






众所周知,在王者荣耀里面,花木兰作为一个上手难度极高的英雄,让很多喜欢玩刺客职业的玩家又爱又恨,极高的攻击再加上多个可以减速沉默击退击飞的控制技能绝对可以打出不菲的伤害,可是前期的薄血脆皮特点让不少人望而却步,所以由我这个青铜菜鸡来和大家分析一下花木兰。。。

首先我们来看一下花木兰的各个技能:
被动技能:短剑状态下连续5次攻击可以沉默并减速敌方英雄,重剑状态下,减攻速的同时增加50%的普攻伤害,而且使用技能时花木兰处于霸体状态并有50%的伤害减免。这个被动使花木兰拥有抓对面英雄的资本,短剑的减速沉默控住对方再加上重剑的高攻高防完全可以打出爆炸性伤害。
技能一:空裂斩:
短剑状态:向前冲刺挥砍,如果命中至少一个单位则5秒 内能再次使用。这是花木兰追击,逃命,赶路的技能。在使用技能命中后在滑动方向键还会有一小段位移,也就是说技能一命中后最多可以有四下攻击,所以用好技能一的话可以很快的沉默对方。
重剑状态:花木兰进行蓄力并发动挥砍,根据蓄力时间不同可以造成眩晕击飞等不同效果。短时间内可以发动两次。每次都可造成大量伤害,收人头的绝佳技能。

技能二:旋舞之华:
短剑状态:向指定方向投掷短剑,短剑在空中悬浮3秒,并对击中的英雄减速,悬浮期间花木兰拾起短剑可以减少5秒的冷却时间。这个技能算是花木兰的一个远程攻击,而且命中时至少给敌方两次攻击,对方反应慢一点的话,一个技能就能打满四个标记,在配合技能一攻击一下就可沉默对方,而且技能伤害也是不低的。

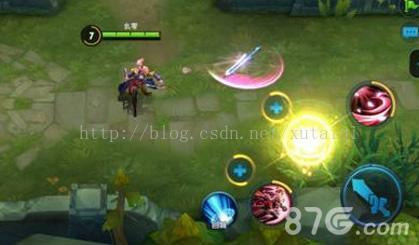
重剑状态:花木兰向前方发动四次挥砍,会击退距离较近的英雄。该技能伤害不菲,而且是花木兰的主要控制技能。

技能三:绽放刀锋:花木兰从短剑切换重剑,或从重剑切换成短剑,每次切换发动一次挥砍。从短剑切换到重剑时,挥砍之后可立即追加一次普攻。
召唤师技能:闪现(核心)

技能看完了,那我们来看一下她的连招,网友戏称:啪啪沉默杀!
首先起手时短剑技能一突进到敌方英雄位置,打出两个标记,然后用技能二再打两个标记,在用技能一打完第五下沉默对方,注意此时最好用技能一打到敌方逃跑的方向上,此时技能三换重剑并迅速平A,开技能二击退敌方四下打完后,开技能一,此时不要急,如果成功击退敌方的话,等蓄力百分之七十五后可以用闪现强制命中,打出高额伤害。
只要这一套连招完整的打下来,没有什么问题是解决不了的。。即使是防高血厚的肉盾最差也能打残血。


连招起手时技能一和技能二可以试情况改变顺序,,在不同情况下也可以将连招拆解来达到最高效率的输出和最佳的团队配合。
还有玩花木兰的核心思想,对怼的时候不要怂,千万不要怂!花木兰中后期是完全可以抗着塔收割的。技能一迅速进塔沉默后重剑的技能二时机恰当甚至可以把敌方推出塔外。
发育时4级之前不要浪,多清兵线,打野怪,迅速发育,四级之后可以开始抓对面落单英雄,有队友配合时可以去其他各路收人头带节奏,不过一定不要忘记顺便清理兵线即使发育,一旦经济落后,再发育起来难度会加大非常多的。
最后就是花木兰的缺点,除前期较脆外,单挑位移技能较多的英雄总有种力不从心的感觉,例如诸葛亮,因为沉默时间不长,连招打到最关键的重剑技能二时,会有很大的可能让对方让对方逃掉,所以除非自己经济远高于对方,最好配合队友来杀掉对方。
总而言之,对于花木兰这个出场率和胜率都非常强势的英雄,我还是非常喜欢的,同时希望大家在打农药时也多支持一下花木兰。。。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









