







一般而言,实现“读入用户输入的字符串”,程序中自然不能对用户输入的长度有所限定。这在C++中很容易实现,而在C中确没那么容易。
这一疑问,我在刚学C++的时候也在脑中闪现过;不过很快将它抛在脑后了。直到最近,我在百度知道上讨论一个单词统计问题(链接)时,才重新想起。于是,翻出gcc 4.6.1的代码,浏览了一番。
首先,明确这里探讨的场景——从标准输入(或字符模式打开的文件)中读取一个字符串(换行、空格、tab间隔均可)。用C++实现这一功能有两种选择——使用C标准库和使用C++标准库,典型代码如下(错误处理代码省略):|
| C风格 | C++风格 |
| 标准输入 | char word[16]; scanf(”%s”, word); | string word; cin >> word; |
| 文件输入(字符模式) | char word[16]; FILE* fptr = NULL; fptr = fopen(”input.txt”, ”rt”); fscanf(fptr, ”%s”, word); | string word; ifstream ifs(”input.txt”); // 默认ifsteam::in,可以不写 ifs >> word; |
(由于标准输入输出和字符模式打开的文件并无太大区别,所以下面C风格只对fscanf探讨。C++ 标准输入和文件输入原本调用的就是同一个函数。)
下面,对分别对C风格的字符串输入和C++风格的字符串输入进行探讨。
scanf读入字符串
在使用fscanf(fptr, “%s”, word);方式读入字符串时,格式串”%s”上可以加长度限定,但不是必须的。
格式串上没有长度限定时
通常,我们不会在格式串上加长度限定。但是这种写法是不安全的,比如有下面的一段程序:
#include <stdio.h>
#include <string.h>
void login()
{
int valid = 0;
char password[6] = {0};
printf("Please input password: ");
scanf("%s", password);
if( strcmp("pass", password) == 0 )
valid = 1;
if( valid ) {
printf("password correct!\n");
}
else {
printf("PASSWORD INCORRECT!\n");
}
}
int main()
{
while(1) {
login();
}
return 0;
}
这段程序模拟典型的密码验证过程。可以看看程序几次的运行结果:
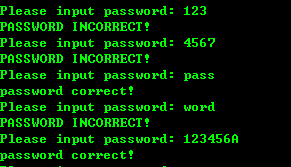
当用户输入的字符串长度小于等于6时,不会有问题。但如果长度大于6,可能会出现:1) password不正确已然能够验证成功(刚超出6);或者出现 2)程序崩溃(更长)。
为什么这么做不安全?
1)栈向下生长,所以valid,和password在login()栈帧上相邻;且password的地址更低。如下所示:
如果scanf(“%s”, password);读入的字符串是”123456A”,内存映像如下:

valid所在内存被scanf读入password时越界写入,若此时输出password,valid应分别为”123456A”, 65(’A’的ASCII值,Intel机器,小端对齐)
2)实际输入的越长,读入password时越界写入的字节数就越多。
而在多数体系结构(比如Intel机器)上,函数调用时(执行call指令)会将当前的指令指针(IA32的EIP)压栈,函数返回时(执行ret指令)会将指令指针弹出;再继续运行。一旦password越界写到该位置,函数执行ret语句后EIP将指向与调用该函数前不同的地址。通常,这个地址是个无效的值,会导致段错误。如果,你向这里写入了一个可执行的函数地址(可以是操作系统API、库函数等),顺带写入了这个函数所需的参数;这样该函数返回时就会执行另外的代码,这就是著名的“缓冲区溢出攻击”。

格式串上有长度限定时
我们习惯于在printf的格式串上加长度限定,比如printf(”%5d\n”, icount);
而scanf的格式串也是可以加长度限定的,比如scanf(”%5s”,buf);
这时又会怎样呢?可经如下代码实验之:
#include <stdio.h>
int main(int argc, char *argv[])
{
char buf[6];
while( scanf("%5s", buf) == 1 ) {
printf("scaned:%s\n", buf);
}
return 0;
}
运行如下:
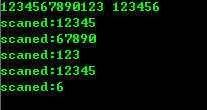
这样的写法是安全的,但并不是我们所需——读取未知长度的字符串。
比如在图片所示的测试中,用户输入的字符串是: 1234567890123和123456。而程序每次只能读取5个字符(结束符占一个,所以比缓冲小一个),它会将1234567890123截断。单从其返回后的状态并不能区分:这些截断原本是一个长的字符串,还是用户分别输入的多个独立的字符串,也就是: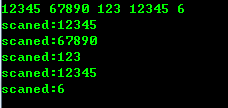
另外,这种写法存在一个隐患,即必须时刻保证:(格式串上限定的长度)≤ (实际输入缓冲长度 - 1)。实际编程时,要一直保证这一关系比较困难。尤其是缓冲的大小和格式串长度不在一个代码片段中时;这同时也给修改代码带来了不小的麻烦。
下面,来看看C++标准库是如何实现的。
operator>>()读入字符串
使用C++标准库,实现读入一个(长度未知的)字符串的代码非常简单,只需声明一个std::string str;,然后cin>>str;即可:
#include <iostream>
#include <string>
using namespace std;
