







转自:http://www.tuicool.com/articles/6zMJRn
一、深入理解 VXLAN
VXLAN 是非常新的一个 tunnel 技术,它是一个 L2 tunnel。Linux 内核的 upstream 中也刚刚加入 VXLAN 的实现。相比 GRE tunnel 它有着很的扩展性,同时解决了很多其它问题。
一,GRE tunnel 的不足
网络很多介绍 VXLAN 的文章都没有直接告诉你相比较 GRE tunnel,VXLAN 的优势在哪里,或者说 GRE tunnel 的不足在哪里。为了更好的了解 VXLAN,我们有必要看一下 GRE tunnel 的不足。
在我前面写的介绍 GRE tunnel 的文章中,其实并不容易看出 GRE tunnel 的不足之处。根本原因是图中给出的例子不太好,只有两个网络的话 GRE tunnel 的不足凸显不出来,让我们看看有三个网络的情况如何用 GRE tunnel 互联,如下图所示:

这下子就很明显了,要让这三个网络互联,我们需要建立三个 GRE tunnel。如果网络数量再增长,那么需要的 tunnel 数量更多。换句话说,GRE tunnel 的扩展性太差,从根本上讲还是因为它只是一个 point to point 的 tunnel。
二,VLAN 的不足
其实 VLAN 在某种程度上也可以看作一个 L2 over L2 的 tunnel,只不过它多了一个新的 VLAN header,这其中有12 bit 是 VLAN tag。所以 VLAN 的第一个不足之处就是它最多只支持 4096 个 VLAN 网络(当然这还要除去几个预留的),对于大型数据中心的来说,这个数量是远远不够的。
第二个不足就是,VLAN 这个所谓的 tunnel 是基于 L2 的,所以很难跨越 L2 的边界,在很大程度上限制了网络的灵活性。同时,VLAN 操作需手工介入较多,这对于管理成千上万台机器的管理员来说是难以接受的。
三,VXLAN 的引入
VXLAN 是 Virtual eXtensible LANs 的缩写,所以顾名思义,它是对 VLAN 的一个扩展,但又不仅限于此。
从数量上讲,它确实把 12 bit 的 VLAN tag 扩展成了 24 bit,所以至少暂时够用的了。从实现上讲,它是 L2 over UDP,它利用了 UDP 同时也是 IPv4 的单播和多播,可以跨 L3 边界,很巧妙地解决了 GRE tunnel 和 VLAN 存在的不足,让组网变得更加灵活。
四,VXLAN 的实现
VXLAN 的配置可以参考内核文档 Documentation/networking/vxlan.txt,本人目前还没有环境测试,所以只能做一些代码分析了。
Linux 内核中对 VXLAN 的实现是在 drivers/net/vxlan.c 源文件中,是由 Stephen Hemminger (iproute2 的维护者)完成的。代码质量相当高,所以可读性也很好,强烈推荐阅读一下。
看代码之前先看 VXLAN 的头是一个怎样的结构,如下图所示(图片来自参考资料4):
好了,现在我们可以看代码了。先看发送端,vxlan_xmit() 函数。首先需要说的是发送之前内核会检查目的地址,如果是L2 multicast,那么应该发送到 VXLAN group 组播地址,否则,如果 MAC 地址是已知的,直接单播到对应的 IP;如果未知,则广播到组播地址。代码如下,比文档还要好读。:-)
-
static __be32 vxlan_find_dst ( struct vxlan_dev * vxlan, struct sk_buff * skb )
-
{
-
const struct ethhdr * eth = ( struct ethhdr * ) skb - >data;
-
const struct vxlan_fdb * f;
-
-
if ( is_multicast_ether_addr ( eth - >h_dest ) )
-
return vxlan - >gaddr;
-
-
f = vxlan_find_mac ( vxlan, eth - >h_dest ) ;
-
if ( f )
-
return f - >remote_ip;
-
else
-
return vxlan - >gaddr;
-
-
}
剩下的基本上就是一层一层的往外添加头了,依次添加 VXLAN header,UDP header,IP header:
-
//...
