







逻辑回归作为分类算法的一种,在互联网领域中的预测、判别中应用的非常广泛,像广告投放中的点击率预估,推荐算法中的模型融合等等。本文简要介绍逻辑回归的算法,以及在MLlib中的实现解析。
逻辑回归其实是一个分类问题,此类问题的模型训练,基本上分3步骤,
第一步要寻找假设预测函数h,构造的假设函数为
在线性回归的函数基础上,加上一个Sigmoid函数进行Norm,把函数值输出在0到1的范围内,函数的值有特殊的含义,它表示结果取1的概率,因此对于输入x分类结果为类别1和类别0的概率分别为:
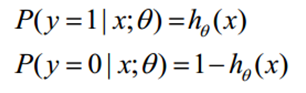
第二步要构造损失函数J,基于最大似然估计推导出,
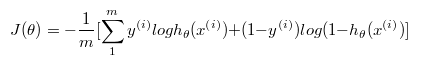
其中:
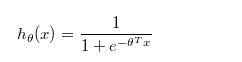
第三步求得使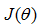 最小值时的参数
最小值时的参数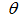 ,解决这个问题的做法是随机给定一个初始值,通过迭代,在每次迭代中计算损失函数的下降方向并更新,直到目标函数收敛稳定在最小点。
,解决这个问题的做法是随机给定一个初始值,通过迭代,在每次迭代中计算损失函数的下降方向并更新,直到目标函数收敛稳定在最小点。
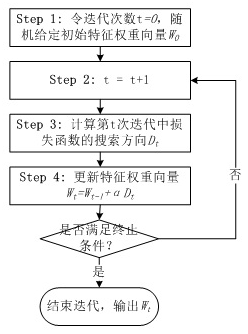
迭代优化算法就是损失函数的下降方向的计算,有梯度下降、牛顿迭代算法、拟牛顿迭代算法(BFGS算法和L-BFGS算法)
下面对这些优化算法做简单介绍。
(1)梯度下降
对损失函数求偏导,更新过程可以写成:
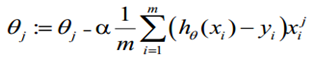
基于导数,基于梯度的方法优化方法有一个问题,在两次函数中,函数等高线是一个非常扁的椭圆,收敛速度是很慢的,比如在模型训练中有大量的特征,他们的物理意义有时候是不明确的,无法对他们进行归一化处理操作。
梯度下降每次更新都需要遍历所有data,当数据量太大或者一次无法获取全部数据时,这种方法并不可行。
针对梯度下降每一步都是收敛速度慢的问题,引进随机梯度下降,在每一次计算之后便更新参数,而不需要首先将所有的训练集求和,在梯度下降算法还没有完成一次迭代时,随机梯度下降算法便已经走出了很远。但是这样的算法存 在的问题是,不是每一步都是朝着“正确”的方向
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









