







正式进入机器学习啦,这节课还好,意外知道了庄家与赔率的计算(原来庄家真的是稳赚不赔呢,楼主表示很想设赌局去做庄);python库好强大,Pandas包直接提供数据读取和处理,Fuzzywuzzy支持字符串模糊查找,可用于字符串纠错;知道了机器学习处理的大概流程;之前了解过主成分分析PCA,所以这块表示没有那么难,从方差的角度去理解PCA,简单介绍PCA和SVD的区别;最后知道对原始数据可以用one-hot编码便于后面的模型选择处理。
1、庄家与赔率
我们举例来说明:比如张恒和张顺进行比赛,宋江开赌场坐庄,规定:张恒赢赔率为1.25,张顺赢赔率为5,假定不存在平局,已知张恒赢概率为0.8,张顺赢概率为0.2。
假定所有赌徒中,共有a元买张恒,b元买张顺,则开场前宋江收入:a+b
开赛后的赔付期望:0.8*1.25*a+0.2*5*b=a+b
从上述结论可知,如果使用
1p
作为赔率(公平赔率),庄家不赔不赚,没有任何利润,这肯定是庄家不期望看到的。实际问题中,庄家总是会将公平赔率乘以一个小于1的系数(具体多少宋江肯定不会透露的)。
2、数据读取、字符串模糊查找
Python提供了强大的包,直接用于各种数据读取,比如pandas,比如读取excel数据,直接:
import pandas as pd
data = pd.read_excel('sales.xlsx', sheetname='sheet1', header=0)另外,Python还提供了Fuzzywuzzy,可用于模糊查询和替换。如果提供对应的字符串库,则通过Fuzzywuzzy用于查找和替换给定文本中错误的字符串。比如直接计算两个字符串的编辑距离:
from fuzzywuzzy import fuzz
print fuzz.ratio('Python Package', 'PythonPackage')3、数据处理流程
机器学习的基本流程:数据读取–>数据清理–>特征选择–>模型选择–>模型调优。
数据读取:直接调用Python提供的包即可。
数据清理:一般数据中不可避免的有噪声,需要想办法对数据进行清洗。比如下图中的异常值:
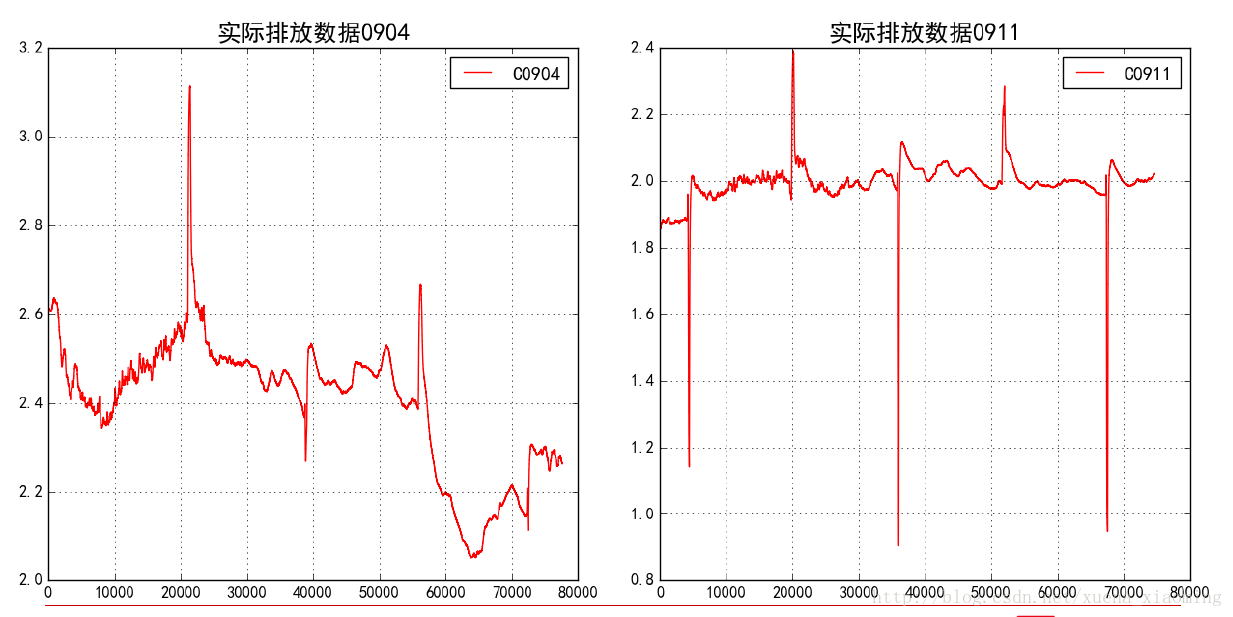
就需要在读取数据后,找到异常值,并进行清洗,将异常值尽可能恢复成正常值。
异常值检测方式比较多样,比如最简单的,直接设定阈值,当变化超过指定阈值即为异常值。校正则直接使用sklearn中的DecisionTreeRegressor和BaggingRegressor即可。
