









1.与用户互动
1.主类的main方法是由JVM直接通过类名调用,不会先创建主类的对象,然后通过对象来调用该主方法。
2.Java可以使用Scanner可以接受文件,输入流,字符串作为数据源,Scanner设置分隔符可以使用useDelimiter方法。
代码例子:
public class ScannerKeyBoardTest
{
public static void main(String[] args)
{
//System.in代表标准输入,就是键盘输入
Scanner sc = new Scanner(System.in);
//增加下面一行将只把回车作为分隔符
//sc.useDelimiter("\n");
//判断是否还有下一个输入项
while(sc.hasNext())
{
//输出输入项
System.out.println("键盘输入的内容是:"
+ sc.next());
}
}
}
3.也可以使用BufferedReader获取键盘输入,它是JavaIO流中的一个字符,包装流,它必须建立在另一个字符流的基础上。
代码例子:
public class KeyboardInTest
{
public static void main(String[] args)
throws Exception
{
//以System.in节点流为基础,创建一个BufferedReader对象
BufferedReader br = new BufferedReader(
new InputStreamReader(System.in));
String line = null;
//逐行读取键盘输入
while ((line = br.readLine()) != null)
{
System.out.println("用户键盘输入是:" + line);
}
}
}
2.系统相关
1.加载文件和动态链接库主要对native方法有用,对于一些特殊的功能(如访问操作系统底层硬件设备等)java程序无法实现,必须借助C语言来完成,此时需要使用C语言为Java方法提供实现。
- Java程序中声明native()方法,类似于abstract方法,只有方法签名,没有实现,编译该Java程序,生成一个class文件。
- 用javah编译第1步生成的class文件,将产生一个.h文件。
- 写一个.cpp文件实现native方法,其中需要包含第2步产生的.h文件(.h文件中又包含了JDK带的jni.h文件。)
- 将第3步的.cpp文件编译成动态链接库文件。
- 在Java中庸System类的loadLibrary()方法或Runtime类的loadLibrary()方法加载第4步产生的动态链接库文件,Java程序中就可以调用这个native()方法了。
2.System类的identityHashCode()方法与HashCode方法区别:当某个类的HashCode方法被重写后,该类的实例HashCode方法就不能唯一地表示该对象,由于identityHashCode方法是根据对象的地址计算得到的HashCode值,所以可以用于来绝对判断对象是否是同一个。
代码例子:
public class IdentityHashCodeTest
{
public static void main(String[] args)
{
//下面程序中s1和s2是两个不同对象
String s1 = new String("Hello");
String s2 = new String("Hello");
//String重写了hashCode方法——改为根据字符序列计算hashCode值,
//因为s1和s2的字符序列相同,所以它们的hashCode方法返回值相同
System.out.println(s1.hashCode()
+ "----" + s2.hashCode());