// 略...
string str;
cin >> str;
这和,输入一个int,float的代码没什么两样——对程序员和用户都很友好。
对于cin >> str;可以读入任意长度的字符串(只要内存够用),就和std::string的operator+=一样,大家都司空见惯了(我也是)。直到最近,当我从会C的角度来看这个问题时,便有了标题的疑问。
(同时发现Eclipse(CDT)对运算符重载代码也能很方便的定位,只需按住Ctrl,鼠标点击你要查看的运算符即可,该opertor的定义立刻出现)
Eclipse直接定位到的是:
template<>
basic_istream<char>&
operator>>(basic_istream<char>& __is, basic_string<char>& __str);
而,该段特化版本的声明在我的gcc 4.6.1中并不能继续定位到实现。而紧邻它的泛型版的声明:
<basic_string.h>:
/**
* @brief Read stream into a string.
* @param is Input stream.
* @param str Buffer to store into.
* @return Reference to the input stream.
*
* Stores characters from @a is into @a str until whitespace is found, the
* end of the stream is encountered, or str.max_size() is reached. If
* is.width() is non-zero, that is the limit on the number of characters
* stored into @a str. Any previous contents of @a str are erased.
*/
template<typename _CharT, typename _Traits, typename _Alloc>
basic_istream<_CharT, _Traits>&
operator>>(basic_istream<_CharT, _Traits>& __is,
basic_string<_CharT, _Traits, _Alloc>& __str);
template<>
basic_istream<char>&
operator>>(basic_istream<char>& __is, basic_string<char>& __str);
可以找到实现:
<basic_string.tcc>:
| 995 996 997 998 999 1000 1001 1002 1003 1004 1005 1006 1007 1008 1009 1010 1011 1012 1013 1014 1015 1016 1017 1018 1019 1020 1021 1022 1023 1024 1025 1026 1027 1028 1029 1030 1031 1032 1033 1034 1035 1036 1037 1038 1039 1040 1041 1042 1043 1044 1045 1046 1047 1048 1049 1050 1051 1052 1053 1054 1055 1056 1057 1058 1059 1060 1061 1062 1063 1064 1065 1066 | // 21.3.7.9 basic_string::getline and operators template<typename_CharT,typename_Traits,typename_Alloc> basic_istream<_CharT,_Traits>& operator>>(basic_istream<_CharT,_Traits>&__in, basic_string<_CharT,_Traits,_Alloc>& __str) { typedef basic_istream<_CharT, _Traits> __istream_type; typedef basic_string<_CharT, _Traits, _Alloc> __string_type; typedef typename __istream_type::ios_base __ios_base; typedef typename __istream_type::int_type __int_type; typedef typename __string_type::size_type __size_type; typedef ctype<_CharT> __ctype_type; typedef typename __ctype_type::ctype_base __ctype_base;
__size_type __extracted = 0; typename __ios_base::iostate __err = __ios_base::goodbit; typename __istream_type::sentry __cerb(__in,false); if (__cerb) { __try { // Avoid reallocation for common case. __str.erase(); _CharT __buf[128]; __size_type __len = 0; const streamsize __w = __in.width(); const __size_type __n = __w > 0 ? static_cast<__size_type>(__w) : __str.max_size(); const __ctype_type& __ct = use_facet<__ctype_type>(__in.getloc()); const __int_type __eof = _Traits::eof(); __int_type __c = __in.rdbuf()->sgetc();
while (__extracted < __n && !