







kmeans数学基础
以后补充
样本数据:
代码:
setwd("/users/XXX/desktop/R/chapter5/示例程序")
myData<-read.csv("consumption_data.csv")[,2:4]
head(myData)
#求有多少条数据
length(myData$F)
#center=3是指聚类个数k=3,简单说就是分三类
km<-kmeans(myData,center=3)
print(km)
#这说明了总计940条数据,分成三类的各自的数量
K-means clustering with 3 clusters of sizes 218, 370, 352
#三类的平均值
Cluster means:
R F M
1 16.09174 10.711009 1913.3965
2 15.48919 7.316216 429.8898
3 18.47727 11.355114 1198.3034
#每条数据属于第几类的
Clustering vector:
[1] 2 3 3 2 1 2 2 3 2 3 2 2 1 1 1 1 3 3 2 2 2 1 3 2 2 1 1 1 2 1 3 2 2 3 3 2 2
[38] 3 1 2 2 1 2 3 2 3 3 3 1 1 1 1 1 3 2 3 3 1 3 2 3 3 2 3 1 2 1 3 2 1 2 3 3 2
[75] 1 2 3 2 1 1 2 2 3 2 2 3 3 2 2 3 3 2 2 3 3 1 2 2 1 2 2 3 1 3 2 2 2 3 3 2 3
[112] 3 1 2 2 2 2 2 3 3 2 1 2 2 2 2 2 3 2 3 1 2 2 2 3 3 2 3 1 2 1 3 2 3 2 2 2 2
[149] 1 1 1 3 3 3 2 2 1 2 1 1 3 3 2 2 2 2 2 3 3 3 3 1 3 1 2 1 2 2 2 2 2 2 3 2 3
[186] 2 3 3 3 3 2 3 3 3 3 1 3 1 2 2 2 3 2 3 3 1 3 2 3 3 2 2 3 3 2 2 2 3 3 3 1 3
[223] 3 2 3 1 3 3 2 2 2 2 1 3 1 2 2 3 3 2 2 3 3 2 2 1 2 3 2 2 3 1 1 2 3 3 2 3 1
[260] 3 3 3 3 1 1 2 1 2 2 1 3 2 1 3 1 2 1 3 2 1 3 3 3 3 2 1 2 3 3 2 3 2 2 2 3 1
[297] 2 3 2 1 3 3 2 3 1 3 2 3 3 3 2 3 2 3 2 3 3 3 3 3 3 2 3 1 2 1 2 3 3 3 2 1 3
[334] 1 2 1 3 2 1 1 2 2 3 3 3 2 2 3 2 1 2 2 2 3 2 3 2 3 3 2 3 2 1 3 3 2 2 3 3 2
[371] 2 3 3 3 3 2 2 2 3 1 2 2 2 3 2 3 3 3 3 2 2 2 1 1 2 3 3 1 1 3 1 2 3 2 3 2 3
[408] 3 1 1 2 1 3 3 3 1 3 2 3 3 3 1 2 3 3 2 3 1 3 3 3 2 1 3 3 1 2 3 1 3 1 3 2 3
[445] 2 3 2 2 1 2 3 2 1 3 3 1 2 3 1 2 2 3 2 2 2 3 1 1 2 3 3 3 2 2 3 1 3 3 1 3 1
[482] 1 1 1 2 2 1 3 2 3 2 1 2 3 2 2 1 3 1 1 2 1 3 3 2 3 3 1 2 3 1 1 3 1 3 1 2 3
[519] 2 3 1 2 3 2 1 1 2 1 2 2 3 2 2 1 2 1 2 3 3 3 1 3 1 2 3 1 1 2 2 1 2 2 3 3 3
[556] 1 2 3 1 3 1 3 2 1 1 2 2 1 1 3 1 2 2 1 3 3 3 2 1 2 3 1 2 2 2 2 2 3 2 2 3 3
[593] 2 3 3 2 2 3 2 3 3 2 2 2 1 3 3 2 3 3 2 1 2 2 2 2 2 2 3 3 1 2 3 2 2 2 1 3 2
