







已经有一个多月没有看书了,最近想入手几本可口的书,可是鉴于本人有着强烈的选择恐惧症,所以就想到了豆瓣读书
但是豆瓣读书不能根据评分来筛选书籍,所以就想通过爬虫来把豆瓣读书中某一类别的书籍只要评分大于9.0的都筛选出来,并且为了能够准确找出,还实现了下载封面。
好,需求出来了。
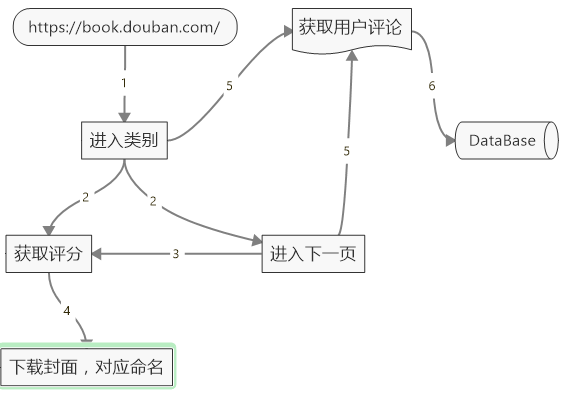
以下是初步的流程图:
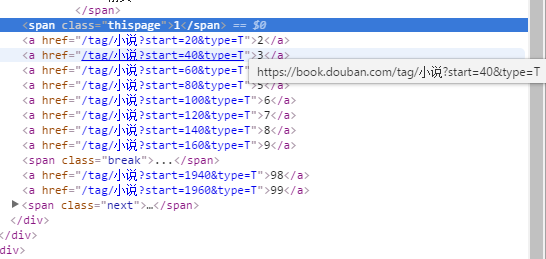
通过查看豆瓣读书的的源代码可以很容易发现其链接规则:
对于每个链接的处理,有三种方法:
- 对每个页面都递归进行爬虫,不会担心重复,在加入list之前可以判断重复嘛。但是这样做无疑是消耗了太多资源。
- 观察发现,在第9页之后,列表会显示到13页,也就是加了4。依此类推…但是这么做太麻烦了,并且也会多费资源。
- 这是最简单的方法,自己拼出来。这种方法虽然简单,但是一旦命名规则发生了变化,就是失效。但是考虑到这只是一次简单的需求,暂且就这么弄了。
上代码:
#拼出所有的链接地址
def toNextPage(self,rawUrl,tag):
#查看了几个标签,没有超过100的,所以这里暂且定到100
pageNum = [x * 20 for x in range(100)]
rawUrlNet = urlparse(rawUrl).netloc
rawUrlScheme = urlparse(rawUrl).scheme #头
bookLinks = []
#拼出所有的链接地址
for item in pageNum:
url = rawUrlScheme+"://"+rawUrlNet+"/tag/"+tag+"?start="+str(item)+"&type=T"
bookLinks.append(url)
return bookLinks点击urlparse可以参考它的具体用法。
链接弄好之后,就可以在它上面迭代爬取内容了。
def downloadCover(self,url,downloadPath):
if not os.path.isdir(downloadPath):
try:
os.makedirs(downloadPath)
self.log.info("The dictionary create success")
except :
pass
bsObj = BeautifulSoup(urlopen(url),"html.parser")
content = bsObj.find("div",{"id":"subject_list"}).findAll("li",{"class":"subject-item"})
for link in content:
score = link.find("span",{"class":"rating_nums"}).text
try:
if float(score) >= 9.0 :
img = link.find("img")
bookName = link.find("a",title=re.compile("(.*)"))
self.log.info("The book's name is: " + bookName)
#下载图片
urlretrieve(img,downloadPath+'%s.jpg' % bookName.encode('utf-8'))
self.log.info("%s's cover is downloaded...." % bookName)
except Exception as e:
self.log.warn("This page have no book,Bye........\n" + e.message)
finally:
pass点击BeautifulSoup可以参考它的具体用法。
在这里只解释一行代码:
content = bsObj.find("div",{"id":"subject_list"}).findAll("li",{"class":"subject-item"})
"""
BeautifulSoup可以通过id属性和class属性的值,轻松区分出不同的标签。
find方法是最接近findAll的函数, 只是它并不会获得所有的匹配对象,它仅仅返回找到第一个可匹配对象。(原因在于limit参数默认为1)
方法findAll 从给定的点开始遍历整个树,并找到满足给定条件所有Tag以及NavigableString。
除了以上的方法还有更简洁的,比如 bsObj.div.findAll("img")会找出文档中第一个div标签,然后获取这个div后代里所有的img标签列表。有兴趣的朋友可以研究一下。
"""写到这里基本上算是大功告成了,剩下的就是一些边边角角的问题。可是这些边边角角的问题,却让我觉得有着巨大的价值。让我一个一个来看。
1、打印日志。
在工作中开发Hadoop的时候,有什么错误只要看后台日志,就可以很清晰的看到哪里出错了并很快就可以排除。但是工作中没有单独用过python开发程序,都是借用python。比如用python开发Spark,Hive巴拉巴拉,日志都是在config中配置的。这次单独使用python有些晕菜,不过后来看了点资料觉得还是蛮简单的。上代码:
#-*- coding:utf-8 -*-
import logging
import time
class JobLogging:
"""log module"""
def __init__(self, task_name, log_path):
self.logger = logging.getLogger(task_name)
self.level = 'DEBUG'
self.logger.setLevel(logging.DEBUG)
self.consoleHandler = logging.StreamHandler()
self.consoleHandler.setLevel(logging.DEBUG)
self.fileHandler = logging.FileHandler(filename=log_path + '/' + task_name + '.' + time.strftime('%Y%m%d') + '.log', mode='a', encoding='utf8')
