







本次爬取的是妙笔阁小说网仙侠系列中所有小说的信息,打开网页会看到如下图所示的小说列表。
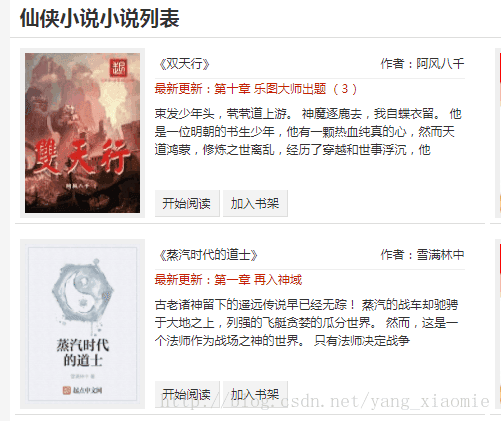
根据列表,选择爬取小说的书名、作者、最新更新、简介这四项信息。
在爬取之前,为了防止网站禁止爬取,需构造访问的请求头,模拟浏览器访问该网站。那么如何构建请求头,需要找到访问网站时的代理:
在想要爬取的页面按F12,然后点击NetWork,按F5刷新,随便点击进去一个即可,然后找到User-Agent
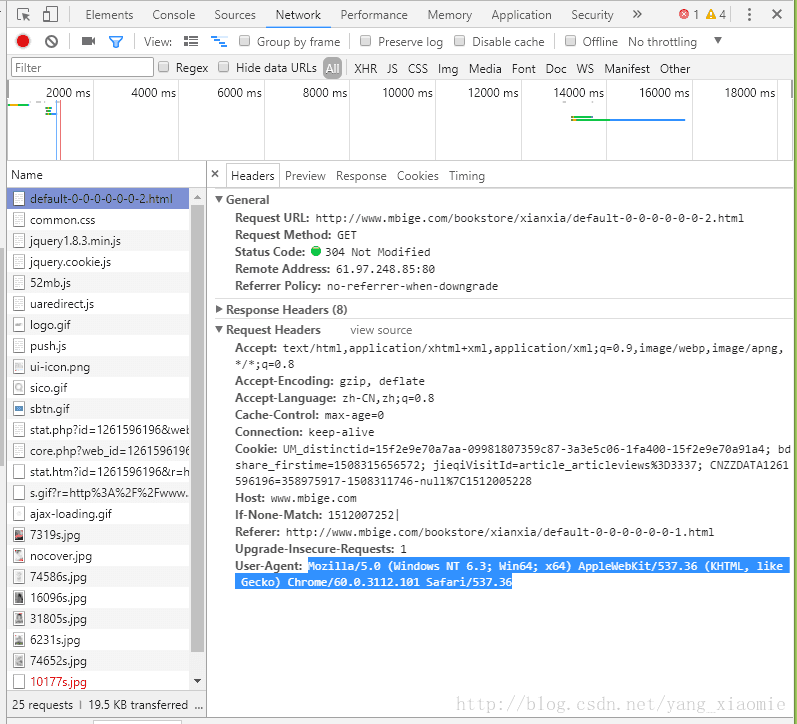
1.构建请求头:
user_agent = 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) \Chrome/60.0.3112.101 Safari/537.36'
headers = {'User-Agent':user_agent}2.利用request请求url,并将相应内容转换为html:
response = requests.get("http://www.mbige.com/bookstore/xianxia/default-0-0-0-0-0-0-1.html")
response.encoding = response.apparent_encoding
html = lxml.html.fromstring(response.text)3.利用Xpath解析html,并将解析的内容写入txt文件中:
with open("E:/xiaoshuo.txt",'a+',encoding = 'utf8') as f :
#通过对页面元素检查,发现html中每个小说都有一个列表块(alistbox), 小说的信息均在alistbox 标签下,
#所以首先获取所有小说的alistbox标签下的内容,存在divlst列表中
divlst = html.xpath('//div[@id="alistbox"]')
#对每个小说的alistbox进行解析,获取小说名(title)、作者(author)、最新更新(newest)、简介(intro)的信息
for i in divlst:
title = i.xpath('.//h2/a/text()')