-
vxh = ( struct vxlanhdr * ) __skb_push ( skb, sizeof ( * vxh ) ) ;
-
vxh - >vx_flags = htonl ( VXLAN_FLAGS ) ;
-
vxh - >vx_vni = htonl ( vxlan - >vni << 8 ) ;
-
-
__skb_push ( skb, sizeof ( * uh ) ) ;
-
skb_reset_transport_header ( skb ) ;
-
uh = udp_hdr ( skb ) ;
-
-
uh - >dest = htons ( vxlan_port ) ;
-
uh - >source = htons ( src_port ) ;
-
-
uh - >len = htons ( skb - >len ) ;
-
uh - >check = 0 ;
-
-
__skb_push ( skb, sizeof ( * iph ) ) ;
-
skb_reset_network_header ( skb ) ;
-
iph = ip_hdr ( skb ) ;
-
iph - >version = 4 ;
-
iph - >ihl = sizeof ( struct iphdr ) >> 2 ;
-
iph - >frag_off = df;
-
iph - >protocol = IPPROTO_UDP;
-
iph - >tos = vxlan_ecn_encap ( tos, old_iph, skb ) ;
-
iph - >daddr = dst;
-
iph - >saddr = fl4. saddr ;
-
iph - >ttl = ttl ? : ip4_dst_hoplimit ( & rt - >dst ) ;
-
-
vxlan_set_owner ( dev, skb ) ;
正如 GRE tunnel,比较复杂的地方是在接收端。因为 VXLAN 利用了 UDP,所以它在接收的时候势必需要有一个 UDP server 在监听某个端口,这个是在 VXLAN 初始化的时候完成的,即 vxlan_init_net() 函数:
-
static __net_init int vxlan_init_net ( struct net * net )
-
{
-
struct vxlan_net * vn = net_generic ( net, vxlan_net_id ) ;
-
struct sock * sk;
-
struct sockaddr_in vxlan_addr = {
-
. sin_family = AF_INET,
-
. sin_addr . s_addr = htonl ( INADDR_ANY ) ,
-
} ;
-
int rc;
-
unsigned h;
-
-
/* Create UDP socket for encapsulation receive. */
-
rc = sock_create_kern ( AF_INET, SOCK_DGRAM, IPPROTO_UDP, & vn - >sock ) ;
-
if ( rc < 0 ) {
-
pr_debug ( "UDP socket create failed \n " ) ;
-
return rc;
-
}
-
/* Put in proper namespace */
-
sk = vn - >sock - >sk;
-
sk_change_net ( sk, net ) ;
-
-
vxlan_addr. sin_port = htons ( vxlan_port ) ;
-
-
rc = kernel_bind ( vn - >sock, ( struct sockaddr * ) & vxlan_addr,
-
sizeof ( vxlan_addr ) ) ;
-
if ( rc < 0 ) {
-
pr_debug ( "bind for UDP socket %pI4:%u (%d) \n ",
-
& vxlan_addr. sin_addr , ntohs ( vxlan_addr. sin_port ) , rc ) ;
-
sk_release_kernel ( sk ) ;