[630] 3 3 2 1 2 2 3 3 1 1 2 3 1 3 3 2 2 1 2 3 3 3 3 3 2 2 2 2 2 1 3 3 1 2 3 3 3
[667] 1 1 1 3 2 3 3 1 1 1 1 3 1 2 3 2 1 2 1 2 2 3 2 3 3 1 3 3 1 3 1 1 3 3 3 3 1
[704] 2 1 1 2 3 2 2 3 3 2 2 3 2 2 2 3 1 1 1 2 2 2 2 2 1 3 1 2 2 3 3 3 2 2 2 2 2
[741] 2 1 1 2 2 2 2 3 1 2 2 2 1 3 1 2 3 3 1 3 2 3 3 2 3 3 2 3 1 1 2 1 2 3 2 2 2
[778] 3 2 3 2 3 1 1 2 2 1 1 2 1 2 3 3 2 1 2 2 2 3 3 3 2 2 1 1 3 3 2 3 3 2 2 2 2
[815] 2 2 1 2 3 2 2 2 3 2 3 2 2 3 2 2 3 2 3 2 1 2 2 3 3 3 3 1 2 3 1 2 2 1 1 3 2
[852] 2 3 2 2 3 1 1 1 1 3 3 2 2 1 2 3 3 3 2 3 1 2 2 3 1 1 2 1 2 1 3 2 3 3 2 1 3
[889] 3 2 3 1 3 2 3 1 3 2 2 1 2 2 1 3 2 1 1 3 2 3 1 3 2 1 1 1 3 2 2 3 3 3 3 2 1
[926] 3 3 2 1 3 1 1 1 1 1 3 3 3 3 2
Within cluster sum of squares by cluster:
[1] 133181360 18978771 16383138
(between_SS / total_SS = 65.0 %)
Available components:
[1] "cluster" "centers" "totss" "withinss" "tot.withinss"
[6] "betweenss" "size" "iter" "ifault"
#每一类所占总样本的百分比
km$size/sum(km$size)
#数据分组 km$cluster每条数据所属类别向量组,就是向原数据集添加了一列所属分类的数据
aaa<-data.frame(myData,km$cluster)
#很奇怪这里为什么不用aaa
Data1<-myData[which(aaa$km.cluster==1),]
Data2<-myData[which(aaa$km.cluster==2),]
Data3<-myData[which(aaa$km.cluster==3),]
#分群“1”的概率密度函数图 par()多个图显示在一个图中的函数
png("kmean.png")
par(mfrow=c(3,3))
plot(density(Data1[,1]),col="red",main="R")
plot(density(Data1[,2]),col="red",main="F")
plot(density(Data1[,3]),col="red",main="M")
plot(density(Data2[,1]),col="red",main="R")
plot(density(Data2[,2]),col="red",main="F")
plot(density(Data2[,3]),col="red",main="M")
plot(density(Data3[,1]),col="red",main="R")
plot(density(Data3[,2]),col="red",main="F")
plot(density(Data3[,3]),col="red",main="M")
dev.off()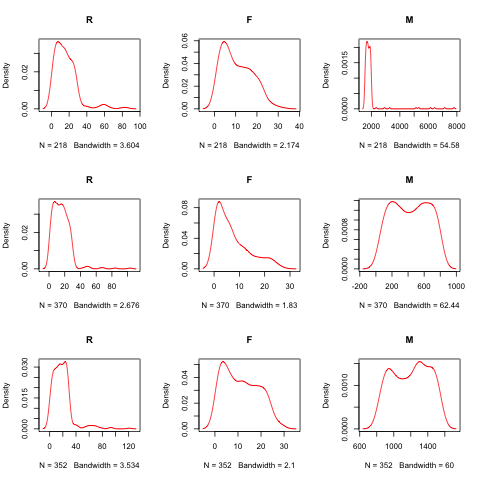














 3538
3538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