author = i.xpath('.//div[@class="title"]/span/text()')
newest = i.xpath('.//li/a/text()')
intro = i.xpath('.//div[@class="intro"]/text()')
f.write(str(title)+" "+str(author)+'\n'+str(newest)+'\n'+str(intro)+'\n')4.完整代码(保存为txt格式):
import requests
import lxml.html
class myspider():
def __init__(self):
user_agent = 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'
self.headers = {'User-Agent':user_agent}
def gethtml(self,url):
try:
response = requests.get(url)
except:
response = None
else:
response.encoding = 'gb18030'
finally:
html = lxml.html.fromstring(response.text)
return html
def getpage(self,url):
with open("E:/xiaoshuo.txt",'a+',encoding = 'utf-8') as f :
html = self.gethtml(url)
divlst = html.xpath('//div[@id="alistbox"]')
for i in divlst:
title = ''.join(i.xpath('.//h2/a/text()'))
#''.join把元素从列表中抽取出来,例:['a']抽取出来为a
author = ''.join(i.xpath('.//div[@class="title"]/span/text()'))
newest = ''.join(i.xpath('.//li/a/text()'))
#对intro进行去除换行
intro = ''.join([x.strip('\n') for x in i.xpath('.//div[@class="intro"]/text()') if x])
f.write(str(title)+"\n"+str(author)+'\n'+str(newest)+'\n'+str(intro)+'\n'+'\n')
if __name__ == '__main__':
sp=myspider()
#仙侠系列小说列表共160页,通过观察发现每页的url的最后为当前页数,即从1递增到160
#所以通过循环得到替换url最后元素,得到每一页的url,逐一访问
url1='http://www.mbige.com/bookstore/xianxia/default-0-0-0-0-0-0-{0}.html'
for num in range(1,161):
url = url1.format(num)
sp.getpage(url)
print(str(num)+"page")5.得到的xiaoshuo.txt文件内容如下:
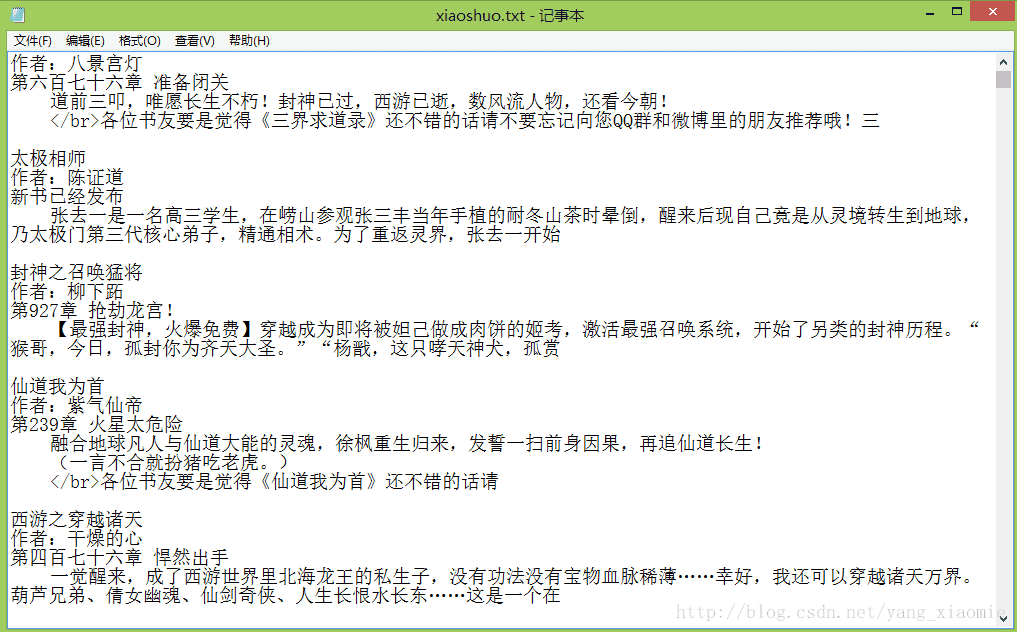
保存为csv格式只需在上述代码中增加几行代码
6.完整代码(保存为csv格式):
import requests
import lxml.html
#导入csv包
import csv
class myspider():
def __init__(self):
user_agent = 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'
self.headers = {'User-Agent':user_agent}
def gethtml(self,url):
try:
response = requests.get(url)
except:
response = None
else:
response.encoding = 'gb18030'
finally:
html = lxml.html.fromstring(response.text)
return html
def getpage(self,url):
with open("E:/xiaoshuo.csv",'a+',encoding = 'utf-8') as f :
f1 = csv.writer(f)
#创建表格中的列名
f1.writerow(['书名','作者','最新更新','简介'])
html = self.gethtml(url)