-
vn - >sock = NULL ;
-
return rc;
-
}
-
-
/* Disable multicast loopback */
-
inet_sk ( sk ) - >mc_loop = 0 ;
-
-
/* Mark socket as an encapsulation socket. */
-
udp_sk ( sk ) - >encap_type = 1 ;
-
udp_sk ( sk ) - >encap_rcv = vxlan_udp_encap_recv;
-
udp_encap_enable ( ) ;
-
-
for ( h = 0 ; h <VNI_HASH_SIZE; ++ h )
-
INIT_HLIST_HEAD ( & vn - >vni_list [ h ] ) ;
-
-
return 0 ;
-
}
由此可见内核内部创建 socket 的 API 是sock_create_kern(),bind() 对应的是 kernel_bind()。注意到这里实现了一个hook,vxlan_udp_encap_recv(),这个正是接收端的主要代码。
发送端是一层一层往外填,那么接收端一定就是一层一层外里剥:
-
/* pop off outer UDP header */
-
__skb_pull ( skb, sizeof ( struct udphdr ) ) ;
-
-
/* Need Vxlan and inner Ethernet header to be present */
-
if ( ! pskb_may_pull ( skb, sizeof ( struct vxlanhdr ) ) )
-
goto error;
-
-
/* Drop packets with reserved bits set */
-
vxh = ( struct vxlanhdr * ) skb - >data;
-
if ( vxh - >vx_flags != htonl ( VXLAN_FLAGS ) ||
-
( vxh - >vx_vni & htonl ( 0xff ) ) ) {
-
netdev_dbg ( skb - >dev, "invalid vxlan flags=%#x vni=%#x \n " ,
-
ntohl ( vxh - >vx_flags ) , ntohl ( vxh - >vx_vni ) ) ;
-
goto error;
-
}
-
-
__skb_pull ( skb, sizeof ( struct vxlanhdr ) ) ;
-
-
/* Is this VNI defined? */
-
vni = ntohl ( vxh - >vx_vni ) >> 8 ;
-
vxlan = vxlan_find_vni ( sock_net ( sk ) , vni ) ;
-
if ( ! vxlan ) {
-
netdev_dbg ( skb - >dev, "unknown vni %d \n " , vni ) ;
-
goto drop;
-
}
-
-
if ( ! pskb_may_pull ( skb, ETH_HLEN ) ) {
-
vxlan - >dev - >stats. rx_length_errors ++ ;
-
vxlan - >dev - >stats. rx_errors ++ ;
-
goto drop;
-
}
在重新入栈之前还要做一些准备工作:
-
/* Re-examine inner Ethernet packet */
-
oip = ip_hdr ( skb ) ;
-
skb - >protocol = eth_type_trans ( skb, vxlan - >dev ) ;
-
-
/* Ignore packet loops (and multicast echo) */
-
if ( compare_ether_addr ( eth_hdr ( skb ) - >h_source,
-
vxlan - >dev - >dev_addr ) == 0 )
-
goto drop;
-
-
if ( vxlan - >learn )
-
vxlan_snoop ( skb - >dev, oip - >saddr, eth_hdr ( skb ) - >h_source ) ;