_Traits::eq_int_type(__c, __eof) && !__ct.is(__ctype_base::space, _Traits::to_char_type(__c))) { if (__len == sizeof(__buf) / sizeof(_CharT)) { __str.append(__buf, sizeof(__buf) /sizeof(_CharT)); __len = 0; } __buf[__len++] = _Traits::to_char_type(__c); ++__extracted; __c = __in.rdbuf()->snextc(); } __str.append(__buf, __len);
if (_Traits::eq_int_type(__c, __eof)) __err |= __ios_base::eofbit; __in.width(0); } __catch(__cxxabiv1::__forced_unwind&) { __in._M_setstate(__ios_base::badbit); __throw_exception_again; } __catch(...) { // _GLIBCXX_RESOLVE_LIB_DEFECTS // 91. Description of operator>> and getline() for string<> // might cause endless loop __in._M_setstate(__ios_base::badbit); } } // 211. operator>>(istream&, string&) doesn't set failbit if (!__extracted) __err |= __ios_base::failbit; if (__err) __in.setstate(__err); return __in; } |
暂且不看错误处理,从Ln1017到Ln1045即为主要逻辑。看到1018行的__buf[]数组,我们已经能够猜出大概。
这里调用了basic_istream的一些成员函数:
width() 用于控制输入输出的宽度,相当于printf,scnaf格式串上的长度限定的作用。它有两个版本,这里都调用了。
无参数版本返回当前字段的宽度,默认情况下返回0;有参数版本用于设定当前字段宽度,这里设定为了0。
rdbuf() 返回和basic_istream相关的basic_streambuf(存放实际字符)
和streambuf的一些成员函数:
sgetc() 读取当前字符
snextc() 前进到下一位置,并读取字符
以及string的成员函数:
append() 字符串追加
此时,再看Ln1025—Ln1041就非常清楚了:
__int_type __c = __in.rdbuf()->sgetc();
while (__extracted < __n
&& !_Traits::eq_int_type(__c, __eof)
&& !__ct.is(__ctype_base::space,
_Traits::to_char_type(__c)))
{
if (__len == sizeof(__buf) / sizeof(_CharT))
{
__str.append(__buf, sizeof(__buf) / sizeof(_CharT));
__len = 0;
}
__buf[__len++] = _Traits::to_char_type(__c);
++__extracted;
__c = __in.rdbuf()->snextc();
}
__str.append(__buf, __len);
迁移到C环境
据此我们可以写出一个C语言版本的fgetvs():
// get variable length string.
char *fgetvs(FILE *stream)
{
int c;
char buf[4] = {0};
size_t len = 0;
char *str = NULL;
size_t slen = 0;
c = fgetc(stream);
while( c != EOF && !isspace(c) )
{
if(len == sizeof(buf)/sizeof(char))
{
void *old = str;
str = strapp(str, slen, buf, sizeof(buf)/sizeof(char));
slen += len;
free(old);
len = 0;
}
buf[len++] = (char)c;
c = fgetc(stream);
// printf("DEBUG: %c, %d, %s\n", c, len, buf);
}
str = strapp(str, slen, buf, len);
// slen += len;
return str;
}
这段代码使用(char*,size_t)模拟std::string,可以避免频繁调用strlen。(也可以仅用char*,每次strlen求长度)
strapp返回新字符串而不改变传入的两个字符串。
代码的难点由转移到了strapp(),正确的写出strapp也不难,完整的模拟程序代码如下:
#include <stdio.h>
#include <stdlib.h> // for malloc free
#include <assert.h> // for assert
#include <ctype.h> // for isspace
#include <string.h> // for memcpy
// string append.