divlst = html.xpath('//div[@id="alistbox"]')
for i in divlst:
#''.join把元素从列表中抽取出来,例:['a']抽取出来为a
title = ''.join(i.xpath('.//h2/a/text()'))
author = ''.join(i.xpath('.//div[@class="title"]/span/text()'))
newest = ''.join(i.xpath('.//li/a/text()'))
#对intro进行去除换行
intro = [x.strip('\n') for x in i.xpath('.//div[@class="intro"]/text()') if x]
f1.writerow([str(title),str(author),str(newest),str(intro)])
if __name__ == '__main__':
sp=myspider()
#仙侠系列小说列表共160页,通过观察发现每页的url的最后为当前页数,即从1递增到160
#所以通过循环得到替换url最后元素,得到每一页的url,逐一访问
url1='http://www.mbige.com/bookstore/xianxia/default-0-0-0-0-0-0-{0}.html'
for num in range(1,161):
url = url1.format(num)
sp.getpage(url)
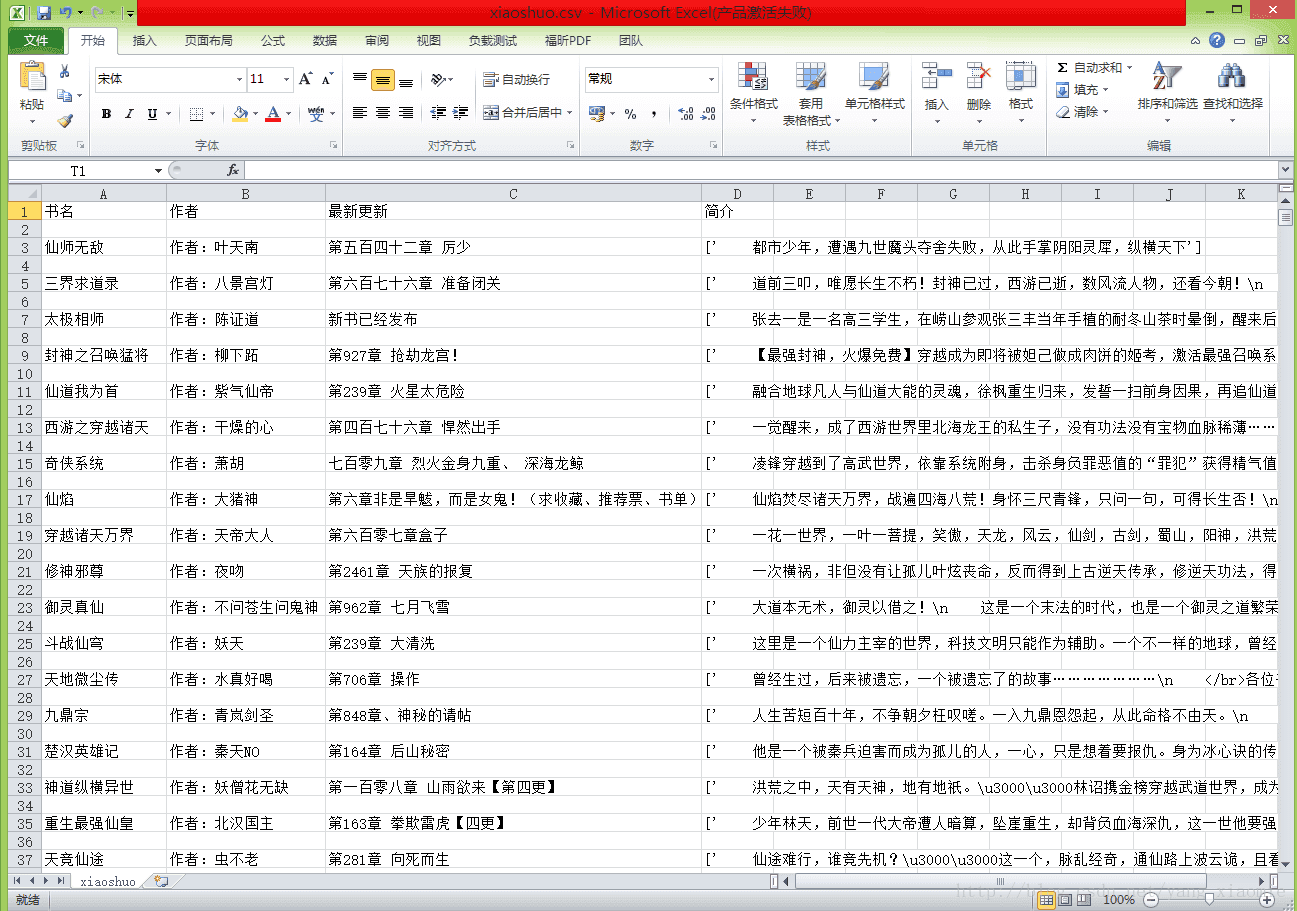
print(str(num)+"page")7.得到的xiaoshuo.csv文件内容如下:
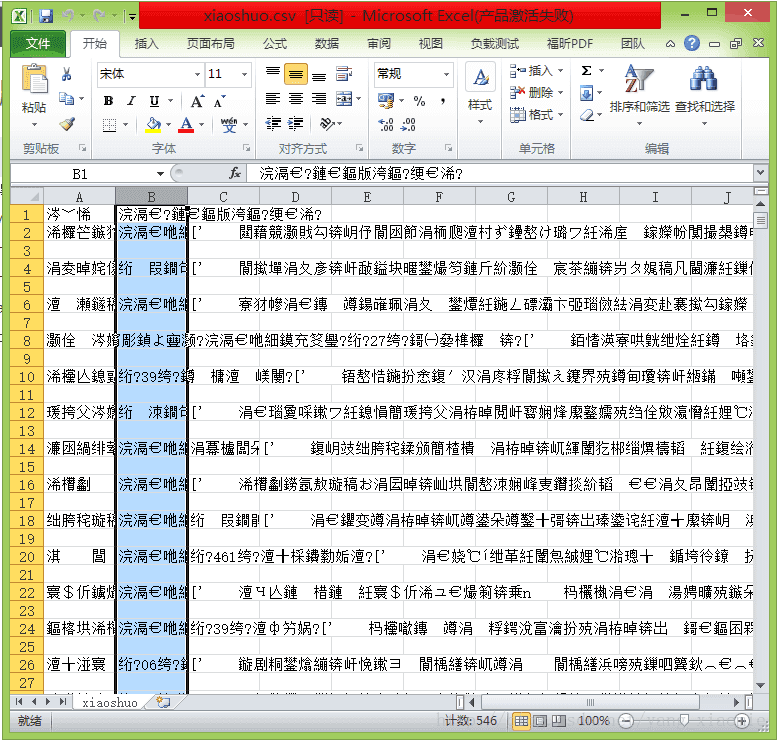
开心以为终于爬取完成,一个完美滴csv将呈现眼前,打开文件一脸懵逼,全是乱码,但是编码应该不会有问题的啊,毕竟保存txt文件中并无乱码问题,所以应该是excel编码问题。然后使用Notepad++打开csv文件,修改编码后,再次打开文件就没有乱码啦:














 256
256











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









