







 在使用Spark Streaming从Kafka读取数据时,遇到'numRecords must not be negative'异常。问题源于删除并重建同名topic后,旧的offset信息导致计算出的numRecords为负数。分析发现,rdd.count()计算出的值为负,原因是new topic在无数据时,untilOffset为0,而fromOffset是旧的非零值。解决方法是在启动时校正fromOffset,当untilOffset小于fromOffset时将其置为0。
在使用Spark Streaming从Kafka读取数据时,遇到'numRecords must not be negative'异常。问题源于删除并重建同名topic后,旧的offset信息导致计算出的numRecords为负数。分析发现,rdd.count()计算出的值为负,原因是new topic在无数据时,untilOffset为0,而fromOffset是旧的非零值。解决方法是在启动时校正fromOffset,当untilOffset小于fromOffset时将其置为0。
问题描述
笔者使用spark streaming读取Kakfa中的数据,做进一步处理,用到了KafkaUtil的createDirectStream()方法;该方法不会自动保存topic partition的offset到zk,需要在代码中编写提交逻辑,此处介绍了保存offset的方法。
当删除已经使用过的kafka topic,然后新建同名topic,使用该方式时出现了"numRecords must not be negative"异常
详细信息如下图:
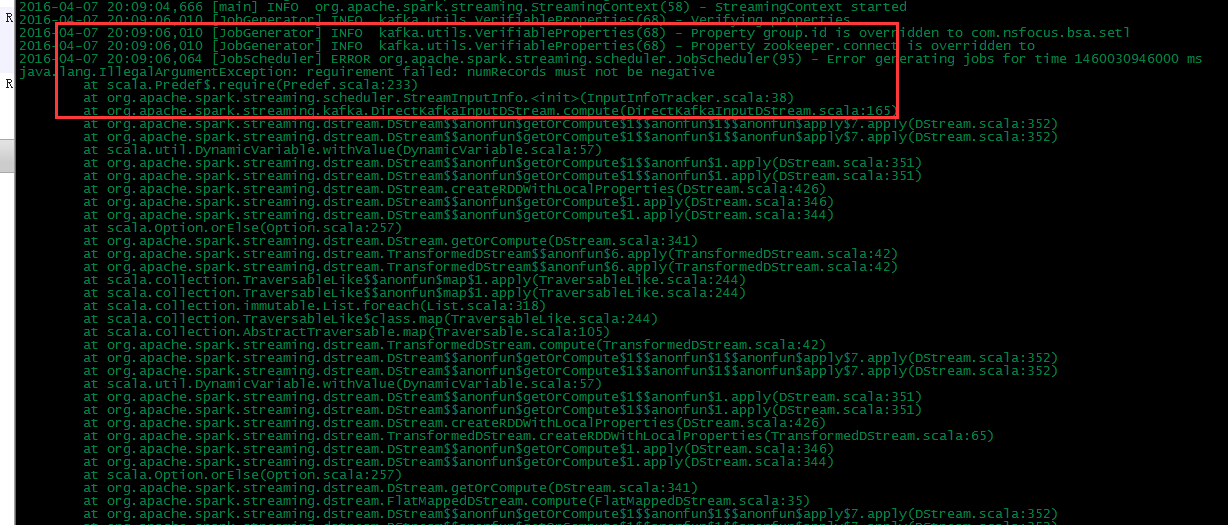
是不合法的参数异常,RDD的记录数目必须不能是负数。
下文详细分析该问题的出现的场景,以及解决方法。
异常分析
numRecords确定
首先,定位出异常出现的问题,和大致原因。异常中打印出了出现的位置 org.apache.spark.streaming.scheduler.StreamInputInfo.InputInfoTracker的第38行,此处代码:
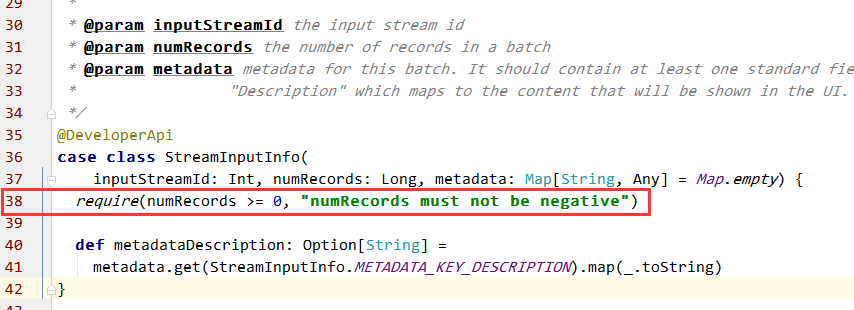
代码38行,判断了numRecords是否大于等于0,当不满足条件时抛出异常,可判断此时numRecords<0。
numRecords的解释:
numRecords: the number of records in a batch
应该是当前rdd中records 数目计算出了问题。
numRecords 构造StreamInputInfo时的参数,结合异常中的信息,找到了DirectKafkaInputDStream中的构造InputInfo的位置:
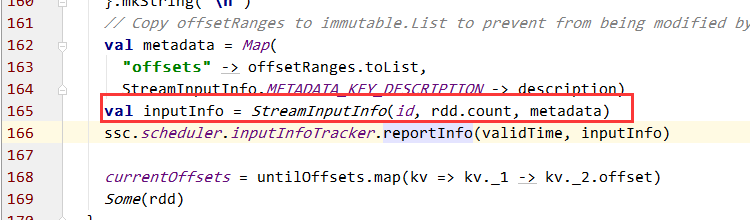
可知 numRecords是rdd.count()的值。
rdd.count的计算
根据以上分析可知rdd.count()值为负值,因此需要分析rdd的是如何生成的。
同样在DirectKafkaInputDStream中找到rdd的生成代码:

从此处一路跟踪代码,可在KafkaRDD.scala中找到rdd.count的赋值逻辑:
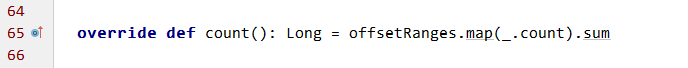
offsetRanges的计算逻辑
offsetRanges的定义
offsetRanges: offset ranges that define the Kafka data belonging to this RDD
在KafkaRDDPartition 40行找到kafka partition offsetRange的计算逻辑:
def count(): Long = untilOffset - fromOffset
fromOffset: per-topic/partition Kafka offset defining the (inclusive) starting point of the batch
untilOffset: per-topic/partition Kafka offset defining the (inclusive) ending point of the batch
fromOffset来自zk中保存;
untilOffset通过DirectKafkaInputDStream第145行:
val untilOffsets = clamp(latestLeaderOffsets(maxRetries))
计算得到,计算过程得到最新的offset,然后使用spark.streaming.kafka.maxRatePerPartition做clamp,得到允许的最大untilOffsets,##而此时新建的topic,如果topic中没有数据,untilOffsets应该为0##
原因总结
当删除一个topic时,zk中的offset信息并没有被清除,因此KafkaDirectStreaming再次启动时仍会得到旧的topic offset为old_offset,作为fromOffset。
当新建了topic后,使用untiloffset计算逻辑,得到untilOffset为0(如果topic已有数据则>0);
再次被启动的KafkaDirectStreaming Job通过异常的计算逻辑得到的rdd numRecords值为可计算为:
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2809
2809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