self.fileHandler.setLevel(logging.DEBUG)
loggerFormatter = logging.Formatter('%(asctime)s %(levelname)s %(message)s', datefmt = '%Y-%m-%d %H:%M:%S')
self.consoleHandler.setFormatter(loggerFormatter)
self.fileHandler.setFormatter(loggerFormatter)
def get_logger(self):
if self.level == 'DEBUG':
self.logger.addHandler(self.consoleHandler)
self.logger.addHandler(self.fileHandler)
elif self.level == 'INFO':
self.logger.addHandler(self.consoleHandler)
self.logger.addHandler(self.fileHandler)
else:
self.logger.addHandler(self.consoleHandler)
self.logger.addHandler(self.fileHandler)
return self.logger
def set_level(self, level):
self.level = level
if self.level == 'DEBUG':
self.consoleHandler.setLevel(logging.DEBUG)
self.fileHandler.setLevel(logging.DEBUG)
elif self.level == 'INFO':
self.consoleHandler.setLevel(logging.INFO)
self.fileHandler.setLevel(logging.INFO)
else:
self.consoleHandler.setLevel(logging.DEBUG)
self.fileHandler.setLevel(logging.DEBUG)
if __name__ == '__main__':
myLog = JobLogging.etl_logging('mytest', '/home/sunnyin/study/python/Scripts/DouBan/logs')
# myLog.set_level('INFO')
myLogger = myLog.get_logger()
myLogger.info('info')
myLogger.debug('debug')
Python的logging模块比较强大,可以提供不同的日志级别,log4j机制是一样的。
logging的配置有两种方法。一种是采用Python代码,像我这种;另一种配置文件。说到配置文件,其他的还好,在配置flume的时候我看到就头疼,python就有点像flume,所以我果断选择了代码的方式。呃,,,见笑了,莫喷,我懒了而已。。。。
写好这个JobLogging类之后,在Client类中就可以进行实例化。
class ClientDouBan:
#实例化日志
def __init__(self, log_lev = 'INFO'):
date_today = datetime.datetime.now().date()
log_name = os.path.splitext( os.path.split( sys.argv[0])[1])[0]
log_dir = os.getenv('TASK_LOG_PATH')
if log_dir is None:
log_dir = '/home/sunnyin/study/python/Scripts/DouBan/logs'
log_dir += '/' + date_today.strftime("%Y%m%d")
if not os.path.isdir(log_dir):
try:
os.makedirs(log_dir)
except :
pass
# self.ignore_error = ignore_error
mylog = JobLogging(log_name,log_dir)
self.log = mylog.get_logger()
self.log.info("Log create success")
当执行程序之后,会在文件以及屏幕上打印这样的内容:

这就代表你的log配置生生效了。
2、编码问题
个人愚见:在爬虫过程中最麻烦的事情莫过于编码问题了。
一会gbk,一会gb2312,一会utf-8,一会unicode,一会还TMD火星文…..
不过,经历过这次之后我就很清晰很清晰了。
首先,在测试的时候不要再window环境中;
你可以选择在IPython notebook(jupyter notebook)中调试,非常方便;
最好在linux环境中调试,轻松太多。
上面说的是环境的问题,接下来只要记住这个小小的知识点,你就可以轻松很多了:
encode:encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode('gb2312'),表示将unicode编码的字符串str2转换成gb2312编码。
decode:decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode('gb2312'),表示将gb2312编码的字符串str1转换成unicode编码其中我遇到这么个问题:
urlretrieve(img,downloadPath+'%s.jpg' % bookName )这句话是为了下载封面,并把封面的名字命名为与其对应的名字。无奈怎么也不生效,并且还打印不出日志,竟然直接跳过。。。
后来将bookName 改为了 bookName.encode(‘utf-8’),OMG,好了!
