最短距离。从而可以有效避免上述原因造成的过早陷入局部最优解。关于BetDis[x][y]可以通过预处理求得。通过一次BFS可以求得方格中所有点到目标点的最短距离,时间复杂度为O(n*m),空间复杂度也很低。
上述适应度度函数只能保证尽可能接近目标点,不能同时得到较短的路径。我们做了一些尝试,已知最短路径应该与目标的接近程度成正比,与路径长度成反比。我尝试将适应度函数修改为
NewFitness[i] = a*Fitness[i]+b/len;
或 NewFitness[i] = a*Fitness[i]/len;
其中a,b为待定常数,len为染色体Chro[i]的长度。
但最终没有找到比较合适的a,b。
于是我们还是选择了 Fitness[i] = 1 – (BetDis[x][y]/ max possible distance) 作为适应度函数。我们通过修正染色体来权衡二者。由于每条染色体都要求适应度,一个想法是在求适应度的过程中完成染色体的修正。我的修正方案有两个:
1.若某染色体Chro[i]在运动过程中经过目标节点,则直接将Fitness[i]置为1,同时截断后面的基因片段,即缩短染色体。如:
01 10 10 01 01 00 11 00 10 10 01 10 11 11 11 00 00 10 01
前8个基因片段就到达目标点,则后面的都是有害的,于是截断,修正染色体为
01 10 10 01 01 00 11 00
看似不符自然规律,但却给解题带来极大的优化。
2.若某染色体Chro[i]在运动过程中遇到不合法状态,即走到障碍物上或越出方格,则要修正相应的基因片段,我们采用不回溯法。若当前状态不合法,则转入下一个状态,
Direction=(Direction+1)%4,其中Direction取值为0,1,2,3。
Direction=0,对应基因片段00
Direction=1,对应基因片段01
Direction=2,对应基因片段10
Direction=3,对应基因片段11
这样的修正方法导致染色体是可以回走的。回溯法可以避免回走,但一个长度为Size的染色体最坏的时间复杂度为O(3^size),即当前染色体所走的每一步都要回溯,这样的时间复杂度是难以接受的。所以我们选择了不回溯的。如果繁衍代数足够多,在大量交叉、变异的前提下可以降低回走的影响。
遗传算法有3个最基本的操作:选择,交叉,变异。
选择:选择适应度高的染色体个体存活下来,淘汰适应度地的染色体个体。常用的选择策略是 “比例选择”,也就是个体被选中存活的概率与其适应度函数值成正比。假设群体的个体总数是PopulationSize,那么那么一个体Chro[i]被选中存活的概率为Fitness(Chro[i])/( Chro[0]+ Chro[1] + …….. + Chro[PopulationSize-1] ) 。比例选择算法可以通过“轮盘赌算法”( Roulette Wheel Selection ) 实现。关于轮盘赌算法的实现在这就不多说了。
为了防止进化过程中产生的最优解被交叉或变异所破坏,可以将每一代中的最优解原封不动的复制到下一代中,即我们采用了精英主义(Elitist Strategy)选择,这是我们采用的一种优化方案。
交叉(Crossover):基因交叉,就是把两个父体部分结构加以替换,生成新的个体的操作,本题的交叉操作比较简单,就是随机选择选择长度相同的染色体进行交叉,我们交叉的起始位置随机。如:
交叉前:
父辈1: 01 10 10 01 00 00 10 11 01 01 10 10 00 00 11 11 00 01
父辈2: 01 10 00 01 10 11 10 00 01 10 10 10 00 10 11 01 01 11
交叉后
子辈1: 01 10 10 01 00 11 10 00 01 01 10 10 00 00 11 11 00 01
子辈2: 01 10 00 01 10 00 10 11 01 10 10 10 00 10 11 01 01 11
所有交叉都是在交叉率CrossoverRate的控制下进行的,通过交叉率计算出当前种群的交叉数CrossoverNum。
While(交叉数CrossoverNum--)
{
随机选择等长的两条染色体;
随机选择起始位置进行交叉;
}
为了使程序效率不致太低,我们在交叉过程中并没有防止含非法状态的染色体产生,而是在求适应度的同时修正染色体。
变异(Mutation):在基因交叉之后产生的子代染色体个体中,有一部分个体的某个基因片段以很小的概率发生转变,这个过程称为变异(Mutation)。我们的变异操作也变较简单,随机选择染色体,随机选择染色体变异位置,随机选择变异方向,这样可以保证过早陷入局部最优解,因为假设种群没有最优解所必需的某个基因,而选择、交叉操作不产生新基因,只有通过变异完成。如:
变异前:10 01 01 01 10 10 11 01 11 00 11 11 11 00 11 00 10 10 01
变异后: 10 01 11 01 10 10 11 01 11 00 11 11 11 00 11 00 10 10 01
所有变异都是在变异率MutationRate的控制下进行的,通过变异率计算出当前种群的变异数MutationNum。
While(变异数MutationNum--)
{
随机选择某个染色体在随机位置向随机方向变异;
}
同交叉操作,为了使程序效率不致太低,我们在变异过程中并没有防止含非法状态的染色体产生,而是在求适应度的同时修正染色体。
六、算法实现伪代码
遗传算法伪代码GeneticAlgorithm
{
while(当前繁衍代数小于设定的繁衍代数)
{
当前繁衍代数加1;
进行选择操作Selection();
进行交叉操作Crossover();
进行变异操作Mutation();
}
}
算法的时间复杂度为O(Generation*popsize^2)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1855
1855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