static char *strapp(const char *str, size_t len,
const char *appstr, size_t applen)
{
char *pnew = NULL;
pnew = (char*)malloc( (len + applen + 1) * sizeof(char));
assert(pnew != NULL);
if(str) {
memcpy(pnew, str, len);
}
memcpy(pnew+len, appstr, applen);
pnew[len+applen] = '\0';
return pnew;
}
// get variable length string.
char *fgetvs(FILE *stream)
{
int c;
char buf[4] = {0};
size_t len = 0;
char *str = NULL;
size_t slen = 0;
c = fgetc(stream);
while( c != EOF && !isspace(c) )
{
if(len == sizeof(buf)/sizeof(char))
{
void *old = str;
str = strapp(str, slen, buf, sizeof(buf)/sizeof(char));
slen += len;
free(old);
len = 0;
}
buf[len++] = (char)c;
c = fgetc(stream);
// printf("DEBUG: %c, %d, %s\n", c, len, buf);
}
str = strapp(str, slen, buf, len);
// slen += len;
return str;
}
int main(int argc, char *argv[])
{
puts(fgetvs(stdin));
return 0;
}
getline也一样
与读取一个字符串相似的问题是——读取一行(换行符间隔),二者并无太大区别,读取字符串以空白字符(空格、TAB、换行)间隔,读取一行则只以换行间隔。
只需将上面fgetvs()代码while条件上的:
!isspace(c)
改成:
c != ‘\n’
即可实现fgetvl():
// get variable length line.
char *fgetvl(FILE *stream)
{
int c;
char buf[4] = {0};
size_t len = 0;
char *str = NULL;
size_t slen = 0;
c = fgetc(stream);
while( c != EOF && c != '\n' )
{
if(len == sizeof(buf)/sizeof(char))
{
void *old = str;
str = strapp(str, slen, buf, sizeof(buf)/sizeof(char));
strcat();
slen += len;
free(old);
len = 0;
}
buf[len++] = (char)c;
c = fgetc(stream);
// printf("DEBUG: %c, %d, %s\n", c, len, buf);
}
str = strapp(str, slen, buf, len);
// slen += len;
return str;
}
总结
为什么(未知长度的)字符串空间不能放在栈上?
上面对于scanf格式串上没有长度限定的安全性的解释已经同时回答了这个问题。C++的std::string对象本身只存放字符指针(以及缓冲长度),实际内存在堆上开辟(new/malloc申请)。我们用C模拟的版本可以很清楚的看到malloc。究其根本,其一,因为栈向低地址方向生长,而字符串通常向高地址方向写入。其二,只有函数调用栈顶的函数的栈帧可变,而该函数一旦返回,该函数栈帧上的所有内存都会被回收;在不借助堆的情况下,即便实现了在getvs栈上开辟空间,字符串向低地址方向写入;那么返回时这段空间还是会被撤销,要想保存getvs读入的字符串,必须在getvs调用前(上一栈帧)也在栈上开辟同样大小的空间;而这与“只有调用栈顶的函数的栈帧可变”向矛盾。因此,不能将变长字符串存放在栈空间上。
这一场景下体现出C++标准库的哪些好处?
个人感到的好处是string::append()。std::string实现了Buffer的功能——提供了append,insert等方法,而不需用户关心内存操作。
另一个人感到的好处是由于operator>>被重载带来的“接口一致性”,cin>>str和cin>>icount用起来差不多。















 3550
3550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