//s1和s2是不同的字符串对象,所以它们的identityHashCode值不同
System.out.println(System.identityHashCode(s1)
+ "----" + System.identityHashCode(s2));
String s3 = "Java";
String s4 = "Java";
//s3和s4是相同的字符串对象,所以它们的identityHashCode值相同
System.out.println(System.identityHashCode(s3)
+ "----" + System.identityHashCode(s4));
}
}
3.常用类
1.自定义类实现”克隆”的步骤如下:
- 自定义类实现Cloneable接口,这是一个标记性的接口,实现该接口的对象可以实现”自我克隆”,接口里没有定义任何方法。
- 自定义类实现自己的clone()方法。
- 实现clone()方法时通过super.clone():调用Object实现的clone()方法来得到该对象的副本,并返回该副本。
代码例子:
class Address
{
String detail;
public Address(String detail)
{
this.detail = detail;
}
}
// 实现Cloneable接口
class User implements Cloneable
{
int age;
Address address;
public User(int age)
{
this.age = age;
address = new Address("广州天河");
}
// 通过调用super.clone()来实现clone()方法
public User clone()
throws CloneNotSupportedException
{
return (User)super.clone();
}
}
public class CloneTest
{
public static void main(String[] args)
throws CloneNotSupportedException
{
User u1 = new User(29);
// clone得到u1对象的副本。
User u2 = u1.clone();
// 判断u1、u2是否相同
System.out.println(u1 == u2); //①
// 判断u1、u2的address是否相同
System.out.println(u1.address == u2.address); //②
}
}运行结果:
false
true
从运行结果可以看出,Object类的clone()方法是一种”浅克隆”——它只克隆该对象的所有Field值,不会对引用类型的Field值所引用的对象进行克隆。我画个图表示上面的内存储存示意图:
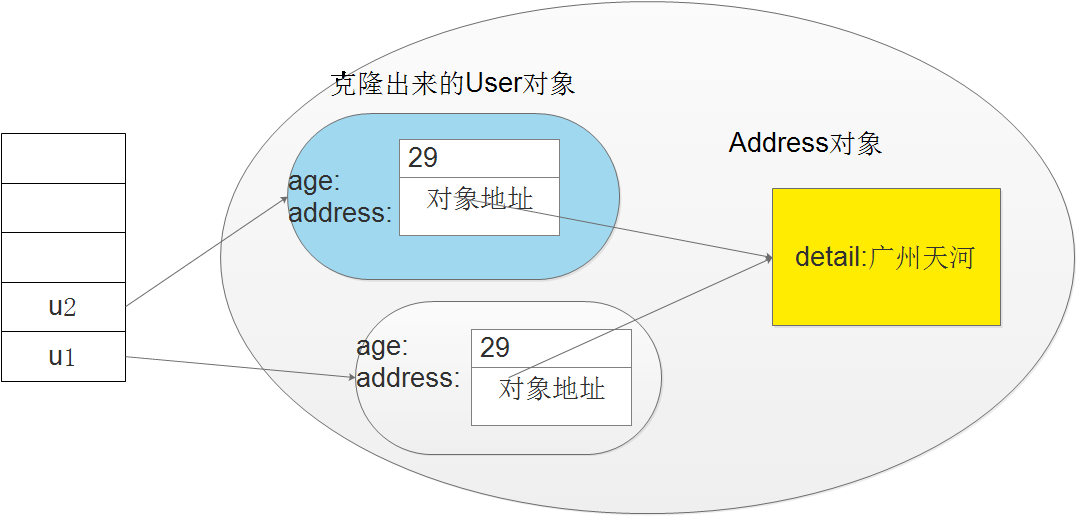
如果要进行对对象深克隆,可以用递归的方式进行克隆,这样保证所有引用类型的Field值所引用的对象都被复制了。
代码例子:
class Address implements Cloneable
{
String detail;
public Address(String detail)
{
this.detail = detail;
}
@Override
protected Address clone() throws CloneNotSupportedException
{
return (Address)super.clone();
}
}
// 实现Cloneable接口
class User implements Cloneable
{
int age;
Address address;
public User(int age)
