









中文分词是中文文本处理的一个基础性工作,结巴分词利用进行中文分词。其基本实现原理有三点:
基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG)
采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法
下面利用结巴分词队水浒传的词频进行了统计
更多内容访问omegaxyz.com
代码:
#!/usr/bin/python
# -*- coding:utf-8 -*-
import sys
import jieba
import jieba.analyse
import xlwt # 写入Excel表的库
if __name__ == "__main__":
wbk = xlwt.Workbook(encoding='ascii')
sheet = wbk.add_sheet("wordCount") # Excel单元格名字
word_lst = []
key_list = []
for line in open('C:\\Users\\dell\\desktop\\1.txt'): # 1.txt是需要分词统计的文档
try:
item = line.strip('\n\r').split('\t') # 制表格切分
# print(item)
tags = jieba.analyse.extract_tags(item[0]) # jieba分词
for t in tags:
word_lst.append(t)
except:
pass
word_dict = {}
with open("wordCount.txt", 'w') as wf2: # 打开文件
for item in word_lst:
if item not in word_dict: # 统计数量
word_dict[item] = 1
else:
word_dict[item] += 1
orderList = list(word_dict.values())
orderList.sort(reverse=True)
# print orderList
for i in range(len(orderList)):
for key in word_dict:
if word_dict[key] == orderList[i]:
wf2.write(key + ' ' + str(word_dict[key]) + '\n') # 写入txt文档
key_list.append(key)
word_dict[key] = 0
for i in range(len(key_list)):
sheet.write(i, 1, label=orderList[i])
sheet.write(i, 0, label=key_list[i])
wbk.save('wordCount.xls') # 保存为 wordCount.xls文件结果:
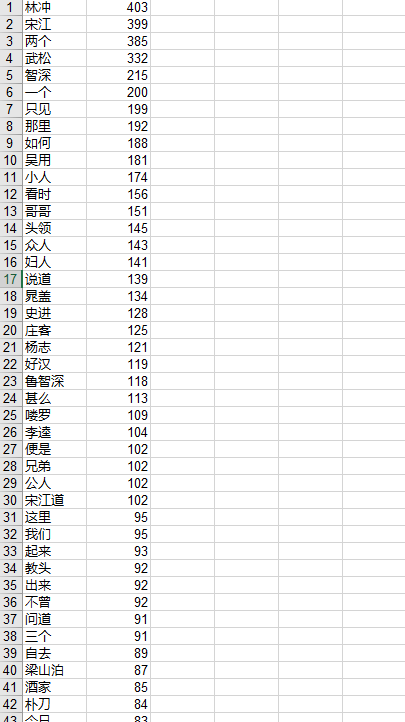
更多内容访问omegaxyz.com














 4174
4174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









