







单层非监督学习网络分析
转自:http://blog.csdn.net/zouxy09
本文的论文来自:
An Analysis of Single-Layer Networks in Unsupervised Feature Learning, Adam Coates, Honglak Lee, and Andrew Y. Ng. In AISTATS 14, 2011。在其论文的demo_code。不过我还没读。
下面是自己对其中的一些知识点的理解:
《An Analysis of Single-Layer Networks in Unsupervised Feature Learning》
最近,很多的研究都聚焦在从无标签数据中学习特征的算法,采用逐渐复杂的非监督算法和深度模型在一些基准的数据库中还得到了很好的效果。本文说明了一些简单的因素,例如模型隐层的节点数,对要达到高的性能,要比学习算法的选择或者模型的深度更重要。本文主要是针对一个隐含层的网络结构进行分析的,分别对比了4种网络结构, sparse auto-encoders、sparse RBMs 、 K-means clustering和Gaussian mixtures。本文还分析了4个影响网络性能的因素:感受野大小receptive field size、隐层节点数(或者要提取的特征数)、卷积步长(stride)和白化whitening。
最后作者得出了下面几个结论:
1、网络中隐含层神经元节点的个数(需要学习的特征数目),采集的密度(也就是convolution时的移动步伐,也就是在什么地方计算特征)和感知区域大小对最终特征提取效果的影响很大,甚至比网络的层次数,deep learning学习算法本身还要重要。
2、Whitening在预处理过程中还是很有必要的。
3、如果不考虑非监督学习算法的选择的话,whitening、 large numbers of features和small stride都会得到更好的性能。
4、在以上4种实验算法中,k-means效果竟然最好。因此在最后作者给出结论时的建议是,尽量使用whitening对数据进行预处理,每一层训练更多的特征数,采用更密集的方法对数据进行采样。
一、概述
很多特征学习系统的一个主要缺点就是他们的复杂度和开销。另外,还需要调整很多参数(hyper-parameters)。比如说学习速率learning rates、动量momentum(好像rbm中需要用到)、稀疏度惩罚系数sparsity penalties和权值衰减系数weight decay等。而这些参数最终的确定需要通过交叉验证获得,本身这样的结构训练起来所用时间就长,这么多参数要用交叉验证来获取时间就更多了。所以本文得出的结论用kmeans效果那么好,且无需有这些参数要考虑。(对于k-means的分析,见“Deep Learning论文笔记之(一)K-means特征学习”)。
二、非监督特征学习框架:
1、通过以下步骤去学习一个特征表达:
1)从无便签的训练图像中随机提取一些小的patches;
2)对这些patches做预处理(每个patch都减去均值,也就是减去直流分量,并且除以标准差,以归一化。对于图像来说,分别相当于局部亮度和对比度归一化。然后还需要经过白化);
3)用非监督学习算法来学习特征映射,也就是输入到特征的映射函数。
2、学习到特征映射函数后,给定一个有标签的训练图像集,我们用学习到的特征映射函数,对其进行特征提取,然后用来训练分类器:
1)对一个图像,用上面学习到的特征来卷积图像的每一个sub-patches,得到该输入图像的特征;
2)将上面得到的卷积特征图进行pooling,减少特征数,同时得到平移等不变性;
3)用上面得到的特征,和对应的标签来训练一个线性分类器,然后在给定新的输入时,预测器标签。
三、特征学习:
对数据进行预处理后,就可以通过非监督学习算法去学习特征了。我们可以把非监督学习算法看成一个黑盒子。它接受输入,然后产生一个输出。可以表示为一个函数f:RN->RK,把一个N维的输入向量x(i)映射为一个K维的特征向量。在这里,我们对比分析了四种不同的非监督学习算法:
1)sparse auto-encoders