{
this.age = age;
address = new Address("广州天河");
}
// 通过调用super.clone()来实现clone()方法
public User clone() throws CloneNotSupportedException
{
User user=null;
user=(User)super.clone();
if(this.address!=null)
{
user.address=this.address.clone();
}
return user;
}
}
public class CloneTest
{
public static void main(String[] args) throws CloneNotSupportedException
{
User u1 = new User(29);
// clone得到u1对象的副本。
User u2 = u1.clone();
// 判断u1、u2是否相同
System.out.println(u1 == u2); //①
// 判断u1、u2的address是否相同
System.out.println(u1.address == u2.address); //②
}
}运行结果:
false
false
从结果看,和上面的浅复制的不同,这里进行了深复制,故引用成员变量的所引用的对象不再是同一个。其示意图:
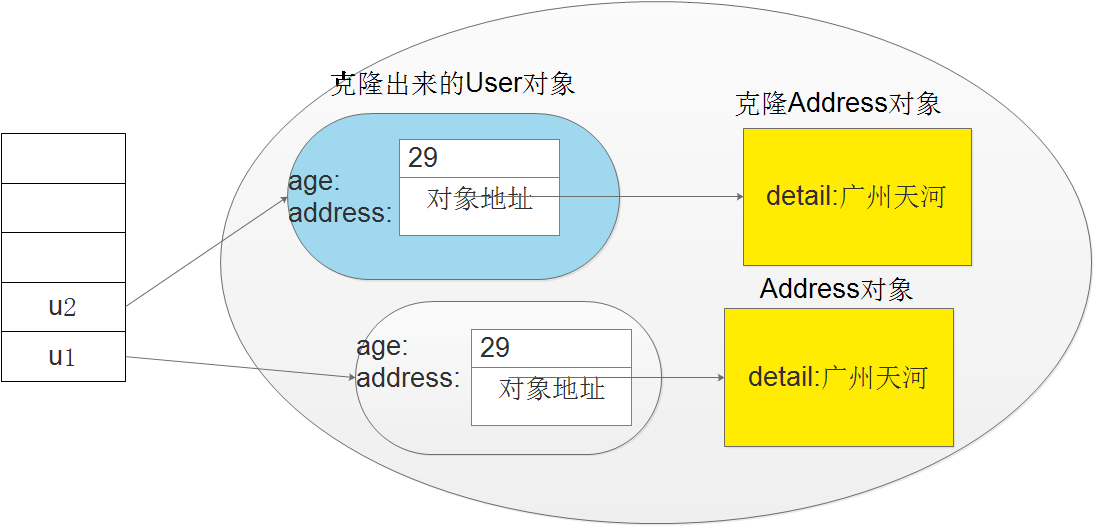
2.StringBuffer是线程安全的,而StringBuilder则没有实现线程安全功能,所以性能略高。
3.Random使用一个48位的种子,如果这个类的两个实例时用同一个种子创建的,对它们以同样的顺序调用方法,则它们会产生相同的数字序列。
代码例子:
public class Test
{
public static void main(String[] args)
{
Random r1 = new Random(50);
System.out.println("第一个种子为50的Random对象");
System.out.println("r1.nextBoolean():\t" + r1.nextBoolean());
System.out.println("r1.nextInt():\t\t" + r1.nextInt());
System.out.println("r1.nextDouble():\t" + r1.nextDouble());
System.out.println("r1.nextGaussian():\t" + r1.nextGaussian());
Random r2 = new Random(50);
System.out.println("第二个种子为50的Random对象");
System.out.println("r2.nextBoolean():\t" + r2.nextBoolean());
System.out.println("r2.nextInt():\t\t" + r2.nextInt());
System.out.println("r2.nextDouble():\t" + r2.nextDouble());
System.out.println("r2.nextGaussian():\t" + r2.nextGaussian());
Random r3 = new Random(100);
System.out.println("种子为100的Random对象");
System.out.println("r3.nextBoolean():\t" + r3.nextBoolean());
System.out.println("r3.nextInt():\t\t" + r3.nextInt());