检测部分代码:
width = 500
delta = 10
eps = 0.15#异常值门限
N = len(x)
p = []
abnormal = []
for i in np.arange(0, N-width, delta):
s = x[i:i+width]
p.append(np.ptp(s))
if np.ptp(s) > eps:
abnormal.append(range(i, i+width))
abnormal = np.array(abnormal).flatten()
abnormal = np.unique(abnormal)校正部分代码:
select = np.ones(N, dtype=np.bool)
select[abnormal] = False
t = np.arange(N)
dtr = DecisionTreeRegressor(criterion='mse', max_depth=10)
br = BaggingRegressor(dtr, n_estimators=10, max_samples=0.3)
br.fit(t[select].reshape(-1, 1), x[select])
y = br.predict(np.arange(N).reshape(-1, 1))
y[select] = x[select]
plt.plot(x, 'g--', lw=1, label=u'原始值') # 原始值
plt.plot(y, 'r-', lw=1, label=u'校正值') # 校正值
plt.legend(loc='upper right')
plt.title(u'异常值校正', fontsize=18)
plt.grid(b=True)以上述中的图一为例,进行异常检测和校正如下:
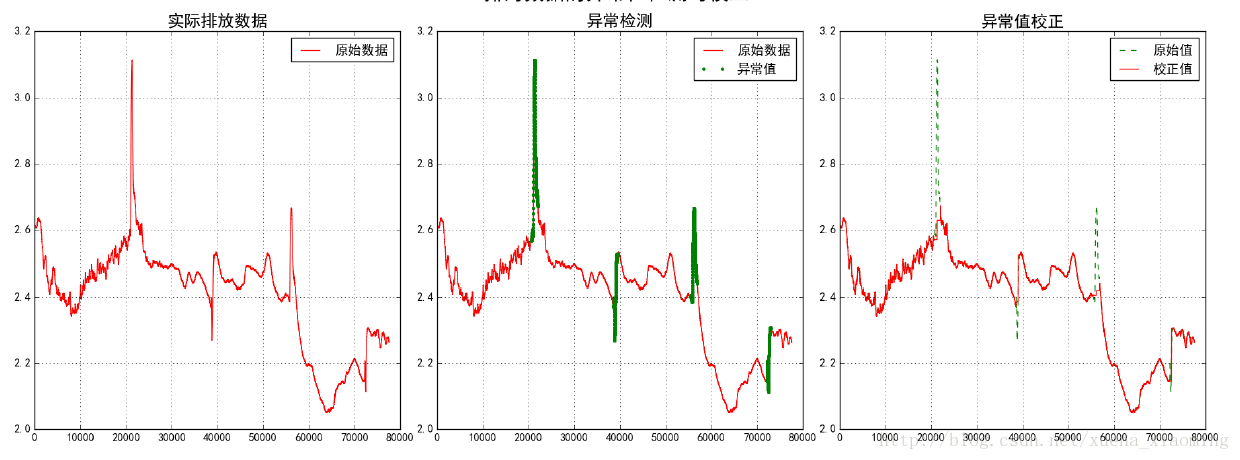
4、PCA
特征选择的一个经典算法就是PCA(Principal Component Analysis),PCA是一种常用的数据分析方法。PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降维。关于PCA的数学解释,感觉这里写链接内容讲解的比较清晰易懂。这里我们用方差的方式来理解PCA的降维。