-
-
__skb_tunnel_rx ( skb, vxlan - >dev ) ;
-
skb_reset_network_header ( skb ) ;
-
skb - >ip_summed = CHECKSUM_NONE;
另外需要特别指出的是:1) 加入和离开组播地址是在 vxlan_open() 和 vxlan_stop() 中完成的;2) Linux 内核已经把 bridge 的 L2 learn 功能给抽出来了,所以 VXLAN 也实现了对 L2 地址的学习和转发:
-
static const struct net_device_ops vxlan_netdev_ops = {
-
. ndo_init = vxlan_init,
-
. ndo_open = vxlan_open,
-
. ndo_stop = vxlan_stop,
-
. ndo_start_xmit = vxlan_xmit,
-
. ndo_get_stats64 = vxlan_stats64,
-
. ndo_set_rx_mode = vxlan_set_multicast_list,
-
. ndo_change_mtu = eth_change_mtu,
-
. ndo_validate_addr = eth_validate_addr,
-
. ndo_set_mac_address = eth_mac_addr,
-
. ndo_fdb_add = vxlan_fdb_add,
-
. ndo_fdb_del = vxlan_fdb_delete,
-
. ndo_fdb_dump = vxlan_fdb_dump,
-
} ;
附注:openvswitch 中的 VXLAN 的实现: http://openvswitch.org/pipermail/dev/2011-October/012051.html
参考资料:
1. http://tools.ietf.org/html/draft-mahalingam-dutt-dcops-vxlan-02
2. http://blogs.cisco.com/datacenter/digging-deeper-into-vxlan/
3. http://www.yellow-bricks.com/2012/11/02/vxlan-use-cases/
4. http://www.borgcube.com/blogs/2011/11/vxlan-primer-part-1/
5. http://www.borgcube.com/blogs/2012/03/vxlan-primer-part-2-lets-get-physical/
6. http://it20.info/2012/05/typical-vxlan-use-case/
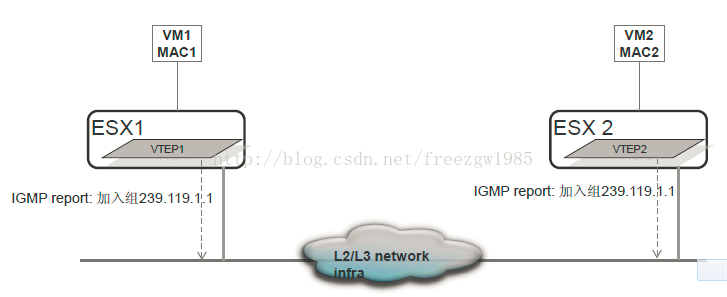
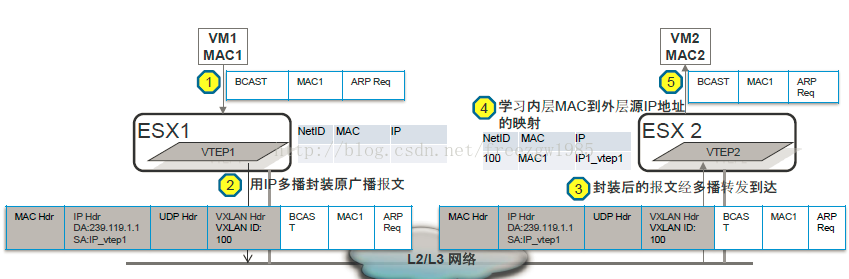
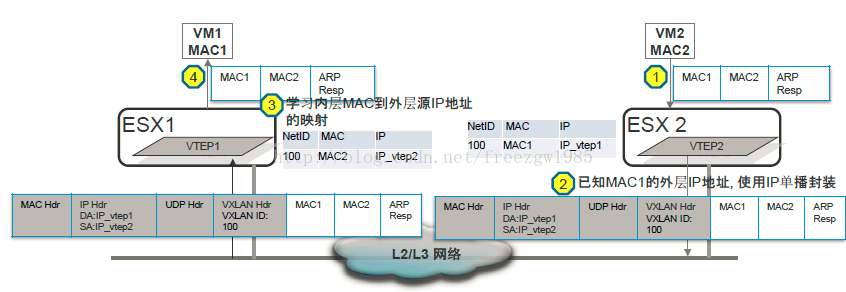
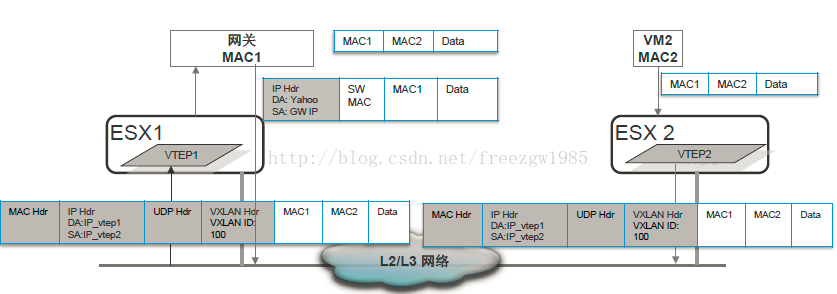
二、vxlan隧道技术介绍——转自:http://blog.csdn.net/freezgw1985/article/details/16354897
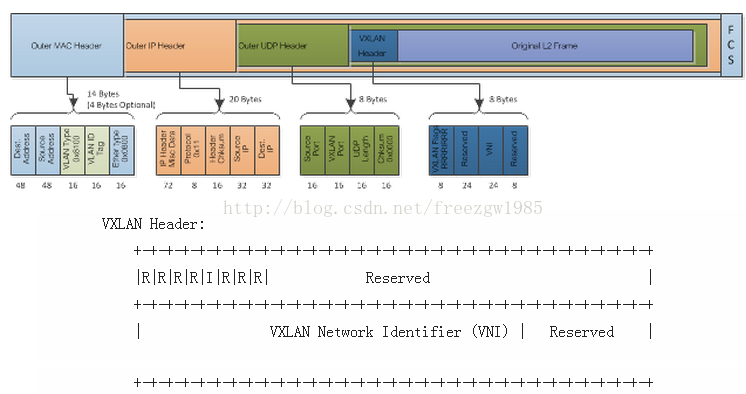
- protocol:设置值为0x11,显示说明这是UDP数据包
- Source ip: 源vTEP_IP;
- Destination ip: 目的VTEP IP。
- Destination Address:目的VTEP的Mac 地址,即为本地下一跳的地址(通常是网关Mac 地址);
- VLAN: VLAN Type被设置为0x8100, 并可以设置Vlan Id tag(这就是vxlan的vlan 标签)。
- Ethertype:设置值为0x8000,指明数据包为IPv4的。














 1496
1496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