System.out.println("r3.nextDouble():\t" + r3.nextDouble());
System.out.println("r3.nextGaussian():\t" + r3.nextGaussian());
}
}
运行结果:
第一个种子为50的Random对象
r1.nextBoolean(): true
r1.nextInt(): -1727040520
r1.nextDouble(): 0.6141579720626675
r1.nextGaussian(): 2.377650302287946
第二个种子为50的Random对象
r2.nextBoolean(): true
r2.nextInt(): -1727040520
r2.nextDouble(): 0.6141579720626675
r2.nextGaussian(): 2.377650302287946
种子为100的Random对象
r3.nextBoolean(): true
r3.nextInt(): -1139614796
r3.nextDouble(): 0.19497605734770518
r3.nextGaussian(): 0.6762208162903859
4.当进行精确的浮点数运算时,不要使用BigDecimal类的BigDecimal(double val)构造器,而应该使用BigDecimal类的BigDecimal(String val)构造器或不要使用BigDecimal类的BigDecimal.valueOf(double val)静态方法进行运算。
代码例子:
public class BigDecimalTest
{
public static void main(String[] args)
{
BigDecimal f1 = new BigDecimal("0.05");
BigDecimal f2 = BigDecimal.valueOf(0.01);
BigDecimal f3 = new BigDecimal(0.05);
System.out.println("使用String作为BigDecimal构造器参数:");
System.out.println("0.05 + 0.01 = " + f1.add(f2));
System.out.println("0.05 - 0.01 = " + f1.subtract(f2));
System.out.println("0.05 * 0.01 = " + f1.multiply(f2));
System.out.println("0.05 / 0.01 = " + f1.divide(f2));
System.out.println("使用double作为BigDecimal构造器参数:");
System.out.println("0.05 + 0.01 = " + f3.add(f2));
System.out.println("0.05 - 0.01 = " + f3.subtract(f2));
System.out.println("0.05 * 0.01 = " + f3.multiply(f2));
System.out.println("0.05 / 0.01 = " + f3.divide(f2));
}
}
运行结果:
使用String作为BigDecimal构造器参数:
0.05 + 0.01 = 0.06
0.05 - 0.01 = 0.04
0.05 * 0.01 = 0.0005
0.05 / 0.01 = 5
使用double作为BigDecimal构造器参数:
0.05 + 0.01 = 0.06000000000000000277555756156289135105907917022705078125
