







使用JDOM方式解析XML文件,不是java官方提供的方法,所以我们的需要自己导入一个jdom-2.0.5.jar包,下载地址为:http://download.csdn.net/detail/xx_123_1_rj/8306099
JDOMmxl.java :
package cn.ytu.xml;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
import org.jdom2.Attribute;
import org.jdom2.Document;
import org.jdom2.Element;
import org.jdom2.JDOMException;
import org.jdom2.input.SAXBuilder;
public class JDOMmxl {
private static ArrayList<Book> booksList = new ArrayList<Book>();
/**
* @param args
*/
public static void main(String[] args) {
// 进行对books.xml文件的JDOM解析
// 准备工作
// 1.创建一个SAXBuilder的对象
SAXBuilder saxBuilder = new SAXBuilder();
InputStream in;
try {
// 2.创建一个输入流,将xml文件加载到输入流中
in = new FileInputStream("xml/books.xml");
InputStreamReader isr = new InputStreamReader(in, "UTF-8");
// 3.通过saxBuilder的build方法,将输入流加载到saxBuilder中
Document document = saxBuilder.build(isr);
// 4.通过document对象获取xml文件的根节点
Element rootElement = document.getRootElement();
// 5.获取根节点下的子节点的List集合
List<Element> bookList = rootElement.getChildren();
// 继续进行解析
for (Element book : bookList) {
Book bookEntity = new Book();
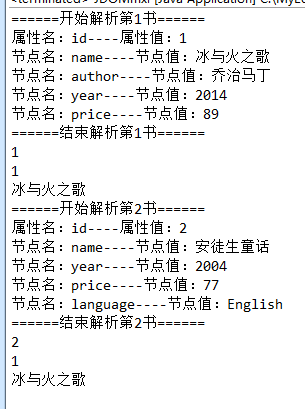
System.out.println("======开始解析第" + (bookList.indexOf(book) + 1)
+ "书======");
// 解析book的属性集合
List<Attribute> attrList = book.getAttributes();
// //知道节点下属性名称时,获取节点值
// book.getAttributeValue("id");
// 遍历attrList(针对不清楚book节点下属性的名字及数量)
for (Attribute attr : attrList) {
// 获取属性名
String attrName = attr.getName();
// 获取属性值
String attrValue = attr.getValue();
System.out.println("属性名:" + attrName + "----属性值:"
+ attrValue);
if (attrName.equals("id")) {
bookEntity.setId(attrValue);
}
}
// 对book节点的子节点的节点名以及节点值的遍历
List<Element> bookChilds = book.getChildren();
for (Element child : bookChilds) {
System.out.println("节点名:" + child.getName() + "----节点值:"
+ child.getValue());
if (child.getName().equals("name")) {
bookEntity.setName(child.getValue());
}
else if (child.getName().equals("author")) {
bookEntity.setAuthor(child.getValue());
}
else if (child.getName().equals("year")) {
bookEntity.setYear(child.getValue());
}
else if (child.getName().equals("price")) {
bookEntity.setPrice(child.getValue());
}
else if (child.getName().equals("language")) {
bookEntity.setLanguage(child.getValue());
}
}
System.out.println("======结束解析第" + (bookList.indexOf(book) + 1)
+ "书======");
booksList.add(bookEntity);
bookEntity = null;
System.out.println(booksList.size());
System.out.println(booksList.get(0).getId());
System.out.println(booksList.get(0).getName());
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (JDOMException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
package cn.ytu.xml;
public class Book {
private String id;
private String name;
private String author;
private String year;
private String price;
private String language;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getYear() {
return year;
}
public void setYear(String year) {
this.year = year;
}
public String getPrice() {
return price;
}
public void setPrice(String price) {
this.price = price;
}
public String getLanguage() {
return language;
}
public void setLanguage(String language) {
this.language = language;
}
}
books.xml :
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book id="1">
<name>冰与火之歌</name>
<author>乔治马丁</author>
<year>2014</year>
<price>89</price>
</book>
<book id="2">
<name>安徒生童话</name>
<year>2004</year>
<price>77</price>
<language>English</language>
</book>
</bookstore>














 279
279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









