






摘要: 讨论常见的堆性能问题以及如何防范它们。(共 9 页)
前言
您是否是动态分配的 C/C++ 对象忠实且幸运的用户?您是否在模块间的往返通信中频繁地使用了“自动化”?您的程序是否因堆分配而运行起来很慢?不仅仅您遇到这样的问题。几乎所有项目迟早都会遇到堆问题。大家都想说,“我的代码真正好,只是堆太慢”。那只是部分正确。更深入理解堆及其用法、以及会发生什么问题,是很有用的。
什么是堆?
(如果您已经知道什么是堆,可以跳到“什么是常见的堆性能问题?”部分)
在程序中,使用堆来动态分配和释放对象。在下列情况下,调用堆操作:
事先不知道程序所需对象的数量和大小。
对象太大而不适合堆栈分配程序。
堆使用了在运行时分配给代码和堆栈的内存之外的部分内存。下图给出了堆分配程序的不同层。 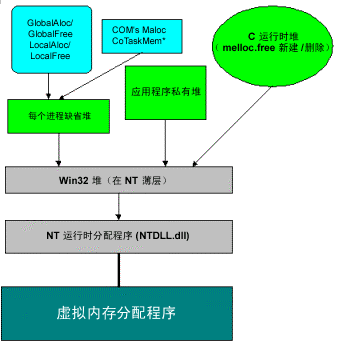
GlobalAlloc/GlobalFree:Microsoft Win32 堆调用,这些调用直接与每个进程的默认堆进行对话。
LocalAlloc/LocalFree:Win32 堆调用(为了与 Microsoft Windows NT 兼容),这些调用直接与每个进程的默认堆进行对话。
COM 的 IMalloc 分配程序(或 CoTaskMemAlloc / CoTaskMemFree):函数使用每个进程的默认堆。自动化程序使用“组件对象模型 (COM)”的分配程序,而申请的程序使用每个进程堆。
C/C++ 运行时 (CRT) 分配程序:提供了 malloc() 和 free() 以及 new 和 delete 操作符。如 Microsoft Visual Basic 和 Java 等语言也提供了新的操作符并使用垃圾收集来代替堆。CRT 创建自己的私有堆,驻留在 Win32 堆的顶部。
Windows NT 中,Win32 堆是 Windows NT 运行时分配程序周围的薄层。所有 API 转发它们的请求给 NTDLL。
Windows NT 运行时分配程序提供 Windows NT 内的核心堆分配程序。它由具有 128 个大小从 8 到 1,024 字节的空闲列表的前端分配程序组成。后端分配程序使用虚拟内存来保留和提交页。
在图表的底部是“虚拟内存分配程序”,操作系统使用它来保留和提交页。所有分配程序使用虚拟内存进行数据的存取。
分配和释放块不就那么简单吗?为何花费这么长时间?
堆实现的注意事项
传统上,操作系统和运行时库是与堆的实现共存的。在一个进程的开始,操作系统创建一个默认堆,叫做“进程堆”。如果没有其他堆可使用,则块的分配使用“进程堆”。语言运行时也能在进程内创建单独的堆。(例如,C 运行时创建它自己的堆。)除这些专用的堆外,应用程序或许多已载入的动态链接库 (DLL) 之一可以创建和使用单独的堆。Win32 提供一整套 API 来创建和使用私有堆。有关堆函数(英文)的详尽指导,请参见 MSDN。
当应用程序或 DLL 创建私有堆时,这些堆存在于进程空间,并且在进程内是可访问的。从给定堆分配的数据将在同一个堆上释放。(不能从一个堆分配而在另一个堆释放。)
在所有虚拟内存系统中,堆驻留在操作系统的“虚拟内存管理器”的顶部。语言运行时堆也驻留在虚拟内存顶部。某些情况下,这些堆是操作系统堆中的层,而语言运行时堆则通过大块的分配来执行自己的内存管理。不使用操作系统堆,而使用虚拟内存函数更利于堆的分配和块的使用。
典型的堆实现由前、后端分配程序组成。前端分配程序维持固定大小块的空闲列表。对于一次分配调用,堆尝试从前端列表找到一个自由块。如果失败,堆被迫从后端(保留和提交虚拟内存)分配一个大块来满足请求。通用的实现有每块分配的开销,这将耗费执行周期,也减少了可使用的存储空间。
Knowledge Base 文章 Q10758,“用 calloc() 和 malloc() 管理内存” (搜索文章编号), 包含了有关这些主题的更多背景知识。另外,有关堆实现和设计的详细讨论也可在下列著作中找到:“Dynamic Storage Allocation: A Survey and Critical Review”,作者 Paul R. Wilson、Mark S. Johnstone、Michael Neely 和 David Boles;“International Workshop on Memory Management”, 作者 Kinross, Scotland, UK, 1995 年 9 月( http://www.cs.utexas.edu/users/oops/papers.html)(英文)。
http://www.cs.utexas.edu/users/oops/papers.html)(英文)。
Windows NT 的实现(Windows NT 版本 4.0 和更新版本) 使用了 127 个大小从 8 到 1,024 字节的 8 字节对齐块空闲列表和一个“大块”列表。“大块”列表(空闲列表[0]) 保存大于 1,024 字节的块。空闲列表容纳了用双向链表链接在一起的对象。默认情况下,“进程堆”执行收集操作。(收集是将相邻空闲块合并成一个大块的操作。)收集耗费了额外的周期,但减少了堆块的内部碎片。
单一全局锁保护堆,防止多线程式的使用。(请参见“Server Performance and Scalability Killers”中的第一个注意事项, George Reilly 所著,在 “MSDN Online Web Workshop”上(站点:http://msdn.microsoft.com/workshop/server/iis/tencom.asp(英文)。)单一全局锁本质上是用来保护堆数据结构,防止跨多线程的随机存取。若堆操作太频繁,单一全局锁会对性能有不利的影响。
什么是常见的堆性能问题?
