









Caffe上有很多使用了Google Protocol Buffer的东西,从网上来看,这“是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,很适合做数据存储或 RPC 数据交换格式。它可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式”。作为caffe模型定义的数据格式,看懂caffe.proto对caffe的理解会有很大帮助。
小例子
我们首先要在.proto文件中定义协议缓冲区消息类型(protocol buffer message types),来指定要序列化的信息的结构。下面是官网的一个小例子,定义了一个人的信息:
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phone = 4;
}
在 protobuf 的术语中,结构化数据被称为 Message,message中有不同成员。proto 文件非常类似 java 或者 C 语言的数据定义,string、int32这种类型我们已经见得多了。支持类型包括数字(整数或浮点), 布尔值,,字符串,原始字节(raw bytes),或者是其他的message类型 (如上例) 。除了这些类型,其前后多了一些“修饰”。类型前是field rules,有可选(optional)、必填(required)、重复(repeated)三种。后面是message中的ID,同一message下ID随成员递增。
定义一个消息类型
上面的例子其实已经定义了一个较为复杂的message。而对于一个完整的proto文件,在文件前还应该加上
syntax = "proto2";//说明语法是2还是3
package caffe; //包名,通常与文件名相同
首先是field rules,
Specifying Field Rules
- required:本字段一个massage必须只有一个。
- optional:本字段可以有0个或1个。
- repeated:本字段可以重复任何次,并保留顺序。
其中必填字段在使用中需要小心,特别是从必填改到可选时,读取时可能认为这个字段是不完整的。
Assigning Tags
定义消息中的每一个字段都有唯一的编号标签ID,用于消息二进制标识,并且在使用后不应该变。由于编码的原因,值在1到15范围的编号需要一个字节编码,包括标识号与字段类型。在16到2047范围的标签用两个字节。这对于数据储存大小有很大的联系,因此频繁出现的标签成员应该使编号尽可能小。其原因在于一种Varint的编码。其标签范围是1到 229−1 (536,870,911),同时除了中间的19000到19999,这是为协议缓冲区(Protocol Buffers)实现保留的。
Reserved Fields
保留字段,是对于被删除或者注释的字段进行保留, 如果以后加载相同.proto的旧版本,这可能会导致严重的问题。确保不会发生这种情况的一种方法是指定保留已删除字段的字段标签。协议缓冲区编译器将报告任何未来的用户是否尝试使用这些字段标识符。
message Foo {
reserved 2, 15, 9 to 11;
reserved "foo", "bar";
}
不能在同一保留语句中混合字段名和标识号。
编译.proto文件
使用写好的proto就可以用编译器将文件编译为目标语言了。在protobuf V3.0网站上可以下载 Protobuf V3.0的源代码,V2.6版本在网页上比较靠后,更新到2.6.1。然后解压编译安装便可以使用它了。从caffe文件上看用的还是2的语法。2和3的区别可以从网上搜到,如Google Protobuf 3版本介绍。其实变化也是不少,比如只保留repeated标记数组类型,optional和required都被去掉了;字段default标记不能使用了。
坑爹的是服务器没有权限装不了,于是只好在自家电脑上用windows版的。主要是用于验证,
package lm;
message helloworld
{
required int32 id = 1; // ID
required string str = 2; // str
optional int32 opt = 3; //optional field
}
用命令行执行
protoc -I=. --cpp_out=. lm.helloworld.proto
得到了两个文件:lm.helloworld.pb.h , 定义了 C++ 类的头文件
lm.helloworld.pb.cc , C++ 类的实现文件。有了这两个文件,之后我们想读写都可以用类操作实现了。
读写数据
数据写到磁盘代码
#include "lm.helloworld.pb.h"
…
int main(void)
{
lm::helloworld msg1;
msg1.set_id(101);
msg1.set_str(“hello”);
// Write the new address book back to disk.
fstream output("./log", ios::out | ios::trunc | ios::binary);
if (!msg1.SerializeToOstream(&output)) {
cerr << "Failed to write msg." << endl;
return -1;
}
return 0;
}在代码中,其实重要的只是前三行,定义了helloworld类的对象,设置id的值,设置str的值。最后用SerializeToOstream输出到文件流。
读取数据代码
#include "lm.helloworld.pb.h"
…
void ListMsg(const lm::helloworld & msg) {
cout << msg.id() << endl;
cout << msg.str() << endl;
}
int main(int argc, char* argv[]) {
lm::helloworld msg1;
{
fstream input("./log", ios::in | ios::binary);
if (!msg1.ParseFromIstream(&input)) {
cerr << "Failed to parse address book." << endl;
return -1;
}
}
ListMsg(msg1);
…
}在读取代码中,声明类 helloworld 的对象 msg1,然后利用 ParseFromIstream 从一个 fstream 流中读取信息并反序列化。此后,ListMsg 中采用 get 方法读取消息的内部信息,并进行打印输出操作。
分别运行后得到如下结果:
>writer
>reader
101
Hello
验证了程序。
Peotocol Buffer 编码
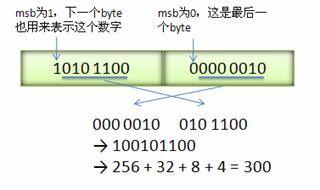
在标签中说到了Varint,现在再结合编码讲一下,主要是参考了引用2的网页。Varint 中的每个 byte 的最高位 bit 有特殊的含义,如果该位为 1,表示后续的 byte 也是该数字的一部分,如果该位为 0,则结束。其他的 7 个 bit 都用来表示数字。因此小于 128 的数字都可以用一个 byte 表示。大于 128 的数字,比如 300,会用两个字节来表示:1010 1100 0000 0010。下图演示了 Google Protocol Buffer 如何解析两个 bytes。注意到最终计算前将两个 byte 的位置相互交换过一次,这是因为 Google Protocol Buffer 字节序采用 little-endian(小端在前) 的方式。
消息经过序列化后会成为一个二进制数据流,该流中的数据为一系列的 Key-Value 对。如下图所示:
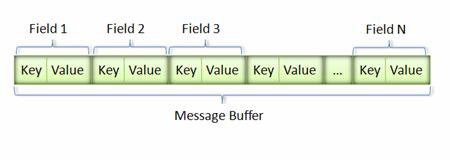
采用这种 Key-Pair 结构无需使用分隔符来分割不同的 Field。对于可选的 Field,如果消息中不存在该 field,那么在最终的 Message Buffer 中就没有该 field,这些特性都有助于节约消息本身的大小。
假如生成如下的消息:
Test1.id = 10;
Test1.str = “hello”;
则最终的 Message Buffer 中有两个 Key-Value 对,一个对应消息中的 id;另一个对应 str。Key 用来标识具体的 field,在解包的时候,Protocol Buffer 根据 Key 就可以知道相应的 Value 应该对应于消息中的哪一个 field。Key 的定义如下:
(field_number << 3) | wire_type //<<是左移运算
可以看到 Key 由两部分组成。第一部分是 field_number,比如消息 lm.helloworld 中 field id 的 field_number 为 1。第二部分为 wire_type。表示 Value 的传输类型。其中wire_type有如下几种:

