










上一篇博文《BAT解密:互联网技术发展之路(6)- 服务层技术剖析》中,介绍了互联网业务发展特点的中的“复杂性”的应对方式,本文介绍互联网业务发展特点的另外两个方面“高性能”、“高可用”。
一般人提到高性能时第一想到的就是优化,提到高可用时第一反应就是双机或者备份,但是对于互联网这种超大容量和访问量的业务来说,这两个手段都是雕虫小技,无法应对互联网业务的高性能和高可用需求,互联网业务的高可用和高性能,需要从更高的角度去设计,这个高点就是“网络”,所以我将这些措施统一划归为“网络层”。注意这里的网络层和大家通常理解的如何搭建一个局域网这种概念不一样,强调的是站在网络层的整体设计,而不是某个具体网络的搭建。
负载均衡
故名思议,负载均衡就是将请求均衡的分配到多个系统上。使用负载均衡的原因也很简单:每个系统的处理能力是有限的,为了应对大容量的访问,必须使用多个系统。例如一台32核64G内存的机器,每秒处理http请求最多不会超过10万,而互联网的业务,不到百万级都不好意思说自己是互联网业务。
负载均衡虽然理解起来简单,但实现方式就很多了,可大可小;可以软件实现,也可以硬件实现,由于涉及的技术很多,这里只是简单的介绍常用技术。
【DNS】
DNS是最简单的、也是最常见的负载均衡方式,一般用来实现地理级别的均衡,例如北方的用户访问北京的机房,南方的用户访问广州的机房;一般不太会使用DNS来做机器级别的负载均衡,因为太耗费IP资源了,例如百度搜索可能要10000台机器以上,不可能将这么多机器全部配置公网ip然后用DNS来做负载均衡。有兴趣的同学可以在linux用 dig baidu.com命令看看实际上用了几个ip地址。
DNS负载均衡的优点是通用(全球通用),成本低(申请域名,注册DNS即可),但缺点也比较明显,主要体现在:
1)DNS缓存的时间比较长,即使将某台业务机器从DNS服务器上删除,由于缓存的原因,还是有很多用户会继续访问已经被删除的机器
2)DNS不够灵活:DNS不能感知后端服务器的状态,只能根据配置策略进行负载均衡,无法做到更加灵活的负载均衡策略。比如说某台机器的配置比其它机器要好很多,理论上来说应该多分配一些请求给它,但DNS无法做到这点。
所以对于时延和故障敏感的业务,有一些公司自己实现了HTTP-DNS的功能,即:使用http协议实现一个私有的DNS系统。这样的方案和通用的DNS优缺点正好相反。
【Nginx & LVS & F5】
DNS用于实现地理级别的负载均衡,而Nginx&LVS&F5就是用于同一地点内机器级别的负载均衡。其中Nginx是软件的7层负载均衡,LVS是内核的4层负载均衡,F5是硬件做4层负载均衡。
软件和硬件的区别就在于性能,硬件远远高于软件,Ngxin的性能是万级,一般的linux服务器上装个nginx大概能到5万每秒;LVS的性能是十万级,没有具体测试过,据说可达到80万每秒;F5性能是百万级,从200万每秒到800万每秒都有,不过价格也是吓死人,最普通的一台F5就是一台马六,好一点的就是宝马Q7了,非土豪和大厂不能承担。
4层和7层的区别就在于协议和灵活性。Nginx支持HTTP、Email协议,而LVS和F5是4层负载均衡,和协议无关,几乎所有应用都可以做,例如聊天、数据库等
更多详细信息可以google去查,例如:Nginx、LVS及HAProxy负载均衡软件的优缺点详解
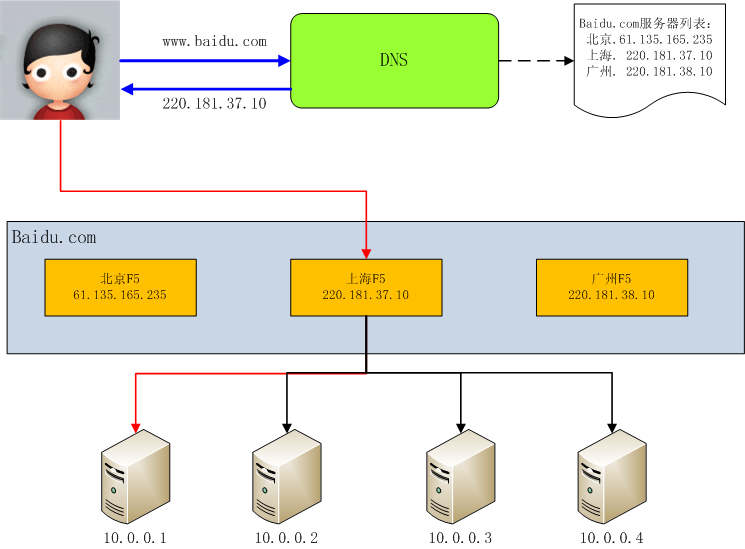
如下图形象的展示了一个实际请求过程中,地理级别的负载均衡和机器级别的负载均衡是如何分工和结合的,其中蓝色线是地理级别的负载均衡,红色线是机器级别的负载均衡:
CDN
CDN是为了解决用户网络访问时的“最后一公里”效应,本质上是一种“以空间换时间”的加速策略,即:将内容缓存在离用户最近的地方,用户访问的是缓存的内容,而不是站点实时的内容。