我们用BP去训练一个K个隐藏节点的自动编码机,代价函数是重构均方误差,并存在一个惩罚项。主要限制隐藏节点,使其保持一个低的激活值。算法输出一个权值矩阵W(KxN维)和一组基B(K维),特征映射函数为:f(x)=g(Wx+b)。这里g(z)=1/(1+exp(-z))是sigmoid函数,对向量z的每个元素求值。
在这里,存在很多参数需要调整,例如权值衰减系数和目标激活值。针对特定的感受野大小,这些参数需要通过交叉验证方法来选择。
2)sparse restricted Boltzmann machine
RBM是一个无向图模型,包含K个二值隐层随机变量。稀疏RBMs可以通过contrastive divergence approximation(对比分歧近似)方法来训练。其中的稀疏惩罚项和自动编码机一样。训练模型还是输入权值矩阵W和基b,我们也可以使用和上面的自动编码机同样的特征映射函数。但它的训练方法和自动编码机是完全不一样的。
3)K-means clustering
我们用K-means聚类算法来从输入数据中学习K个聚类中心c(k)。当学习到这K个聚类中心后,我们可以有两种特征映射f的方法。第一种是标准的1-of-K,属于硬分配编码:
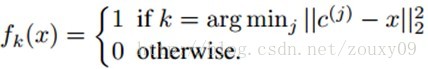
这个fk(x)表示样本x的特征向量f的第k个元素,也就是特征分量。为什么叫硬分配呢,因为一个样本只能属于某类。也就是说每个样本x对应的特征向量里面只有一个1,其他的全是0。K个类有K个中心,样本x与哪个中心欧式距离最近,其对应的位就是1,其他位全是0,属于稀疏编码的极端情况,高稀疏度啊。
第二种是采用非线性映射。属于软编码。
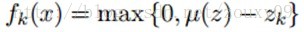
这里zk=||x-c(k)||2,u(z)是向量z的均值。也就是先计算出对应样本与k个类中心点的平均距离d,然后如果那些样本与类别中心点的距离大于d的话都设置为0,小于d的则用d与该距离之间的差来表示。这样基本能够保证一半以上的特征都变成0了,也是具有稀疏性的,且考虑了更多那些距类别中心距离比较近的值。为什么叫软分配呢。软表示这个样本以一定的概率属于这个类,它还以一定的概率属于其他的类,有点模糊聚类的感觉。而硬则表示这个样本与哪个类中心距离最近,这个样本就只属于这个类。与其他类没有任何关系。
4)Gaussian mixtures
高斯混合模型GMM用K个高斯分布的混合来描述了输入数据的密度分布。GMMs可以通过EM算法来训练。一般来说需要先运行一次K-means算法来初始化GMM的K个高斯分量。这样可以避免其陷入较差的局部最小值。这里的特征映射f把每个输入样本x映射为一个后验概率:
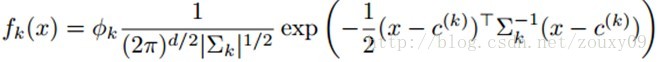
∑k是对角协方差矩阵,Φk是由EM学习得到的每个类的先验概率。其实这里和上面k-means的软分配有点像。对每个样本x都要计算其属于每一个类别j的概率。然后用这些后验概率来编码对应x的特征向量。
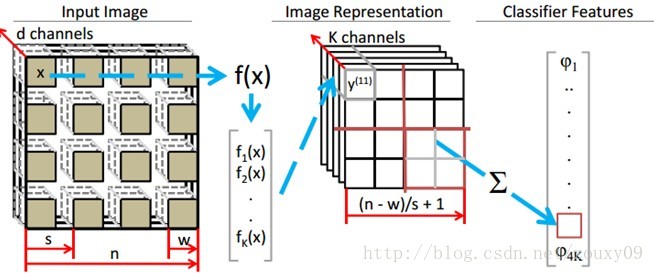
四、特征提取和分类
通过上面的步骤,我们就可以得到了将一个输入patch x(N维)映射到一个新的描述y=f(x)(K维)的函数f。这时候,我们就可以用这个特征提取器来提取有标签图像数据的特征来训练分类器了。
这里的描述到处都是,就不啰嗦了,可以参考UFLDL中的“卷积特征提取”和“池化”。
五、关于白化
对稀疏自动编码机和RBMs来说,有没有白化就显得有点随意了。当要提取的特征数较少的时候(隐层节点数少),对稀疏RBMs,白化会有点用。但如果特征数目很多,白化就显得不那么有用了。但对于聚类的算法来说,白化是一个关键的必不可少的预处理步骤,因为聚类算法对数据的相关性是盲目的。所以我们需要先通过白化来消去数据的相关性再聚类。可以看出whitening后学习到更多的细节,且whitening后几种算法都能学到类似gabor滤波器的效果,因此并不一定是deep learning的结构才可以学到这些特性。















 9160
9160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