具体思路:寻找样本的主方向u。将m个样本投影到直线l上,得到m个位于直线l上的点,计算m个投影点的方差,认为方差最大的直线方向就是主方向(若m个样本投影到一个点上,则信息基本全部损失;差距越大,损失越小,越接近原始值)。
推导:直线l的延伸方向为u,则m个样本的n个属性组成的矩阵A在l上的投影为Au。对应方差为:
Var(Au)=
(Au−E)T(Au−E)
由于假定已经做过中心化(均值为0),则上述方差等价于:
(Au)T(Au)
于是目标等价于:J(u)=
(Au)T(Au)
=
uTATAu
这里u是单位阵,使用拉格朗日乘子法:
J(u)=uTATAu−λ(uTu−1)
(u为单位阵,则
uTu
为1,后面这项恒为0)
使目标函数J(u)最小,则对其求导:
∂J(u)∂u=2ATAu−2λu=0
则
ATAu=λu
这里
λ
是
ATA
的特征值,对应的u是其特征向量。
综上,PCA的过程可总结如下:
1)归一化:也即中心化,处理后的均值为0
2)求出协方差矩阵
ATA
3)求出协方差矩阵的特征值及对应的特征向量
4)将特征向量按对应特征值从大到小按行排列成矩阵,取前k行组成矩阵P
5)Y=PX即为降维到k维后的数据
写到这里,忽然有个疑问:前一节我们提到过SVD的功能也是进行降维,那么PCA和SVD有什么区别呢?PCA主要是通过计算协方差矩阵C的特征值和特征向量进行降维的,当矩阵A(m行n列)的行和列差距特别大时,比如n远远大于m,那么其协方差矩阵C(n*n)将特别大,计算起来复杂度极高。而SVD是通过奇异值分解进行获取的,将矩阵A分解为 A=uΣvT ,其计算复杂度明显低于PCA。并且 ATA=vΣ2vT , AAT=uΣ2uT ,PCA可以理解为SVD的一个方向。
5、one-hot编码
有些直观的样本,其属性我们没法直接利用,比如性别男女,如果男为1,女为2,那么对于计算出来的参数因子,如果男的参数因子为2,女的参数因子为1,就相当于你要娶一个24岁的姑娘,我可以用两个12岁的替代么。
此时,就需要对属性特征进行编码,在不影响参数因子和相乘结果的情况下进行编码。常用的编码方式是one-hot编码。所谓one-hot编码,简单直观的理解如下图所示:
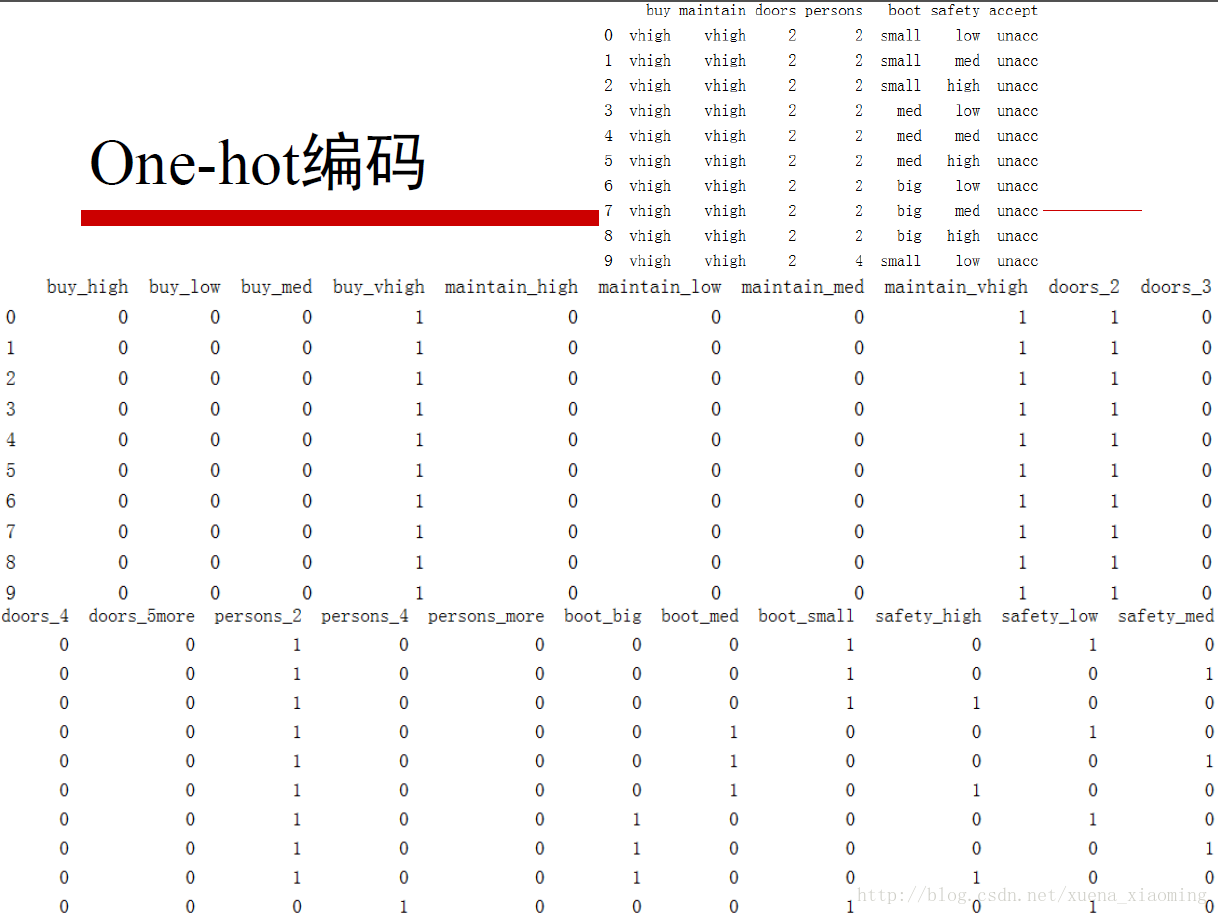
对应位置有值,则为1,否则为0,这样和参数因子相乘不影响任何结果。














 895
895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