在我们的例子当中,field id 所采用的数据类型为 int32,因此对应的 wire type 为 0。细心的读者或许会看到在 Type 0 所能表示的数据类型中有 int32 和 sint32 这两个非常类似的数据类型。Google Protocol Buffer 区别它们的主要意图也是为了减少 encoding 后的字节数。
在计算机内,一个负数一般会被表示为一个很大的整数,因为计算机定义负数的符号位为数字的最高位。如果采用 Varint 表示一个负数,那么一定需要 5 个 byte。为此 Google Protocol Buffer 定义了 sint32 这种类型,采用 zigzag 编码。Zigzag 编码用无符号数来表示有符号数字,正数和负数交错,这就是 zigzag 这个词的含义了。具体编码如图所示:
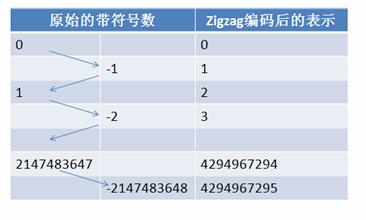
使用 zigzag 编码,绝对值小的数字,无论正负都可以采用较少的 byte 来表示,充分利用了 Varint 这种技术。
其他的数据类型,比如字符串等则采用类似数据库中的 varchar 的表示方法,即用一个 varint 表示长度,然后将其余部分紧跟在这个长度部分之后即可。
总之,Protocol Buffer的编码确费尽心机,效果当然也不错,特别是与常用的XML相比,包括解包的速度。
了解了一下Google Protocol Buffer,算是一些课外知识了。















 434
434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