以下是您使用堆时会遇到的最常见问题:
分配操作造成的速度减慢。光分配就耗费很长时间。最可能导致运行速度减慢原因是空闲列表没有块,所以运行时分配程序代码会耗费周期寻找较大的空闲块,或从后端分配程序分配新块。
释放操作造成的速度减慢。释放操作耗费较多周期,主要是启用了收集操作。收集期间,每个释放操作“查找”它的相邻块,取出它们并构造成较大块,然后再把此较大块插入空闲列表。在查找期间,内存可能会随机碰到,从而导致高速缓存不能命中,性能降低。
堆竞争造成的速度减慢。当两个或多个线程同时访问数据,而且一个线程继续进行之前必须等待另一个线程完成时就发生竞争。竞争总是导致麻烦;这也是目前多处理器系统遇到的最大问题。当大量使用内存块的应用程序或 DLL 以多线程方式运行(或运行于多处理器系统上)时将导致速度减慢。单一锁定的使用—常用的解决方案—意味着使用堆的所有操作是序列化的。当等待锁定时序列化会引起线程切换上下文。可以想象交叉路口闪烁的红灯处走走停停导致的速度减慢。
竞争通常会导致线程和进程的上下文切换。上下文切换的开销是很大的,但开销更大的是数据从处理器高速缓存中丢失,以及后来线程复活时的数据重建。
堆破坏造成的速度减慢。造成堆破坏的原因是应用程序对堆块的不正确使用。通常情形包括释放已释放的堆块或使用已释放的堆块,以及块的越界重写等明显问题。(破坏不在本文讨论范围之内。有关内存重写和泄漏等其他细节,请参见 Microsoft Visual C++(R) 调试文档 。)
频繁的分配和重分配造成的速度减慢。这是使用脚本语言时非常普遍的现象。如字符串被反复分配,随重分配增长和释放。不要这样做,如果可能,尽量分配大字符串和使用缓冲区。另一种方法就是尽量少用连接操作。
竞争是在分配和释放操作中导致速度减慢的问题。理想情况下,希望使用没有竞争和快速分配/释放的堆。可惜,现在还没有这样的通用堆,也许将来会有。
在所有的服务器系统中(如 IIS、MSProxy、DatabaseStacks、网络服务器、 Exchange 和其他), 堆锁定实在是个大瓶颈。处理器数越多,竞争就越会恶化。
尽量减少堆的使用
现在您明白使用堆时存在的问题了,难道您不想拥有能解决这些问题的超级魔棒吗?我可希望有。但没有魔法能使堆运行加快—因此不要期望在产品出货之前的最后一星期能够大为改观。如果提前规划堆策略,情况将会大大好转。调整使用堆的方法,减少对堆的操作是提高性能的良方。
如何减少使用堆操作?通过利用数据结构内的位置可减少堆操作的次数。请考虑下列实例:
- struct ObjectA {
- // objectA 的数据
- }
- struct ObjectB {
- // objectB 的数据
- }
- // 同时使用 objectA 和 objectB
- //
- // 使用指针
- //
- struct ObjectB {
- struct ObjectA * pObjA;
- // objectB 的数据
- }
- //
- // 使用嵌入
- //
- struct ObjectB {
- struct ObjectA pObjA;
- // objectB 的数据
- }
- //
- // 集合 – 在另一对象内使用 objectA 和 objectB
- //
- struct ObjectX {
- struct ObjectA objA;
- struct ObjectB objB;
- }
避免使用指针关联两个数据结构。如果使用指针关联两个数据结构,前面实例中的对象 A 和 B 将被分别分配和释放。这会增加额外开销—我们要避免这种做法。
把带指针的子对象嵌入父对象。当对象中有指针时,则意味着对象中有动态元素(百分之八十)和没有引用的新位置。嵌入增加了位置从而减少了进一步分配/释放的需求。这将提高应用程序的性能。
合并小对象形成大对象(聚合)。聚合减少分配和释放的块的数量。如果有几个开发者,各自开发设计的不同部分,则最终会有许多小对象需要合并。集成的挑战就是要找到正确的聚合边界。
内联缓冲区能够满足百分之八十的需要(aka 80-20 规则)。个别情况下,需要内存缓冲区来保存字符串/二进制数据,但事先不知道总字节数。估计并内联一个大小能满足百分之八十需要的缓冲区。对剩余的百分之二十,可以分配一个新的缓冲区和指向这个缓冲区的指针。这样,就减少分配和释放调用并增加数据的位置空间,从根本上提高代码的性能。