3、添加请求头
网站会使用很多识别技术来防止爬虫。最好不要尝试在没有请求头之前大量的爬虫其网站,否则一定会将你的浏览器类型或者IP拉入黑名单的。
#添加请求头
session = requests.Session()
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5)AppleWebKit 537.36 (KHTML,like Gecko) Chrome','Connection':'Keep-Alive','Accept-Language':'zh-CN,zh;q=0.8','Accept-Encoding':'gzip,deflate,sdch','Accept':'*/*','Accept-Charset':'GBK,utf-8;q=0.7,*;q=0.3','Cache-Control':'max-age=0'}
req = session.get(url,headers=headers)
#print(req)
bsObj = BeautifulSoup(req.text,"html.parser")这样你就可以小玩一阵了,嗯,仅仅是一阵,因为如果不添加时间间隔的话,网站会把你的IP当作机器人IP扔入黑名单的。
4、为了一直玩下去,你可以用代理IP来处理
#添加请求头
session = requests.Session()
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5)AppleWebKit 537.36 (KHTML,like Gecko) Chrome','Connection':'Keep-Alive','Accept-Language':'zh-CN,zh;q=0.8','Accept-Encoding':'gzip,deflate,sdch','Accept':'*/*','Accept-Charset':'GBK,utf-8;q=0.7,*;q=0.3','Cache-Control':'max-age=0'}
#使用代理IP访问网站
proxies = {"http":"http://27.187.249.160:8118","http":"http://171.38.42.220:8123","http":"http://113.56.114.31:8118","http":"http://59.111.78.7:80","http":"http://54.222.213.149:8118"}
req = session.get(url,headers=headers,proxies=proxies)
#print(req)
bsObj = BeautifulSoup(req.text,"html.parser")每个知识点写的不是很详细,因为实在精力有限啊,sorry啊。以后有时间会针对每个知识点再写博客的。
请原谅小弟我的博客写作能力不是很强, 我会很用心的学习的,嗯!
如果大家对以上的内容有什么看法的话,欢迎大家随时和我交流。
最后,献上我的这个小程序的所有代码:
一个有3个py文件:
ClientDouBan.py
#*-coding=utf-8-*-
"""
为了节省自己挑选书籍的时间,所以编写了此程序
有一些模块需要不断调整、升级
"""
from urllib import urlopen
from urlparse import urlparse
from urllib import urlretrieve
from bs4 import BeautifulSoup
from JobLogging import JobLogging
import datetime
import os
import re
import sys
import requests
class ClientDouBan:
#实例化日志
def __init__(self, log_lev = 'INFO'):
date_today = datetime.datetime.now().date()
log_name = os.path.splitext( os.path.split( sys.argv[0])[1])[0]
log_dir = os.getenv('TASK_LOG_PATH')
if log_dir is None:
log_dir = '/home/sunnyin/study/python/Scripts/DouBan/logs'
log_dir += '/' + date_today.strftime("%Y%m%d")
if not os.path.isdir(log_dir):
try:
os.makedirs(log_dir)
except :
pass
# self.ignore_error = ignore_error
mylog = JobLogging(log_name,log_dir)
self.log = mylog.get_logger()
self.log.info("Log create success")
#下载相关的封面信息
def downloadCover(self,url,downloadPath):
if not os.path.isdir(downloadPath):
try:
