







问题导读:
1.Flume-NG与Scribe对比,Flume-NG的优势在什么地方?
2.架构设计考虑需要考虑什么问题?
3.Agent死机该如何解决?
4.Collector死机是否会有影响?
5.Flume-NG可靠性(reliability)方面做了哪些措施?
美团的日志收集系统负责美团的所有业务日志的收集,并分别给Hadoop平台提供离线数据和Storm平台提供实时数据流。美团的日志收集系统基于Flume设计和搭建而成。
《基于Flume的美团日志收集系统》将分两部分给读者呈现美团日志收集系统的架构设计和实战经验。
第一部分架构和设计,将主要着眼于日志收集系统整体的架构设计,以及为什么要做这样的设计。
第二部分改进和优化,将主要着眼于实际部署和使用过程中遇到的问题,对Flume做的功能修改和优化等。
1 日志收集系统简介
日志收集是大数据的基石。
许多公司的业务平台每天都会产生大量的日志数据。收集业务日志数据,供离线和在线的分析系统使用,正是日志收集系统的要做的事情。高可用性,高可靠性和可扩展性是日志收集系统所具有的基本特征。
目前常用的开源日志收集系统有
Flume
,
Scribe
等。Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,目前已经是Apache的一个子项目。Scribe是
Facebook
开源的日志收集系统,它为日志的分布式收集,统一处理提供一个可扩展的,高容错的简单方案。
2 常用的开源日志收集系统对比
3 美团日志收集系统架构
下面将对常见的开源日志收集系统Flume和Scribe的各方面进行对比。对比中Flume将主要采用Apache下的Flume-NG为参考对象。同时,我们将常用的日志收集系统分为三层(Agent层,Collector层和Store层)来进行对比。
美团的日志收集系统负责美团的所有业务日志的收集,并分别给Hadoop平台提供离线数据和Storm平台提供实时数据流。美团的日志收集系统基于Flume设计和搭建而成。目前每天收集和处理约T级别的日志数据。
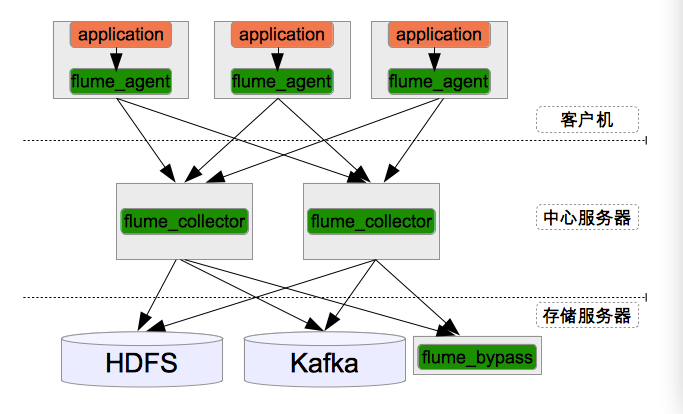
下图是美团的日志收集系统的整体框架图
a. 整个系统分为三层:Agent层,Collector层和Store层。其中Agent层每个机器部署一个进程,负责对单机的日志收集工作;Collector层部署在中心服务器上,负责接收Agent层发送的日志,并且将日志根据路由规则写到相应的Store层中;Store层负责提供永久或者临时的日志存储服务,或者将日志流导向其它服务器。
b. Agent到Collector使用LoadBalance策略,将所有的日志均衡地发到所有的Collector上,达到负载均衡的目标,同时并处理单个Collector失效的问题。














 44
44











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