但CDN经过这么多年的发展,已经变成了一个很庞大的体系:分布式存储、全局负载均衡、网络重定向、流量控制等都属于CDN的范畴了,本文寥寥数语很难全面覆盖,有兴趣的可以独立深入去研究。
幸运的是,大部分程序员和架构师都不太需要深入理解CDN的细节,因为CDN作为网络的基础服务,独立搭建的成本巨大,很少有公司自己设计和搭建CDN系统,都是从CDN服务商购买CDN服务即可。
多机房
从架构上来说,单机房就是一个全局的网络单点,在发生比较大的故障或者灾害时,单机房难以保证业务的高可用。例如:停电、机房网络中断、地震、水灾。。。。。。等都有可能导致一个机房完全瘫痪。很多人以为这种事情的概率比较低,其实这种认识是错误的。停电和机房空调或者网络坏掉这种事故,运气好一年一两次,运气不好一年5、6次;水灾导致的停电在东南沿海几乎年年有,2013年汕头水灾导致整个机房被水淹了。所以机房故障要作为我们设计必须考虑的一个因素。
多机房设计最核心的设计因素就是如何处理时延带来的影响,常见的策略有:
1. 同城多机房
同一个城市多个机房,距离不会太远,可以投入重金,搭建私有的高速网络,基本上能够做到和同机房一样的效果。
这种方式对业务影响很小,但投入较大,如果不是土豪公司,一般是承受不起的;而且遇到极端的地震、2013年汕头水灾这样自然灾害,同城多机房也是有很大风险的。
2. 跨城多机房
在不同的城市搭建多个机房,机房间通过网络进行数据复制(例如MySQL主备复制),但由于跨城网络时延的问题,业务上需要做一定的妥协和兼容,不需要数据的实时强一致性,保证最终一致性。
例如微博类产品,B用户关注了A用户,A用户在北京机房发布了一条微博,B在广州机房不需要立刻看到A用户发的微博,等10分钟看到也可以。
这种方式实现简单,但和业务有很强的相关性,例如微博可以这样做,支付宝就不能这样做。
3. 跨国多机房
和跨城多机房类似,只是地理上分布更远,时延更大。由于时延太大和用户跨国访问实在太慢,跨国多机房一般仅用于备份和服务本国用户。
多中心
多中心必须以多机房为前提,但从设计的角度来看,多中心相比多机房是本质的飞越,难度也高出一个等级。
简单来说,多机房的主要目标是灾备,当机房故障的时候,我们可以比较快速的将业务切换到另外一个机房,这种切换操作允许一定时间的中断(例如10分钟、1个小时),而且业务也可能有损失,例如某些未同步的数据可能就不能马上恢复,或者要等几天才恢复,甚至永远都不能恢复了。但多中心的要求就高多了,要求每个中心都同时对外提供服务,且业务能够自动在多中心之间切换,故障后不需人工干预或者很少人工干预就能自动恢复。
多中心设计的关键就在于“数据一致性”和“数据事务性”如何保证,但这两个难点都和业务紧密相关,不存在通用的解决方案,需要基于业务的特性进行详细的分析和设计。以淘宝为例,淘宝对外宣称自己是多中心的,但是在实际设计过程中,商品浏览的多机房方案、订单的多机房方案、支付的多机房方案都需要独立设计和实现。
正因为多中心设计的复杂性,不一定所有业务都能实现多中心,目前国内的银行、支付宝这类系统就没有完全实现多中心。不然也就不会出现蓝翔挖掘机一铲子下去,支付宝中断4小时的故障。
可以参考我现在所在公司的多中心的一个实现方案:面向业务的立体化高可用架构设计
======================转载注明出处=========================
欢迎转载,转载注明出处:BAT解密:互联网技术发展之路(7)- 网络层技术剖析














 2081
2081











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