os.makedirs(downloadPath)
self.log.info("The dictionary create success")
except :
pass
#添加请求头
session = requests.Session()
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5)AppleWebKit 537.36 (KHTML,like Gecko) Chrome','Connection':'Keep-Alive','Accept-Language':'zh-CN,zh;q=0.8','Accept-Encoding':'gzip,deflate,sdch','Accept':'*/*','Accept-Charset':'GBK,utf-8;q=0.7,*;q=0.3','Cache-Control':'max-age=0'}
#使用代理IP访问网站
proxies = {"http":"http://27.187.249.160:8118","http":"http://171.38.42.220:8123","http":"http://113.56.114.31:8118","http":"http://59.111.78.7:80","http":"http://54.222.213.149:8118"}
req = session.get(url,headers=headers,proxies=proxies)
#print(req)
#下载文件
bsObj = BeautifulSoup(req.text,"html.parser")
# print(bsObj)
try:
content = bsObj.find("div",{"id":"subject_list"}).findAll("li",{"class":"subject-item"})
for link in content:
score = link.find("span",{"class":"rating_nums"}).text
if float(score) >= 9.0 :
img = link.find("img")
img = img.attrs['src']
self.log.info("the img's url is:" + str(img))
bookName = link.find("a",title=re.compile("(.*)"))
bookName = bookName.attrs['title']
self.log.info("The book's name is: " + bookName)
#下载图片
urlretrieve(img,downloadPath+'%s.jpg' % bookName.encode('utf-8') )
self.log.info("%s's cover is downloaded...." % bookName)
except Exception as e:
self.log.warn("This page have no book,Bye........\n" + e.message)
finally:
pass
#拼出所有的链接地址
def toNextPage(self,rawUrl,tag):
pageNum = [x * 20 for x in range(100)]
rawUrlNet = urlparse(rawUrl).netloc
rawUrlScheme = urlparse(rawUrl).scheme #头
bookLinks = []
#拼出所有的链接地址
for item in pageNum:
url = rawUrlScheme+"://"+rawUrlNet+"/tag/"+tag+"?start="+str(item)+"&type=T"
bookLinks.append(url)
return bookLinks
JobLogging.py在上文给过。
downloadDouBanPicture.py
#-*-coding=utf-8-*-
from ClientDouBan import ClientDouBan
rawUrl = "https://book.douban.com"
tag = raw_input("Please enter the tag of you love: ")
downloadPath = "/home/sunnyin/study/python/Data/BookDoubanPicture/" + tag + "/"
client = ClientDouBan()
allOfUrls = client.toNextPage(rawUrl,tag)
for url in allOfUrls:
client.downloadCover(url,downloadPath)
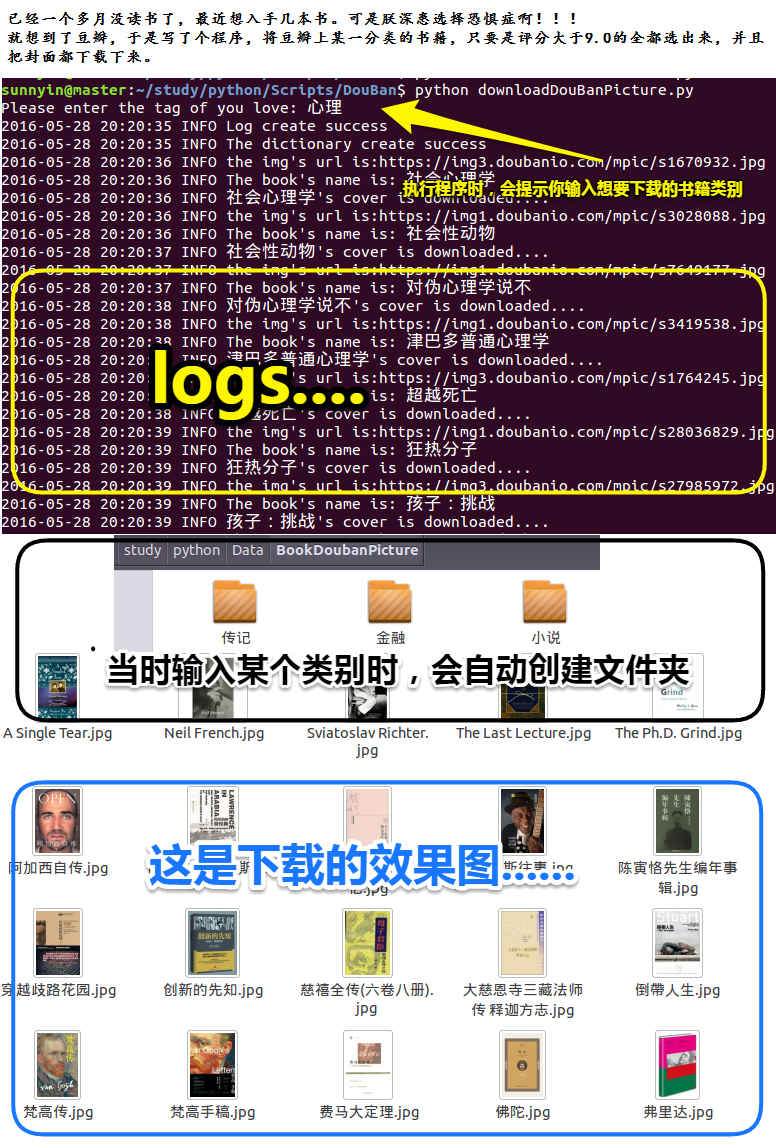
附上一张程序执行的效果图:
分享,才是最快乐的事情。爱生活,爱拉芳!














 1058
1058











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









