







慢查询日志
定位执行较慢的查询语句方案,从而决定优化

| 参数 | 说明 |
|---|---|
| slow_query_log | 开启慢查询日志 |
| slow_query_log_file | 日志位置 |
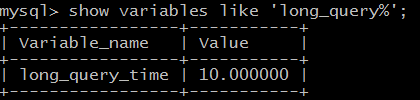
| 参数 | 说明 |
|---|---|
| long_query_time | 慢查询时间临界点/s |
--开启慢查询
set global slow_query_log = 1;
--设置临界点 0.5s
set long_query_time = 0.5;sql优化建议:
- 并发性场景下的sql
少用(不用)多表操作(subquery,join),将复杂的SQL拆分多次执行。如果查询很原子(很小),会增加查询缓存的利用率。 - 大量数据的插入
先关闭约束及索引,完成数据插入,再重新生成索引及约束。
--myisam:
--禁用索引约束
Alter table tab disable keys;
--启用
Alter table tab enable keys;
--innodb:
Drop index, drop constraint --要保留主键
Begin transaction|set autocommit=0;
--[数据本身已经按照主键值排序]
--大量的插入
Commit;
Add index, add constraint
Insert into tab values (), (), (), (), ();
--区分与每条记录的长度,以10量级为单位即可,不要过多。
--多次执行相同结构别忘了prepare预编译的执行方式。
- 分页
Limit offset, size;
Limit 的使用,会大大提升无效数据的检索(被跳过)。
应该使用条件等过滤方式,将检索到的数据尽可能精确定位到需要的数据上。
Limit size;- 获取随机字段
--Order by Rand()
select * from tab order by rand() limit 10;上面的查询,会导致每条记录都执行rand(),成本很高!应该在客户端程序通过某种运算,先确定的随机主键,从数据表中获取数据。














 380
380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