在块中分配对象(块化)。块化是以组的方式一次分配多个对象的方法。如果对列表的项连续跟踪,例如对一个 {名称,值} 对的列表,有两种选择:选择一是为每一个“名称-值”对分配一个节点;选择二是分配一个能容纳(如五个)“名称-值”对的结构。例如,一般情况下,如果存储四对,就可减少节点的数量,如果需要额外的空间数量,则使用附加的链表指针。
块化是友好的处理器高速缓存,特别是对于 L1-高速缓存,因为它提供了增加的位置 —不用说对于块分配,很多数据块会在同一个虚拟页中。
正确使用 _amblksiz。C 运行时 (CRT) 有它的自定义前端分配程序,该分配程序从后端(Win32 堆)分配大小为 _amblksiz 的块。将 _amblksiz 设置为较高的值能潜在地减少对后端的调用次数。这只对广泛使用 CRT 的程序适用。
使用上述技术将获得的好处会因对象类型、大小及工作量而有所不同。但总能在性能和可升缩性方面有所收获。另一方面,代码会有点特殊,但如果经过深思熟虑,代码还是很容易管理的。
其他提高性能的技术
下面是一些提高速度的技术:
使用 Windows NT5 堆
由于几个同事的努力和辛勤工作,1998 年初 Microsoft Windows(R) 2000 中有了几个重大改进:
改进了堆代码内的锁定。堆代码对每堆一个锁。全局锁保护堆数据结构,防止多线程式的使用。但不幸的是,在高通信量的情况下,堆仍受困于全局锁,导致高竞争和低性能。Windows 2000 中,锁内代码的临界区将竞争的可能性减到最小,从而提高了可伸缩性。
使用 “Lookaside”列表。堆数据结构对块的所有空闲项使用了大小在 8 到 1,024 字节(以 8-字节递增)的快速高速缓存。快速高速缓存最初保护在全局锁内。现在,使用 lookaside 列表来访问这些快速高速缓存空闲列表。这些列表不要求锁定,而是使用 64 位的互锁操作,因此提高了性能。
内部数据结构算法也得到改进。
这些改进避免了对分配高速缓存的需求,但不排除其他的优化。使用 Windows NT5 堆评估您的代码;它对小于 1,024 字节 (1 KB) 的块(来自前端分配程序的块)是最佳的。GlobalAlloc() 和 LocalAlloc() 建立在同一堆上,是存取每个进程堆的通用机制。如果希望获得高的局部性能,则使用 Heap(R) API 来存取每个进程堆,或为分配操作创建自己的堆。如果需要对大块操作,也可以直接使用 VirtualAlloc() / VirtualFree() 操作。
上述改进已在 Windows 2000 beta 2 和 Windows NT 4.0 SP4 中使用。改进后,堆锁的竞争率显著降低。这使所有 Win32 堆的直接用户受益。CRT 堆建立于 Win32 堆的顶部,但它使用自己的小块堆,因而不能从 Windows NT 改进中受益。(Visual C++ 版本 6.0 也有改进的堆分配程序。)
使用分配高速缓存
分配高速缓存允许高速缓存分配的块,以便将来重用。这能够减少对进程堆(或全局堆)的分配/释放调用的次数,也允许最大限度的重用曾经分配的块。另外,分配高速缓存允许收集统计信息,以便较好地理解对象在较高层次上的使用。
典型地,自定义堆分配程序在进程堆的顶部实现。自定义堆分配程序与系统堆的行为很相似。主要的差别是它在进程堆的顶部为分配的对象提供高速缓存。高速缓存设计成一套固定大小(如 32 字节、64 字节、128 字节等)。这一个很好的策略,但这种自定义堆分配程序丢失与分配和释放的对象相关的“语义信息”。
与自定义堆分配程序相反,“分配高速缓存”作为每类分配高速缓存来实现。除能够提供自定义堆分配程序的所有好处之外,它们还能够保留大量语义信息。每个分配高速缓存处理程序与一个目标二进制对象关联。它能够使用一套参数进行初始化,这些参数表示并发级别、对象大小和保持在空闲列表中的元素的数量等。分配高速缓存处理程序对象维持自己的私有空闲实体池(不超过指定的阀值)并使用私有保护锁。合在一起,分配高速缓存和私有锁减少了与主系统堆的通信量,因而提供了增加的并发、最大限度的重用和较高的可伸缩性。
需要使用清理程序来定期检查所有分配高速缓存处理程序的活动情况并回收未用的资源。如果发现没有活动,将释放分配对象的池,从而提高性能。
可以审核每个分配/释放活动。第一级信息包括对象、分配和释放调用的总数。通过查看它们的统计信息可以得出各个对象之间的语义关系。利用以上介绍的许多技术之一,这种关系可以用来减少内存分配。
分配高速缓存也起到了调试助手的作用,帮助您跟踪没有完全清除的对象数量。通过查看动态堆栈返回踪迹和除没有清除的对象之外的签名,甚至能够找到确切的失败的调用者。
MP 堆