0.05 - 0.01 = 0.04000000000000000277555756156289135105907917022705078125
0.05 * 0.01 = 0.0005000000000000000277555756156289135105907917022705078125
0.05 / 0.01 = 5.000000000000000277555756156289135105907917022705078125
4.处理日期类
1.Calendar的add方法与roll方法的区别:add方法加上amount后超过了该字段所能表示的最大范围时,会向上一级字段增大,而roll方法不会,不过这两种方法对下一级字段都会修正到变化最小的值。
代码例子:
//测试add方法上一字段
Calendar call=Calendar.getInstance();
//2003-8-23
call.set(2003,7,23,0,0,0);
//2003-8-23=>2004-2-23
call.add(MONTH,6);
//测试add方法下一字段
Calendar call2=Calendar.getInstance();
//2003-8-31
call.set(2003,7,31,0,0,0);
//2003-8-23=>2004-2-29
call.add(MONTH,6);
//测试roll方法上一字段
Calendar call3=Calendar.getInstance();
//2003-8-23
call.set(2003,7,23,0,0,0);
//2003-8-23=>2003-2-23
call.add(MONTH,6);
//测试roll方法下一字段
Calendar call4=Calendar.getInstance();
//2003-8-31
call.set(2003,7,31,0,0,0);
//2003-8-23=>2004-2-29
call.add(MONTH,6);5.正则表达式
1.正则表达式中的特殊字符

2.预定义字符

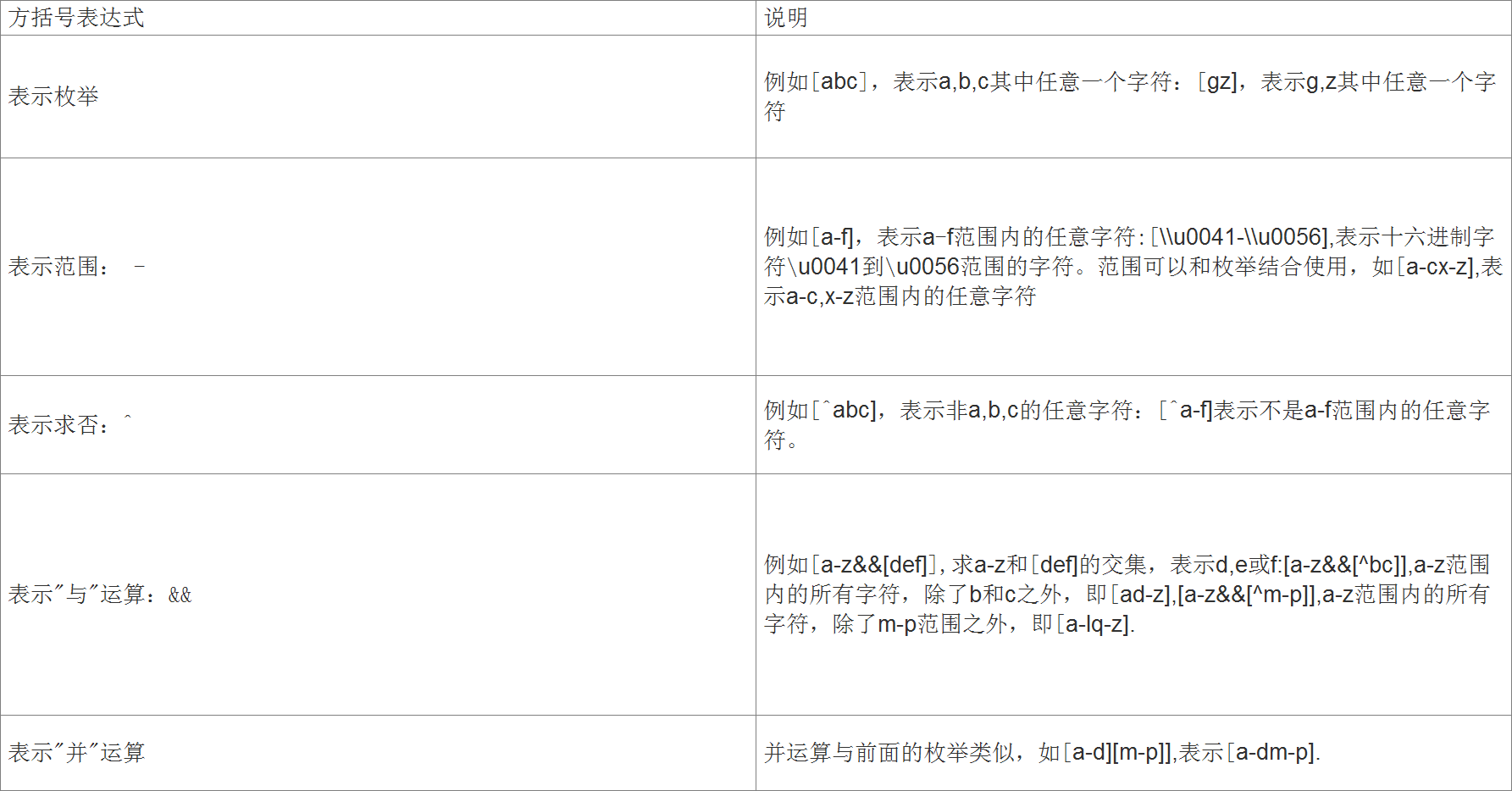
3.方括号表达式
4.边界表达式

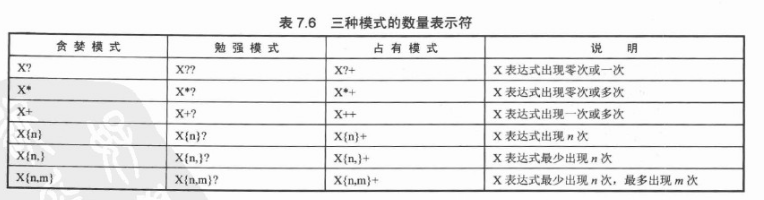
5.正则表达式支持的数量标识符有三种模式:
- Greedy(贪婪模式):数量表示符默认采用贪婪模式,除非另有表示,贪婪模式的表达式会一直匹配下去,直到无法匹配为止。
- Reluctant(勉强模式):用问号后缀(?)表示,它只会匹配最少的字符,也称为最小匹配模式。
- Possessive(占有模式):用加号后缀(+)表示。
如图:
代码例子:
public class Test
{
public static void main(String[] args)
{
String string="beyondboy ,scau";
//贪婪模式的正则表达式
System.out.println(string.replaceFirst("\\w*", "sungirl"));
//勉强模式的正则表达式
System.out.println(string.replaceFirst("\\w*?", "sungirl"));
}
}
运行结果:
sungirl ,scau
sungirlbeyondboy ,scau
6.Pattern是不可变类,可以用多个Matcher对象可共享同一个Pattern对象,并且可以使多个并发线程安全使用。
7.正则表达式的match方法和lookingAt方法区别:matches方法要求整个字符串和Pattern完全匹配时才返回true,而lookingAt只要字符串以Pattern开头就会返回true。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









