







部署的服务器:
192.168.131.172
192.168.131.173
192.168.131.174
步骤:1 配置java运行环境
首先检查服务器上是否安装java运行环境,可直接运行如下命令检查:
java -version
如果安装了的话,会显示当前java的版本,反之则说明该机器没有安装java的运行环境,需安装java的运行环境。
相关命令:yum install java
步骤2:安装cassandra数据库
下载Cassandra数据库到本地:
相关命令:wget http://www.apache.org/dyn/closer.cgi?path=/cassandra/1.2.5/apache-cassandra-1.2.5-bin.tar.gz![]()
解压:tar -zxvf apache-cassandra-1.2.5-bin.tar.gz
重命名Cassandra目录名:mv apache-cassandra-1.2.5 cassandra
至此,Cassandra已安装完成。
配置Cassandra:
Cassandra是在第一次运行的时候,就将所有的配置文件读取完成,下次就不再从配置文件读取,所有需保证在运行Cassandra之前Cassandra的配置必须都是正确的。
如果启动Cassandra后,发现配置有错误,需将Cassandra启动产生的所有数据都删除,数据的存储目录默认在:/var/lib/cassandra
执行删除命令:rm -rf *
需配置的地方:1> 集群名
cluster_name: 'Cluster_1'
集群的所有节点的集群名必须是一样的,这是必须。
2> initial_token:此值是根据一定的算法得出的,也是
非常重要切比较有意思的地方,设置此值的目的是让集群的节点可以均衡的负载,如果不为该标识赋值的话,则Cassandra启动后,会默认为该token付值,但是却保证不了集群中节点的均衡负载(平均分配)算法如下:
将该命令拷贝至linux,回车,会输出通过该算法计算而得的3个token值,将这3个值分别配置到上述的3个节点上。这样就保证了对于存入cassandra中数据的平均分配。
python -c 'print [str(((2**64 / 6) * i) - 2**63) for i in range(6)]'
根据不同的节点数,自行修改。上面是打印出6个节点的代码。如果是3个的话,则如下:
python -c 'print [str(((2**64 / 3) * i) - 2**63) for i in range(3)]'
seeds:集群的节点,这里需要把集群的所有节点的Ip写在这里,节点之间用“,”(逗号)隔开
listen_address:本机ip
rpc_address: 0.0.0.0
==============================================
为了便于操作和维护,我们可以把不同的节点的服务器名都根据自己的Ip修改下,便于分辨。
比如192.168.131.172 ,默认的hostname为localhost,我们可以改为“CENTOS131172”.
如果确实这样改过了,则该节点的host也需增加相关解析,如下:
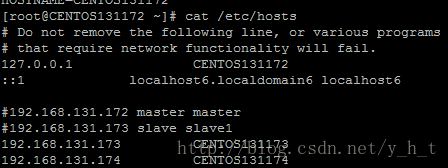
上面的图,显示的是我将3个节点的hostname都改过了,并在各自的节点的hosts里都增加对集群其他节点的解析。
相关参考命令:
ps ax|grep cassandra 检查cassandra运行pid
echo CENTOS131172 > /proc/sys/kernal/hostname 修改主机名
cassand 数据存储位置:/var/lib/cassandra















 677
677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