MP 堆是对多处理器友好的分布式分配的程序包,在 Win32 SDK(Windows NT 4.0 和更新版本)中可以得到。最初由 JVert 实现,此处堆抽象建立在 Win32 堆程序包的顶部。MP 堆创建多个 Win32 堆,并试图将分配调用分布到不同堆,以减少在所有单一锁上的竞争。
本程序包是好的步骤 —一种改进的 MP-友好的自定义堆分配程序。但是,它不提供语义信息和缺乏统计功能。通常将 MP 堆作为 SDK 库来使用。如果使用这个 SDK 创建可重用组件,您将大大受益。但是,如果在每个 DLL 中建立这个 SDK 库,将增加工作设置。
重新思考算法和数据结构
要在多处理器机器上伸缩,则算法、实现、数据结构和硬件必须动态伸缩。请看最经常分配和释放的数据结构。试问,“我能用不同的数据结构完成此工作吗?”例如,如果在应用程序初始化时加载了只读项的列表,这个列表不必是线性链接的列表。如果是动态分配的数组就非常好。动态分配的数组将减少内存中的堆块和碎片,从而增强性能。
减少需要的小对象的数量减少堆分配程序的负载。例如,我们在服务器的关键处理路径上使用五个不同的对象,每个对象单独分配和释放。一起高速缓存这些对象,把堆调用从五个减少到一个,显著减少了堆的负载,特别当每秒钟处理 1,000 个以上的请求时。
如果大量使用“Automation”结构,请考虑从主线代码中删除“Automation BSTR”,或至少避免重复的 BSTR 操作。(BSTR 连接导致过多的重分配和分配/释放操作。)
摘要
对所有平台往往都存在堆实现,因此有巨大的开销。每个单独代码都有特定的要求,但设计能采用本文讨论的基本理论来减少堆之间的相互作用。
评价您的代码中堆的使用。
改进您的代码,以使用较少的堆调用:分析关键路径和固定数据结构。
在实现自定义的包装程序之前使用量化堆调用成本的方法。
如果对性能不满意,请要求 OS 组改进堆。更多这类请求意味着对改进堆的更多关注。
要求 C 运行时组针对 OS 所提供的堆制作小巧的分配包装程序。随着 OS 堆的改进,C 运行时堆调用的成本将减小。
操作系统(Windows NT 家族)正在不断改进堆。请随时关注和利用这些改进。
Murali Krishnan 是 Internet Information Server (IIS) 组的首席软件设计工程师。从 1.0 版本开始他就设计 IIS,并成功发行了 1.0 版本到 4.0 版本。Murali 组织并领导 IIS 性能组三年 (1995-1998), 从一开始就影响 IIS 性能。他拥有威斯康星州 Madison 大学的 M.S.和印度 Anna 大学的 B.S.。工作之外,他喜欢阅读、打排球和家庭烹饪。 http://community.csdn.net/Expert/FAQ/FAQ_Index.asp?id=172835
我在学习对象的生存方式的时候见到一种是在堆栈(stack)之中,如下
CObject object;
还有一种是在堆(heap)中 如下
CObject* pobject=new CObject();
请问
(1)这两种方式有什么区别?
(2)堆栈与堆有什么区别??
---------------------------------------------------------------
1) about stack, system will allocate memory to the instance of object automatically, and to the
heap, you must allocate memory to the instance of object with new or malloc manually.
2) when function ends, system will automatically free the memory area of stack, but to the
heap, you must free the memory area manually with free or delete, else it will result in memory
leak.
3)栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
4)堆上分配的内存可以有我们自己决定,使用非常灵活。














 825
825











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









